
5 Ways To Check For Duplicates In Collections, With Benchmarks
5 Ways To Check For Duplicates In Collections, With Benchmarks 관련


In this week's newsletter, we will take a look at five different ways to check if a collection contains duplicates.
I'm going to explain the idea behind each algorithm, discuss the algorithm complexity (Big O Notation), and at the end, we'll look at some benchmark results.
The five approaches for finding a duplicate will use the:
foreachloop- LINQ
Anymethod - LINQ
Allmethod - LINQ
Distinctmethod - LINQ
ToHashSetmethod
Let's see how we can implement each approach!
Check For Duplicates With ForEach Loop
The first implementation will use the foreach loop and the HashSet data structure.
Here's the code for the ContainsDuplicates method:
public bool ContainsDuplicates<T>(IEnumerable<T> enumerable)
{
HashSet<T> set = new();
foreach(var element in enumerable)
{
if (!set.Add(element))
{
return true;
}
}
return false;
}
The idea is simple:
- Loop through the collection
- Add each element to the
HashSet - When
HashSet.Addreturns false we found a duplicate - If we loop through the entire collection there are no duplicates
In terms of algorithm complexity, this would be or linear complexity. sThis is because there's only one iteration through the collection.
Adding an element to a HashSet is a constant operation - . So it doesn't affect the overall complexity.
Check For Duplicates With LINQ Any
We'll combine the idea from the previous implementation of using the HashSet and pair it with the LINQ Any method to iterate over the collection.
Here's the implementation for the ContainsDuplicates method:
public bool ContainsDuplicates<T>(IEnumerable<T> enumerable)
{
HashSet<T> set = new();
return enumerable.Any(element => !set.Add(element));
}
You can see this implementation is significantly shorter. But it works the same as the one with the foreach loop.
If any element in the collection satisfies the specified expression, Any will short-circuit and return true. Otherwise, it will iterate over the entire collection and return false.
We're still looking at linear complexity here, .
Check For Duplicates With LINQ All
For our third implementation, we will use the opposite of the LINQ Any method - the LINQ All method.
Here's the implementation with LINQ All:
public bool ContainsDuplicates<T>(IEnumerable<T> enumerable)
{
HashSet<T> set = new();
return !enumerable.All(set.Add);
}
The idea here is a little different than in the previous implementation.
All will return true if all elements in a collection satisfy the specified expression.
If at least one element doesn't satisfy the condition - in our case when a duplicate is found - it will short-circuit and return false.
This is still linear complexity, .
Check For Duplicates With LINQ Distinct
So far, we've seen a few implementations using the HashSet data structure. Now let's consider a different approach.
We can use the LINQ Distinct method to check for duplicates.
Here's the code for the ContainsDuplicates method:
public bool ContainsDuplicates<T>(IEnumerable<T> enumerable)
{
return enumerable.Distinct().Count() != enumerable.Count();
}
The idea is first find the Distinct elements and Count them, and then compare that to the number of all elements.
If the number of distinct elements is not equal to the number of all elements, we have a duplicate value.
In terms of algorithm complexity, this is still linear complexity.
But we have at least two iterations through the collection or three in the worst-case scenario.
We have one iteration for Distinct and one more iteration for the call to Count right after that. The last call to Count can return in constant time, if the collection is an array or List.
Check For Duplicates With LINQ ToHashSet
For the last implementation we will use the LINQ ToHashSet method.
It takes a collection and creates a HashSet instance from it.
Here's what the ContainsDuplicates implementation looks like:
public bool ContainsDuplicates<T>(IEnumerable<T> enumerable)
{
return enumerable.ToHashSet().Count != enumerable.Count();
}
We compare the number of elements in the HashSet to the number of elements in the collection.
If they are different, we have a duplicate value.
This is also linear complexity, .
Benchmark Results
Now that we've seen our implementations let's put them to the test.
I ran the benchmark for collections of varying sizes:
- 100
- 1,000
- 10,000
Each collection contains exactly one duplicate value located somewhere around the middle of the collection.
Here are the results:
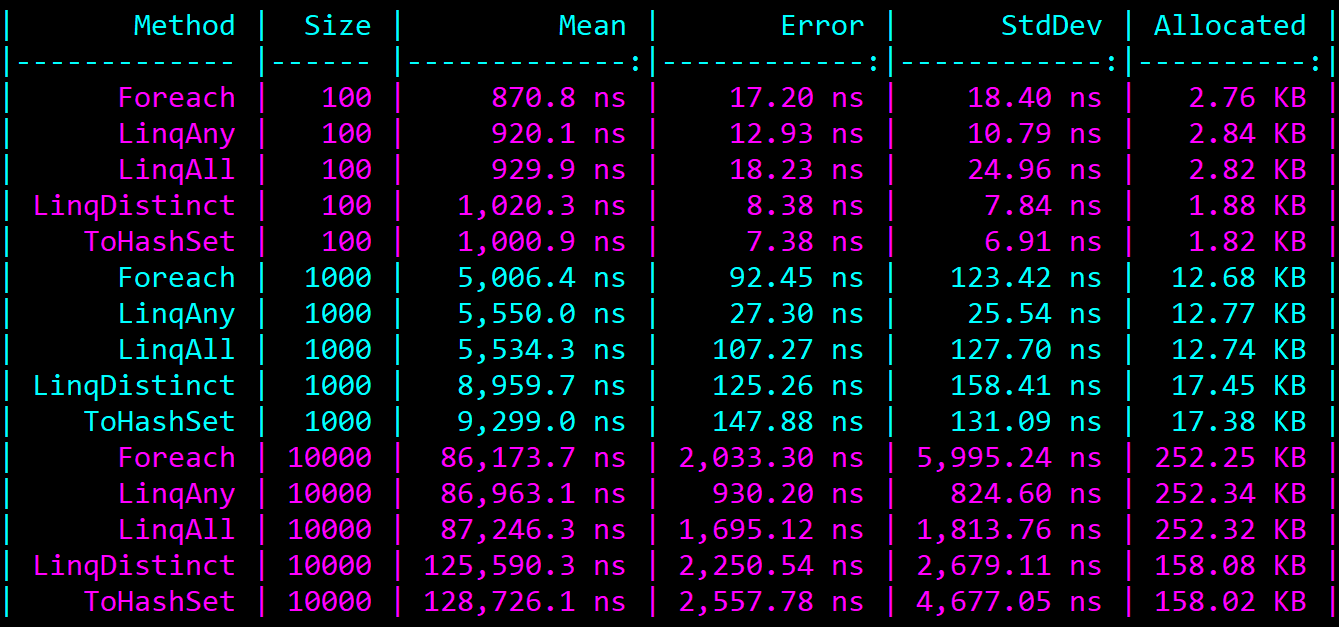
The approach using the foreach loop comes out as the clear winner in terms of performance.
However, I would lean towards using the implementations with LINQ Any or All because of their simplicity.
You can find the source code for the benchmark (m-jovanovic/find-duplicates-benchmark) on my GitHub. Feel free to submit a PR with a faster implementation if you can think of one.