
캐시 성능 향상기 (Improving Cache Speed at Scale)
캐시 성능 향상기 (Improving Cache Speed at Scale) 관련


Improving Cache Speed at Scale
안녕하세요! 데이터운영팀 김가림입니다.🙇🏻♀️ 올해 레디스 컨퍼런스는 코로나로 인해 온라인으로 진행되었습니다. 오늘은 그 중 제가 가장 흥미롭게 들었던 세션의 내용을 공유해보려고 합니다. 원 제목은 Improving Cache Speed at Scale 이며, 세션 영상은 유튜브에서 확인하실 수 있습니다.
Cache Stampede
레디스를 캐시로 사용할 때 데이터의 갱신을 위해 대부분의 서비스에서는 키에 대해 Expire time(TTL)을 설정합니다. AWS는 ElastiCache의 캐싱 전략 문서에서 데이터를 최신 상태로 유지함과 동시에 복잡성을 줄이기 위해 TTL을 추가할 것을 권장하고 있습니다.
하지만 대규모 트래픽 환경에서 이 TTL값은 예상치 못한 문제를 발생시킬 수 있습니다.
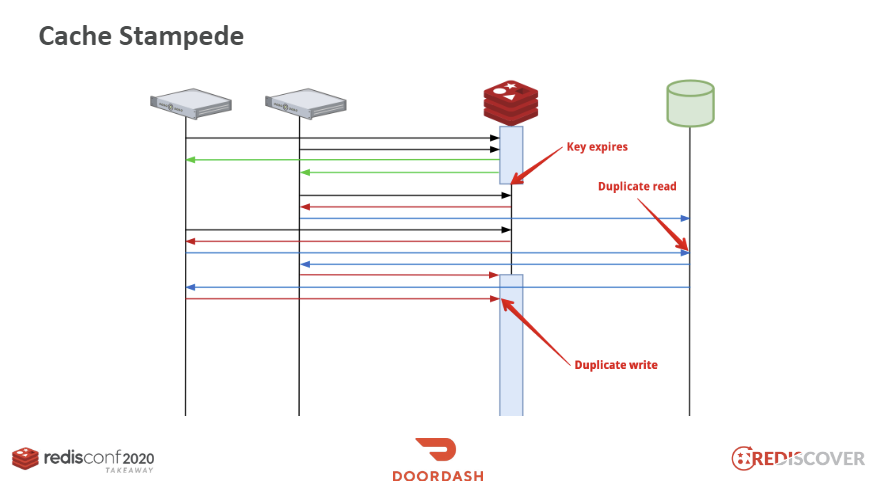
이 구조에서 레디스는 캐시로, DB 앞단에서 분산된 서버들의 요청을 받고 있습니다. 키가 만료되는 시점을 생각해볼까요? read-thorugh 구조에서 레디스에 데이터가 없을 때 서버들은 직접 DB에 가서 데이터를 읽어와 레디스에 저장합니다. 키가 만료되는 순간 많은 서버에서 이 키를 참조하는 시점이 겹치게 됩니다. 모든 서버들이 DB에 가서 데이터를 질의하는 duplicate read와 그 값을 반복적으로 레디스에 write하는 duplicate write가 발생하게 됩니다.
- 초록색: 정상적인 응답
- 빨간색: 레디스 Key miss
- 파란색: 데이터베이스에 질의
PER(Probablistic Early Recomputation)

이 현상을 해결하기 위해 PER(Probablistic Early Recomputation) 알고리즘을 도입할 수 있습니다. 이 알고리즘은 키의 TTL이 실제로 만료되기 전에 일정 확률로 캐시를 갱신하는 방법입니다. 데이터베이스에서 키가 완전히 만료되기 전에 데이터를 먼저 읽어오게 함으로써 Cache Stampede 현상을 막을 수 있습니다.
def fetch_aot(key, expiry_gap_ms):
ttl_ms = redis.pttl(key) # pttl은 millisecond 단위
if ttl_ms - (random() * expiry_gap_ms) > 0:
return redis.get(key)
return None
# Usage
fetch_aot('foo', 2000)
이 방식은 원래 VLDB라는 국제 학술대회에서 발표된 방법이며, 인터넷에 관련 논문이 공개되어 있습니다. 왜 이 확률분포가 사용되는지, beta값은 어떻게 정해야 하는지 등의 내용도 흥미로우니 관심있으신 분들은 논문을 읽어보시면 좋을 것 같습니다.
Debouncing
We took inspiration from frontend world (debounce) and exploited promises(deferred)
혹은, Cache Stampede 문제를 해결하기 위해서 프론트엔드-월드👑 에서 디바운싱이라는 아이디어를 채용해 올 수 있습니다.
❗ 디바운싱은 단위시간 내에서 호출되는 마지막 함수만 호출하는 방법입니다.
인터벌이 100ms라면 100ms동안의 모든 이벤트는 무시되고, 마지막 이벤트만 동작하는 방법입니다. (출처: FE개발랩 한정)

이 아이디어를 도입하면 어플리케이션에서 특정 키 miss가 발생해도 바로 DB에 질의하지 않습니다. 이 키 ID에 대해 debouncer를 생성해서, 첫번째 reader가 이 함수를 반환할 때까지 다른 reader들은 기다립니다. 이 디바운서의 코드는 아래와 같고, 시뮬레이터 링크에서 어떤 식으로 동작하는지 확인하실 수 있습니다.
const debouncer = new Debouncer();
async function menuItemLoader(key) {
//Read from Redis/DB
}
const menu = await debouncer.debounce(
'menu-${id}', menuItemLoader
);
class Debouncer {
construnctor() {
this.pendingBoard = {};
}
async debounce(id, callback) {
if(this.pendingBoard(id) !== undefined) {
return await this.pendingBorad(id);
}
this.pendingBoard(id) = callback(id);
try {
return await this.pendingBoard(id);
} finally {
delete this.pendingBoard(id);
}
}
}
Cache Stampede 현상이 발생했을 때의 Key Miss 그래프는 위처럼 Spiky nature 합니다. (👀뭔가가 expire 되어서 everybody rushes into read 했나봐!) 반면에 아래 그래프는 트래픽이 훨씬 감소했음을 알 수 있습니다. 쓸데없는 set을 줄이니 전체적인 round trip time이 감소됐고, latency도 줄어듭니다. 실제로 LINE에서 성능테스트를 했을 때, 이 알고리즘을 도입하면 약 세배 정도의 응답 시간 개선이 있었다고 합니다.
Typical caching setup
트래픽이 높은 서비스에서는 대부분 이런식으로 캐시를 구성하고 있습니다. L1은 어플리케이션 캐시(ex. Ehcache), L2는 레디스로 생각할 수 있겠죠? 위에서 말했던 레디스와 DB사이의 Stampede 이슈는 L1와 L2사이에서도 반복될 수 있습니다.
Under high traffic load similar cache stampede/miss-storm can be observed between L1&L2 cache (and so on)
Hot Keys
하나의 키에 대한 접근이 너무 많을 때에도 문제가 발생하며, 이 현상 또한 캐시 성능을 저하시킬 수 있습니다.
Hot Key 문제가 발생하면, 가장 쉽게 생각 할 수 있는 대안은 읽기 분산입니다. 하나의 마스터에 여러개의 슬레이브를 추가하고, 어플리케이션에서는 여러대의 서버에서 데이터를 읽어오는 방식입니다. 하지만 이런 구성에서 장애가 발생해서 페일오버가 발생하게 된다면 상황이 복잡해집니다. 생각지도 못한 장애와 병목이 발생할 가능성이 존재합니다.

이 세션에서는 키의 복제본을 만드는 방식을 제안하고 있습니다.
def write_keys(key, copies):
return ["{{copy{}}}-{}".format(i,key) for i in range(copies)]
def read_key(key, copies):
r = randrange(0, copies)
return "{{copy{}}}-{}".format(r, key)
hot key를 저장할 때에는 앞에 prefix를 붙혀서 여러개의 키를 만들어냅니다. 키를 읽을 때에는 그 prefix를 사용해서 랜덤하게 접근하는 로직을 추가합니다.
Compression
레디스에서 머신러닝 모델, HTTP 페이지 등을 다루거나, 메시지 큐 등으로 사용하며 크기카 큰 데이터를 저장할 때에 캐시 성능 저하가 발생할 수 있습니다. 이 때에는 압축을 고려할 수 있습니다. 압축을 할 때에는 다음 세 가지 사항을 고려해야 합니다.
첫 번째는 적절한 압축 비율(Compression Ratio) 입니다. 높은 압축률이 중요한 것이 아니라, 적절한 압축률을 찾아야 합니다. 왜냐하면 압축을 할 때의 CPU 성능 을 생각해야 하기 때문입니다. 안정성은 물론 필수입니다.
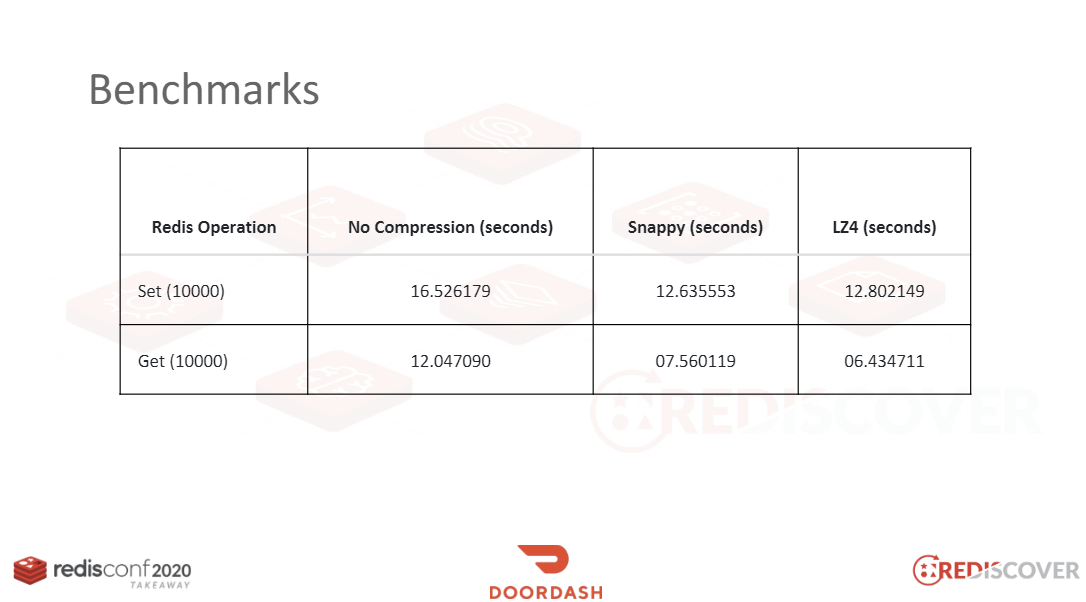
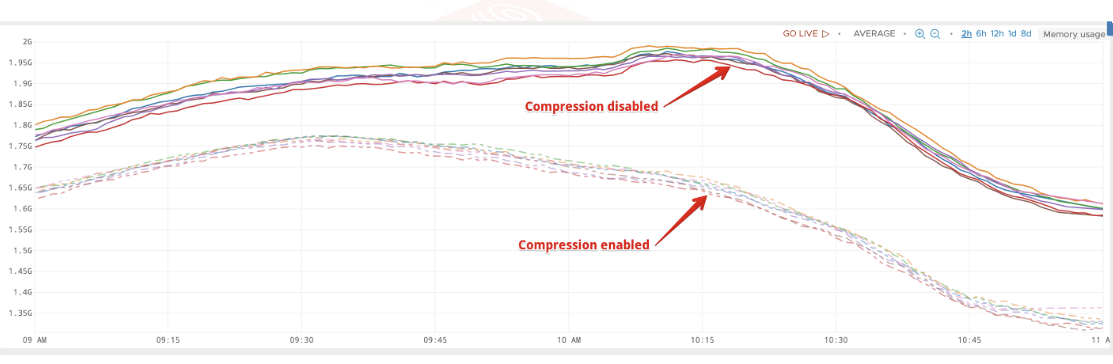
Cache Stampede는 실제로 어떤 영향을 끼칠까요
글을 마치기 전 제가 담당하고 있는 한 서비스에서 Cache Stampede 현상이 발생한 사례를 공유드리고자 합니다. 이 서비스에서는 레디스에 데이터를 저장할 때 기본적으로 TTL값을 300초로 저장하고 있으며, 이는 일반적인 상황에서 아무런 문제가 되지 않고 있었습니다. 하지만 트래픽이 과도하게 몰리는 상황에서 캐시서버에 엄청난 부하가 발생했고 이를 분석하는 과정에서 아래 로그를 확인할 수 있었습니다.

EXISTS 커맨드로 확인
SETDB에서 데이터를 읽어온 뒤 레디스에 SET 하는 과정에서 엄청나게 오랜 시간이 소요됨을 볼 수 있고, 또한 이런 프로세스가 특정 시간대에 여러 개 발견되었습니다. 이는 분명히 레디스의 성능을 저하시킨다는 것을 예상할 수 있습니다.
출처

