
How to Set Up the Vector Database for Embedding Storage
How to Set Up the Vector Database for Embedding Storage 관련

A vector database is a special type of database that stores embeddings and allows you to query and retrieve relevant information. There are numerous vector databases available, but for this project, you will use ChromaDB, an open-source option that integrates with the R environment through the rchroma library.
ChromaDB runs locally in a Docker container. Just make sure you have Docker installed and running on your device.
Then load the rchroma library and run your ChromaDB instance:
# load rchroma library
library(rchroma)
# run ChromaDB instance.
chroma_docker_run()
If it was successful, you should see this in the console:
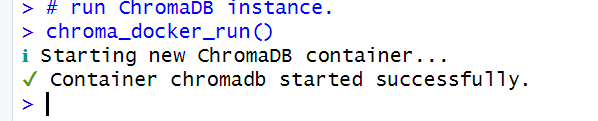
Next, connect to a local ChromaDB instance and check the connection:
# Connect to a local ChromaDB instance
client <- chroma_connect()
# Check the connection
heartbeat(client)
version(client)
Now you’ll need to create a collection and confirm that it was created. Collections in ChromaDB function similarly to tables in conventional databases.
# Create a new collection
create_collection(client, "recipes_collection")
# List all collections
list_collections(client)
Now, add embeddings to the collection. To add embeddings to the recipes_collection, use the add_documents function.
# Add documents to the collection
add_documents(
client,
"recipes_collection",
documents = recipe_sentence_embeddings$recipe,
ids = recipe_sentence_embeddings$recipe_id,
embeddings = recipe_sentence_embeddings$recipe_vec_embeddings
)
The add_documents() function is used to add recipe data to the recipes_collection. Here's a breakdown of its arguments and how the corresponding data is accessed:
documents: This argument represents the recipe text. It is sourced from therecipecolumn of therecipe_sentence_embeddingsdataframe.ids: This is the unique identifier for each recipe. It is extracted from therecipe_idcolumn of the same dataframe.embeddings: This contains the sentence embeddings, which were previously generated for each recipe. These embeddings are accessed from therecipe_vec_embeddingscolumn of the dataframe.
All three arguments—documents, ids, and embeddings—are obtained by subsetting their respective columns from the recipe_sentence_embeddings dataframe.