
Using multiprocessing.Queue for Interprocess Communication (IPC)
Using multiprocessing.Queue for Interprocess Communication (IPC) 관련

Using multiprocessing.Queue for Interprocess Communication (IPC)
So far, you’ve looked into queues that can only help in scenarios with strictly I/O-bound tasks, whose progress doesn’t depend on the available computational power. On the other hand, the traditional approach to running CPU-bound tasks on multiple CPU cores in parallel with Python takes advantage of cloning the interpreter process. Your operating system provides the interprocess communication (IPC) layer for sharing data across these processes.
For example, you can start a new Python process with multiprocessing or use a pool of such processes from the concurrent.futures module. Both modules are carefully designed to make the switch from threads to processes as smooth as possible, which makes parallelizing your existing code rather straightforward. In some cases, it’s just a matter of replacing an import statement because the rest of the code follows a standard interface.
You’ll only find the FIFO queue in the multiprocessing module, which comes in three variants:
multiprocessing.Queuemultiprocessing.SimpleQueuemultiprocessing.JoinableQueue
They’re all modeled after the thread-based queue.Queue but differ in the level of completeness. The JoinableQueue extends the multiprocessing.Queue class by adding .task_done() and .join() methods, allowing you to wait until all enqueued tasks have been processed. If you don’t need this feature, then use multiprocessing.Queue instead. SimpleQueue is a separate, significantly streamlined class that only has .get(), .put(), and .empty() methods.
Note: Sharing a resource, such as a queue, between operating system processes is much more expensive and limited than sharing between threads. Unlike threads, processes don’t share a common memory region, so data must be marshaled and unmarshaled at both ends every time you pass a message from one process to another.
Moreover, Python uses the pickle module for data serialization, which doesn’t handle every data type and is relatively slow and insecure. As a result of that, you should only consider multiple processes when the performance improvements by running your code in parallel can offset the additional data serialization and bootstrapping overhead.
To see a hands-on example of multiprocessing.Queue, you’ll simulate a computationally intensive task by trying to reverse an MD5 hash value of a short text using the brute-force approach. While there are better ways to solve this problem, both algorithmically and programmatically, running more than one process in parallel will let you noticeably reduce the processing time.
Reversing an MD5 Hash on a Single Thread
Before parallelizing your computation, you’ll focus on implementing a single-threaded version of the algorithm and measuring the execution time against some test input. Create a new Python module named multiprocess_queue and place the following code in it:
Python
`1# multiprocess_queue.py 2 3import time 4from hashlib import md5 5from itertools import product 6from string import ascii_lowercase 7 8def reverse_md5(hash_value, alphabet=ascii_lowercase, max_length=6): 9 for length in range(1, max_length + 1): 10 for combination in product(alphabet, repeat=length): 11 text_bytes = "".join(combination).encode("utf-8") 12 hashed = md5(text_bytes).hexdigest() 13 if hashed == hash_value: 14 return text_bytes.decode("utf-8") 15 16def main(): 17 t1 = time.perf_counter() 18 text = reverse_md5("a9d1cbf71942327e98b40cf5ef38a960") 19 print(f"{text} (found in {time.perf_counter() - t1:.1f}s)") 20 21if name == "main": 22 main()
**Lines 8 to 14** define a function that’ll try to reverse an MD5 hash value provided as the first argument. By default, the function only considers text comprising up to six lowercase [ASCII](https://en.wikipedia.org/wiki/ASCII) letters. You can change the alphabet and the maximum length of the text to guess by providing two other optional arguments.
For every possible combination of letters in the alphabet with the given length, `reverse_md5()` calculates a hash value and compares it against the input. If there’s a match, then it stops and returns the guessed text.
**Note:** Nowadays, MD5 is considered cryptographically unsafe because you can calculate such digests rapidly. Yet, six characters pulled from twenty-six ASCII letters gives a total of 308,915,776 distinct combinations, which is plenty for a Python program.
**Lines 16 to 19** call the function with a sample MD5 hash value passed as an argument and measure its execution time using a [Python timer](https://realpython.com/python-timer/). On a veteran desktop computer, it can take a few seconds to find a combination that hashes to the specified input:
```sh
$ python multiprocess_queue.py
queue (found in 6.9s)
As you can see, the word queue is the answer because it has an MD5 digest that matches your hard-coded hash value on line 18. Seven seconds isn’t terrible, but you can probably do better by taking advantage of your idle CPU cores, which are eager to do some work for you. To leverage their potential, you must chunk the data and distribute it to your worker processes.
Distributing Workload Evenly in Chunks
You want to narrow down the search space in each worker by dividing the whole set of letter combinations into a few smaller disjoint subsets. To ensure that workers don’t waste time doing work that’s already been done by another worker, the sets can’t have any overlap. While you don’t know the size of an individual chunk, you can provide a number of chunks equal to the number of CPU cores.
To calculate indices of the subsequent chunks, use the helper function below:
# multiprocess_queue.py
# ...
def chunk_indices(length, num_chunks):
start = 0
while num_chunks > 0:
num_chunks = min(num_chunks, length)
chunk_size = round(length / num_chunks)
yield start, (start := start + chunk_size)
length -= chunk_size
num_chunks -= 1
It yields tuples consisting of the first index of the current chunk and its last index increased by one, making the tuple convenient to use as input to the built-in range() function. Because of rounding of the subsequent chunk lengths, those with varying lengths end up nicely interleaved:
>>> from multiprocess_queue import chunk_indices
>>> for start, stop in chunk_indices(20, 6):
... print(len(r := range(start, stop)), r)
...
3 range(0, 3)
3 range(3, 6)
4 range(6, 10) 3 range(10, 13)
4 range(13, 17) 3 range(17, 20)
For example, a total length of twenty divided into six chunks yields indices that alternate between three and four elements.
To minimize the cost of data serialization between your processes, each worker will produce its own chunk of letter combinations based on the range of indices specified in a dequeued job object. You’ll want to find a letter combination or an n-tuple of m-set for a particular index. To make your life easier, you can encapsulate the formula for the combination in a new class:
# multiprocess_queue.py
# ...
class Combinations:
def __init__(self, alphabet, length):
self.alphabet = alphabet
self.length = length
def __len__(self):
return len(self.alphabet) ** self.length
def __getitem__(self, index):
if index >= len(self):
raise IndexError
return "".join(
self.alphabet[
(index // len(self.alphabet) ** i) % len(self.alphabet)
]
for i in reversed(range(self.length))
)
This custom data type represents a collection of alphabet letter combinations with a given length. Thanks to the two special methods and raising the IndexError exception when all combinations are exhausted, you can iterate over instances of the Combinations class using a loop.
The formula above determines the character at a given position in a combination specified by an index, much like an odometer works in a car or a positional system in math. The letters in the rightmost position change most frequently, while letters change less often the further left they are.
You can now update your MD5-reversing function to use the new class and remove the itertools.product import statement:
# multiprocess_queue.py
# ...
def reverse_md5(hash_value, alphabet=ascii_lowercase, max_length=6):
for length in range(1, max_length + 1):
for combination in Combinations(alphabet, length): text_bytes = "".join(combination).encode("utf-8")
hashed = md5(text_bytes).hexdigest()
if hashed == hash_value:
return text_bytes.decode("utf-8")
# ...
Unfortunately, replacing a built-in function implemented in C with a pure-Python one and doing some calculations in Python make the code an order of magnitude slower:
$ python multiprocess_queue.py
queue (found in 38.8s)
There are a few optimizations that you could make to gain a few seconds. For example, you might implement .__iter__() in your Combinations class to avoid making the if statement or raising an exception. You could also store the alphabet’s length as an instance attribute. However, these optimizations aren’t important for the sake of the example.
Next up, you’ll create the worker process, job data type, and two separate queues to communicate between the main process and its children.
Communicating in Full-Duplex Mode
Each worker process will have a reference to the input queue with jobs to consume and a reference to the output queue for the prospective solution. These references enable simultaneous two-way communication between workers and the main process, known as full-duplex communication. To define a worker process, you extend the Process class, which provides the familiar .run() method, just like a thread:
# multiprocess_queue.py
import multiprocessing
# ...
class Worker(multiprocessing.Process):
def __init__(self, queue_in, queue_out, hash_value):
super().__init__(daemon=True)
self.queue_in = queue_in
self.queue_out = queue_out
self.hash_value = hash_value
def run(self):
while True:
job = self.queue_in.get()
if plaintext := job(self.hash_value):
self.queue_out.put(plaintext)
break
# ...
Later, the main process will periodically check whether one of the workers has placed a reversed MD5 text on the output queue and terminate the program early in such a case. The workers are daemons, so they won’t hold up the main process. Also notice that workers store the input hash value to reverse.
Add a Job class that Python will serialize and place on the input queue for worker processes to consume:
# multiprocess_queue.py
from dataclasses import dataclass
# ...
@dataclass(frozen=True)
class Job:
combinations: Combinations
start_index: int
stop_index: int
def __call__(self, hash_value):
for index in range(self.start_index, self.stop_index):
text_bytes = self.combinations[index].encode("utf-8")
hashed = md5(text_bytes).hexdigest()
if hashed == hash_value:
return text_bytes.decode("utf-8")
By implementing the special method .__call__() in a job, you make objects of your class callable. Thanks to that, the workers can call these jobs just like regular functions when they receive them. The method’s body is similar to but slightly different from reverse_md5(), which you can remove now because you won’t need it anymore.
Finally, create both queues and populate the input queue with jobs before starting your worker processes:
# multiprocess_queue.py
import argparse
# ...
def main(args):
queue_in = multiprocessing.Queue()
queue_out = multiprocessing.Queue()
workers = [
Worker(queue_in, queue_out, args.hash_value)
for _ in range(args.num_workers)
]
for worker in workers:
worker.start()
for text_length in range(1, args.max_length + 1):
combinations = Combinations(ascii_lowercase, text_length)
for indices in chunk_indices(len(combinations), len(workers)):
queue_in.put(Job(combinations, *indices))
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("hash_value")
parser.add_argument("-m", "--max-length", type=int, default=6)
parser.add_argument(
"-w",
"--num-workers",
type=int,
default=multiprocessing.cpu_count(),
)
return parser.parse_args()
# ...
if __name__ == "__main__":
main(parse_args())
As in the earlier examples, you parse the command-line arguments using the argparse module. The only mandatory argument for your script is the hash value to reverse, such as:
(venv) $ python multiprocess_queue.py a9d1cbf71942327e98b40cf5ef38a960
You can optionally specify the number of worker processes using the --num-workers command-line parameter, which defaults to the number of your CPU cores. There’s usually no benefit in cranking up the number of workers above the number of physical or logical processing units in hardware because of the additional cost of context switching, which starts to add up.
On the other hand, context switching becomes almost negligible in I/O-bound tasks, where you might end up having thousands of worker threads or coroutines. Processes are a different story because they’re much more expensive to create. Even if you front-load this cost using a process pool, there are certain limits.
At this point, your workers engage in two-way communication with the main process through the input and output queues. However, the program exits abruptly right after starting because the main process ends without waiting for its daemon children to finish processing their jobs. Now is the time to periodically poll the output queue for a potential solution and break out of the loop when you find one:
Python
`1# multiprocess_queue.py 2 3import queue 4import time 5 6# ... 7 8def main(args): 9 t1 = time.perf_counter() 10 11 queue_in = multiprocessing.Queue() 12 queue_out = multiprocessing.Queue() 13 14 workers = [ 15 Worker(queue_in, queue_out, args.hash_value) 16 for _ in range(args.num_workers) 17 ] 18 19 for worker in workers: 20 worker.start() 21 22 for text_length in range(1, args.max_length + 1): 23 combinations = Combinations(ascii_lowercase, text_length) 24 for indices in chunk_indices(len(combinations), len(workers)): 25 queue_in.put(Job(combinations, *indices)) 26 27 while any(worker.is_alive() for worker in workers): 28 try: 29 solution = queue_out.get(timeout=0.1) 30 if solution: 31 t2 = time.perf_counter() 32 print(f"{solution} (found in {t2 - t1:.1f}s)") 33 break 34 except queue.Empty: 35 pass 36 else: 37 print("Unable to find a solution") 38 39# ...
You set the optional `timeout` parameter on the queue’s `.get()` method to avoid blocking and allow the while-loop to run its condition. When a solution is found, you dequeue it from the output queue, print the matched text on the standard output along with the estimated execution time, and break out of the loop. Note that `multiprocessing.Queue` raises exceptions defined in the `queue` module, which you might need to import.
However, when there’s no matching solution, the loop will never stop because your workers are still alive, waiting for more jobs to process even after having consumed all of them. They’re stuck on the `queue_in.get()` call, which is blocking. You’ll fix that in the upcoming section.
### Killing a Worker With the Poison Pill
Because the number of jobs to consume is known up front, you can tell the workers to shut down gracefully after draining the queue. A typical pattern to request a thread or process stop working is by putting a special [sentinel value](https://en.wikipedia.org/wiki/Sentinel_value) at the end of the queue. Whenever a worker finds that sentinel, it’ll do the necessary cleanup and escape the infinite loop. Such a sentinel is known as the **poison pill** because it kills the worker.
Choosing the value for a sentinel can be tricky, especially with the `multiprocessing` module because of how it handles the global namespace. Check out the [programming guidelines](https://docs.python.org/3/library/multiprocessing.html#programming-guidelines) in the official documentation for more details. It’s probably safest to stick to a predefined value such as `None`, which has a known identity everywhere:
```py
# multiprocess_queue.py
POISON_PILL = None
# ...
If you used a custom object() instance defined as a global variable, then each of your worker processes would have its own copy of that object with a unique identity. A sentinel object enqueued by one worker would be deserialized into an entirely new instance in another worker, having a different identity than its global variable. Therefore, you wouldn’t be able to detect a poison pill in the queue.
Another nuance to watch out for is taking care to put the poison pill back in the source queue after consuming it:
# multiprocess_queue.py
# ...
class Worker(multiprocessing.Process):
def __init__(self, queue_in, queue_out, hash_value):
super().__init__(daemon=True)
self.queue_in = queue_in
self.queue_out = queue_out
self.hash_value = hash_value
def run(self):
while True:
job = self.queue_in.get()
if job is POISON_PILL: self.queue_in.put(POISON_PILL) break if plaintext := job(self.hash_value):
self.queue_out.put(plaintext)
break
# ...
This will give other workers a chance to consume the poison pill. Alternatively, if you know the exact number of your workers, then you can enqueue that many poison pills, one for each of them. After consuming and returning the sentinel to the queue, a worker breaks out of the infinite loop, ending its life.
Finally, don’t forget to add the poison pill as the last element in the input queue:
# multiprocess_queue.py
# ...
def main(args):
t1 = time.perf_counter()
queue_in = multiprocessing.Queue()
queue_out = multiprocessing.Queue()
workers = [
Worker(queue_in, queue_out, args.hash_value)
for _ in range(args.num_workers)
]
for worker in workers:
worker.start()
for text_length in range(1, args.max_length + 1):
combinations = Combinations(ascii_lowercase, text_length)
for indices in chunk_indices(len(combinations), len(workers)):
queue_in.put(Job(combinations, *indices))
queue_in.put(POISON_PILL)
while any(worker.is_alive() for worker in workers):
try:
solution = queue_out.get(timeout=0.1)
t2 = time.perf_counter()
if solution:
print(f"{solution} (found in {t2 - t1:.1f}s)")
break
except queue.Empty:
pass
else:
print("Unable to find a solution")
# ...
Now, your script is complete and can handle finding a matching text as well as facing situations when the MD5 hash value can’t be reversed. In the next section, you’ll run a few benchmarks to see whether this whole exercise was worth the effort.
Analyzing the Performance of Parallel Execution
When you compare the speed of execution of your original single-threaded version and the multiprocessing one, then you might get disappointed. While you took care to minimize the data serialization cost, rewriting bits of code to pure Python was the real bottleneck.
What’s even more surprising is that the speed seems to vary with changing input hash values as well as the number of worker processes:
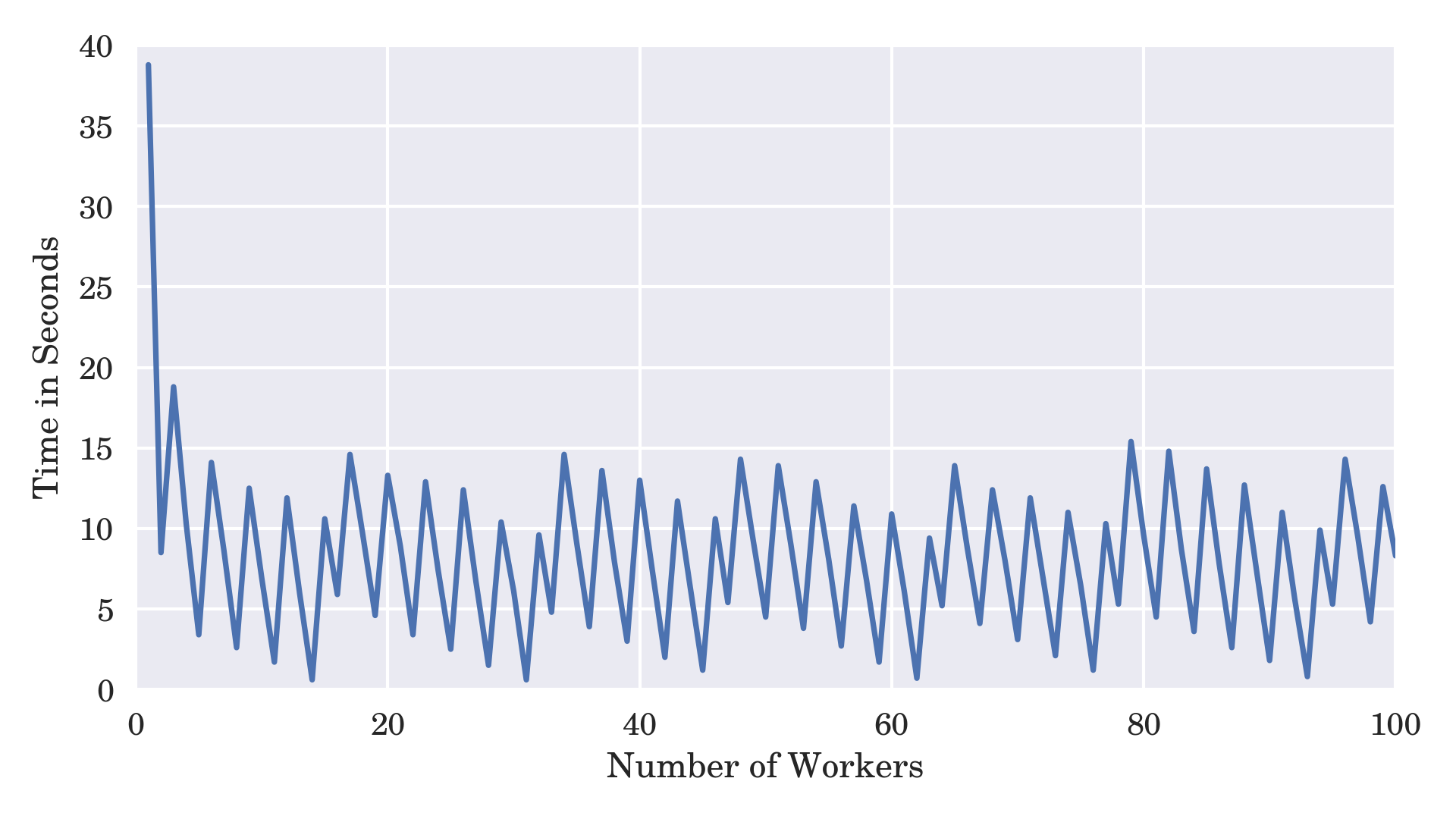
Number of Worker Processes vs the Execution Time
You would think that increasing the number of workers would decrease the overall computation time, and it does to a certain extent. There’s a huge drop from the single worker to multiple workers. However, the execution times periodically jump back and forth somewhat as you add more workers. There are a few factors at play here.
Primarily, the lucky worker that gets assigned a chunk containing your solution will run longer if the matching combination is located near the end of that chunk. Depending on the division points in your search space, which stem from the number of workers, you’ll get a different distance to the solution in a chunk. Secondly, the more workers you create, the bigger the impact context switching starts to have, even if the distance remains the same.
On the other hand, if all of your workers always had the same amount of work to do, then you’d observe a roughly linear trend without the sudden jumps. As you can see, parallelizing the execution of Python code isn’t always a straightforward process. That said, with a little bit of patience and persistence, you can most definitely optimize those few bottlenecks. For example, you could:
- Figure out a more clever formula
- Trade memory for speed by caching and pre-calculating intermediate results
- Inline function calls and other expensive constructs
- Find a third-party C library with Python bindings
- Write a Python C extension module or use ctypes or Cython
- Bring just-in-time (JIT) compilation tools for Python
- Switch to an alternative Python interpreter like PyPy
At this point, you’ve covered all queue types available in the Python standard library, including synchronized thread-safe queues, asynchronous queues, and a FIFO queue for process-based parallelism. In the next section, you’ll take a brief look at a few third-party libraries that’ll let you integrate with standalone message queue brokers.