
네이버 검색 SRE - 상위 레벨 모니터링 시스템
네이버 검색 SRE - 상위 레벨 모니터링 시스템 관련


네이버에는 검색, 쇼핑, 플레이스 등 대한민국 사람들의 삶에 밀접한 관계가 있는 수많은 서비스가 있습니다. 이렇게 필수적인 서비스를 안정적으로 제공하는 것은 매우 중요합니다. 서비스의 가용성과 성능을 유지하고 문제 발생 시 빠르게 대응하기 위해서는 효과적인 모니터링 시스템과 대응 체계가 필요합니다.
이 글에서는 상위 레벨 모니터링 시스템을 구축하고 사용한 경험을 소개하고자 합니다. 특히 네이버 통합 검색에 상위 레벨 모니터링 시스템을 적용한 사례를 통해 상위 레벨 모니터링 시스템 구축에 중요한 요소와 경험, 노하우를 공유합니다.
하위 레벨 모니터링 시스템과의 차이점
본격적으로 설명하기 전에 하위 레벨 모니터링 시스템(micro monitoring system)과의 차이점을 설명하겠습니다.
| 하위 레벨 모니터링 | 상위 레벨 모니터링 | |
|---|---|---|
| 모니터링 범위 | 서비스 내부의 특정 레이어 혹은 특정 서버, 인스턴스 | 개별 서비스, 전체 서비스와 연관 서비스 |
| 지표 | 호스트 단위의 지표 | 서비스별, 레이어별 통합 지표 |
먼저 하위 레벨 모니터링 시스템의 관심사는 서비스 내부의 특정 계층 혹은 개별 서버 단위입니다. 특정 서비스의 컴포넌트 담당자가 직접 지표를 보고 문제 지점을 확인해 대응할 수 있을 정도의 해상도를 제공해야 합니다.
반면, 상위 레벨 모니터링 시스템의 관심사는 서비스 전체, 개별 서비스의 레이어와 같이 하나의 서비스 혹은 여러 서비스를 구성하는 모든 계층을 아우릅니다. 그렇기 때문에 모니터링의 근간이 되는 지표는 하위 레벨 모니터링 시스템과 다르게 더 통합된(aggregated) 지표입니다.
네이버 검색은 통합 검색과 하위 서비스들, 그리고 수백 개의 개별 서비스로 이루어져 있습니다. 그리고 각 서비스에는 여러 레이어가 있습니다. 또한, 검색 결과를 만들기 위해 여러 서비스는 서로 트래픽을 주고받기도 합니다. 이렇게 복잡한 네이버 검색 시스템의 효과적인 모니터링을 위해 구축해 사용하고 있는 상위 레벨 모니터링 시스템의 구축 과정과 효과를 설명하겠습니다.
네이버 검색의 하위 레벨 모니터링 시스템의 한계
기존의 하위 레벨 모니터링(micro monitoring) 시스템은 단일 호스트나 단일 서버를 대상으로 지표를 수집 및 가시화하여, 단일 서버의 문제 또는 서비스의 특정 레이어의 문제를 파악하기에 유용했습니다.
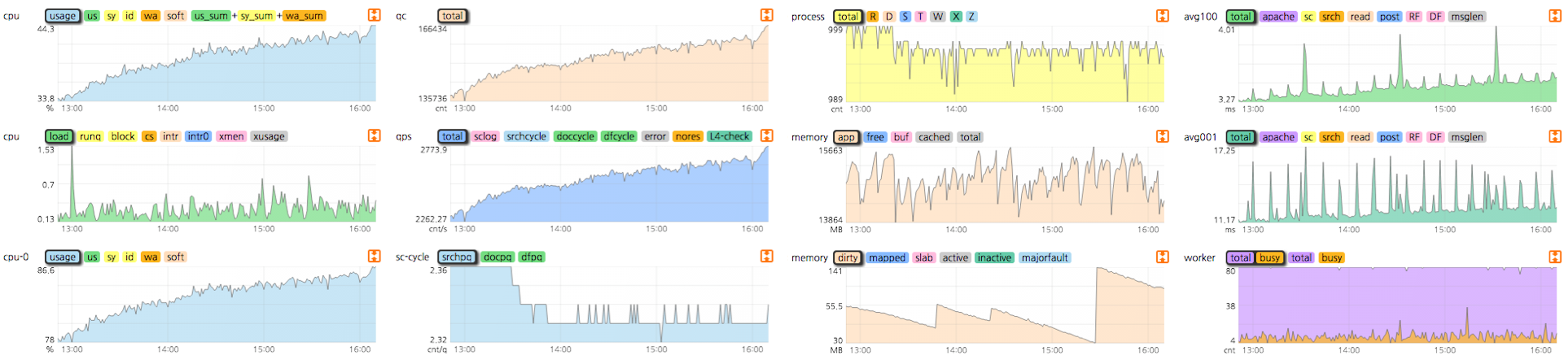
하지만 네이버 검색이 성장하고 다양한 시스템과 도구가 생겨나면서 모니터링 대상 또한 수만 대의 서버와 수백 개의 서비스로 늘어났고 각 서비스는 여러 레이어로 구성된 거대하고 복잡한 시스템이 되었습니다. 그 결과 기존의 하위 레벨 모니터링 시스템만으로는 모니터링 및 장애 관제를 효율적으로 하기에는 어려움이 생겼습니다.
하위 레벨 모니터링 시스템에서는 단일 서버, 단일 서비스 특정 레이어의 지표를 확인할 수는 있었지만 정보 체계가 일원화되지 않았고 개별 서비스의 레이어별 대시보드를 보며 관제해야만 했습니다.
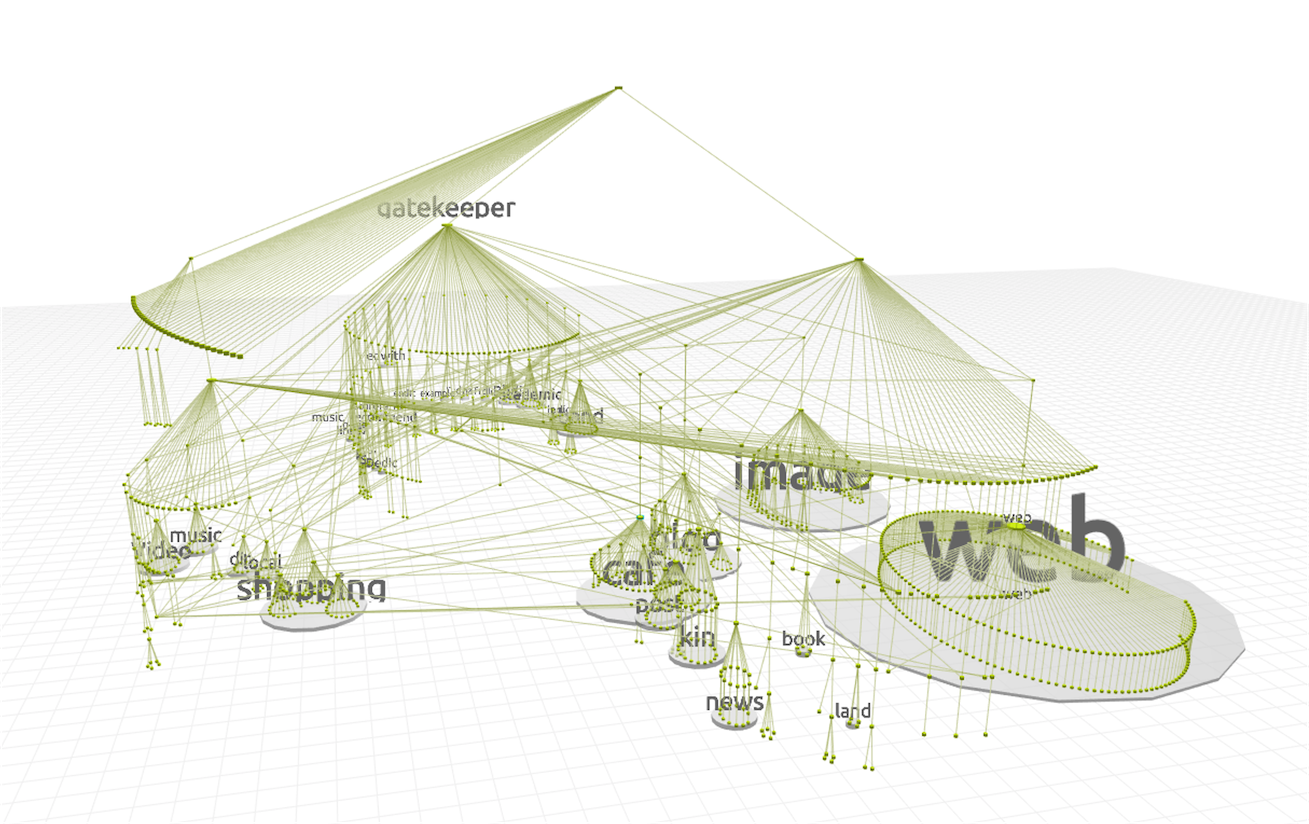
그러다 보니 네이버 검색 시스템 전체 서비스의 건강도를 확인하기 위해 개별 대시보드를 찾고 서비스 담당자와 소통해 문제를 파악해야 했습니다. 서비스가 많아지면서 개별 담당자와의 커뮤니케이션 비용 및 대시보드를 찾는 비용이 증가했고 상위 레벨 모니터링 시스템이 필요해졌습니다.
상위 레벨 모니터링 시스템을 위한 정보 체계 일원화
기존의 개별 서비스 레이어별 대시보드에서 제공하는 정보를 하나의 대시보드에 동일한 기준으로 모아서 한눈에 확인하기 위해서는 정보 체계를 일원화해야 했습니다.
서비스별 ID 발급
상위 레벨 모니터링 시스템의 첫걸음으로, 각 서비스에 고유한 식별자(Search Service Unique ID)를 발급했습니다. 발급한 서비스별 ID를 서비스별 장비 지표, 컨테이너 지표에 매핑하여 서비스 단위의 지표를 구분할 수 있었습니다. 이는 서비스 단위 대시보드 및 알림의 기반이 되었습니다.
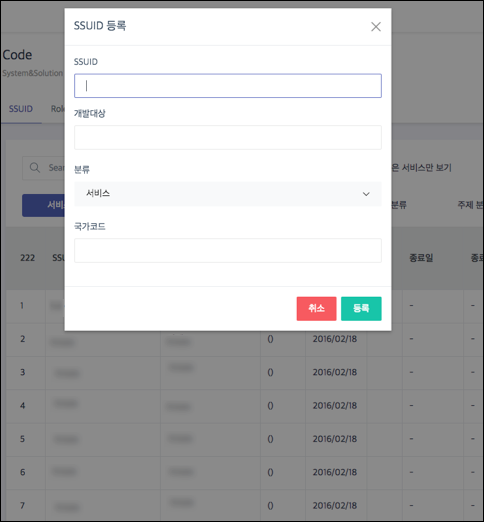
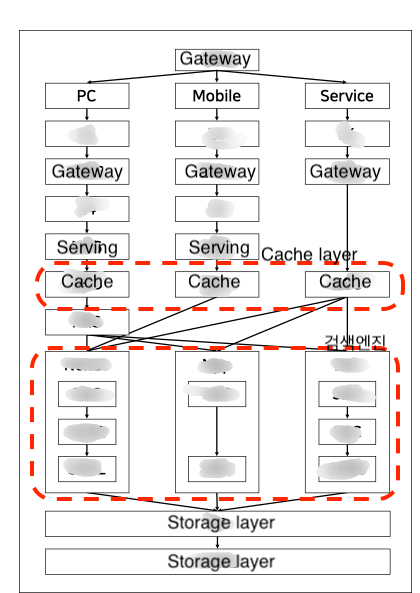
표준 서비스 구조 가시화
대부분의 검색 서비스는 표준화된 호출 구조로 이루어져 있습니다. 데이터 흐름을 이해하기 위해 각 서비스의 전체 레이어 구조를 가시화했습니다. 이렇게 가시화된 정보는 상위 레벨 모니터링 시스템의 통합 대시보드를 구성할 때 사용되었습니다.
서비스별 담당자 매핑
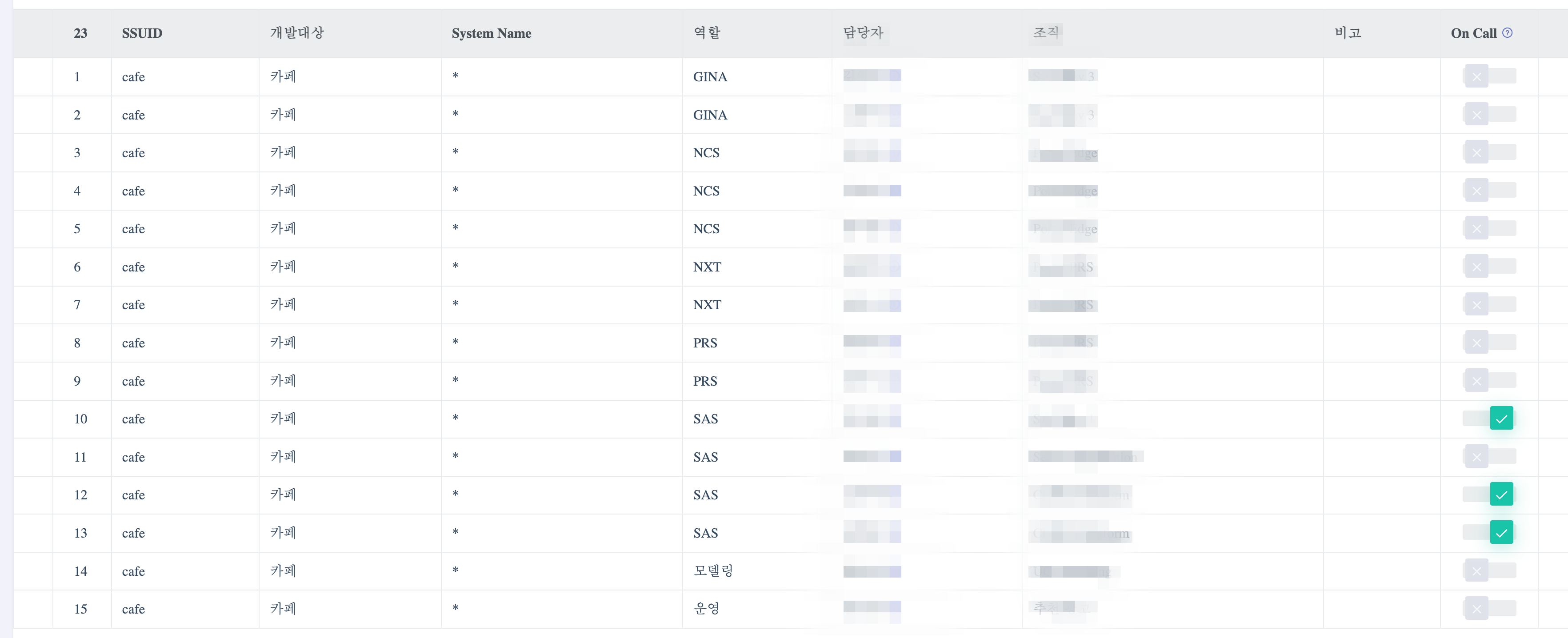
특정 서비스 레이어에 문제가 발생했을 때 실제 담당자를 확인하고 빠르게 소통해 대응할 수 있도록, 서비스별로 각 레이어의 담당자(directly responsible individual, DRI) 매핑 시스템을 개발하고 지속적으로 갱신했습니다. 특정 서비스 레이어에서 이상이 감지될 경우 담당자에게 바로 알림을 전송할 수 있습니다.
상위 레벨 모니터링 시스템 - 통합 대시보드와 알림
정보 체계를 일원화해 상위 레벨 모니터링 시스템을 위한 기반을 마련했고 이를 사용해 대시보드와 알림을 만들 수 있었습니다. 상위 레벨 모니터링 시스템이 제공하는 기능과 특징을 소개하고 운영을 위해 어떤 노력을 하고 있는지 소개합니다.
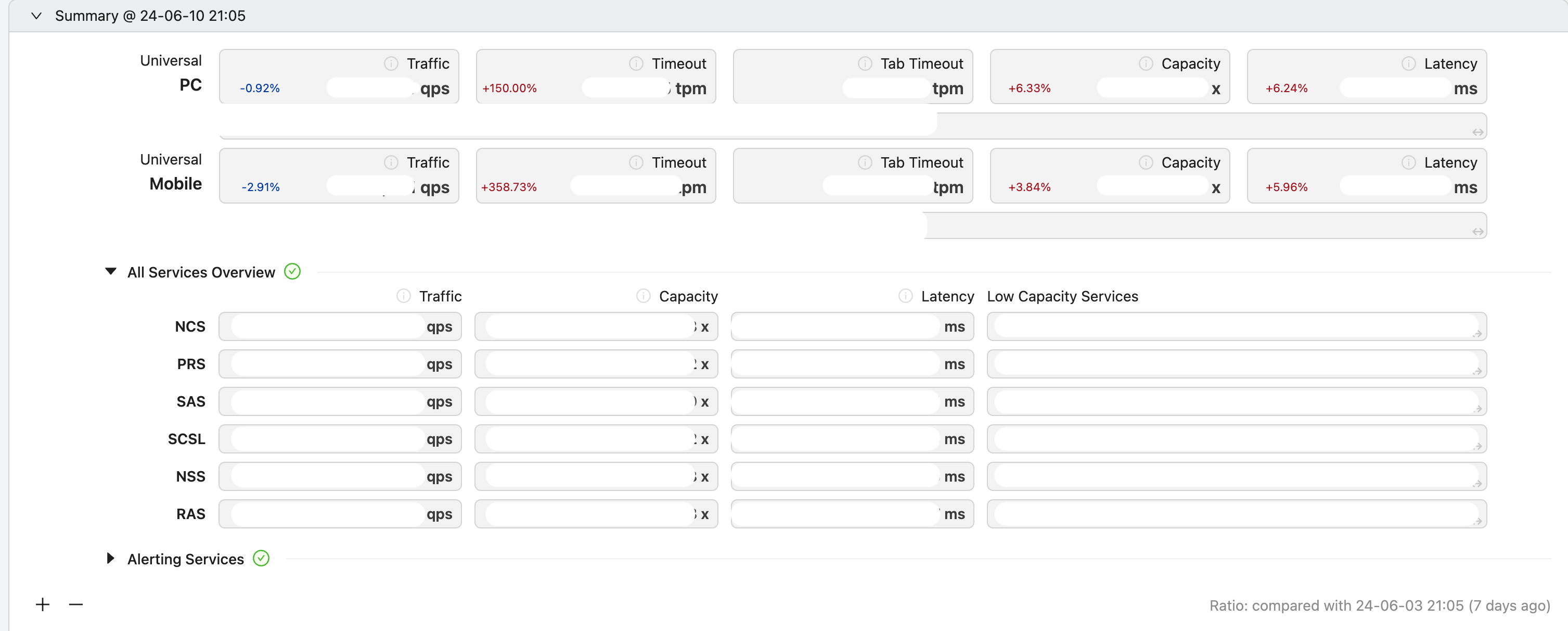
통합 대시보드 오버뷰
통합 대시보드의 오버뷰의 모습입니다. 통합 검색과 하위 서비스들의 레이어별 현재 상항을 한눈에 보여주도록 구성되어 있습니다.
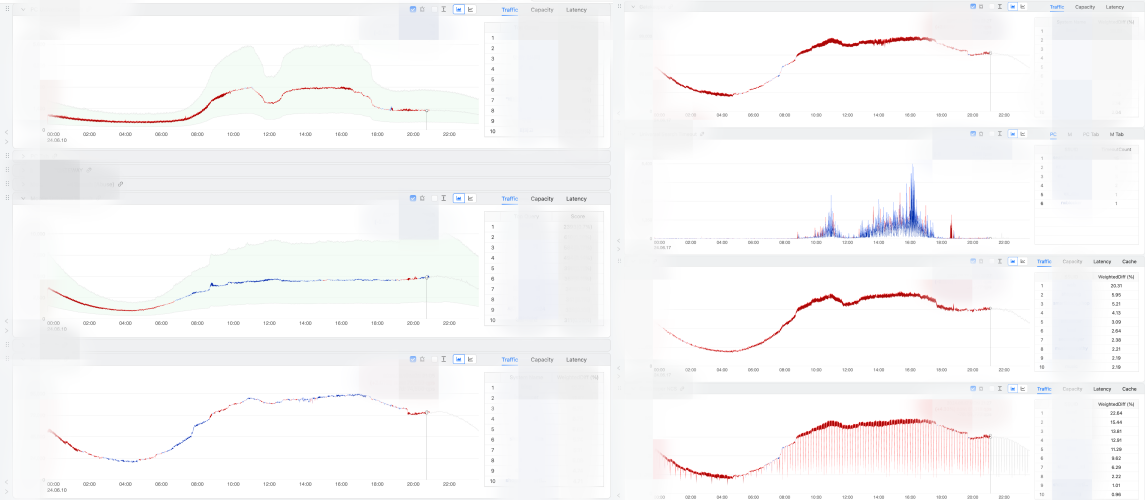
통합 대시보드 상세보기
통합 대시보드 상세보기에서는 네이버 통합 검색의 이용자 요청이 들어오는 최상단 레이어부터 최하단 레이어까지 레이어별 트래픽과 가용량을 계산해 한눈에 보여줍니다.
장애 발생 시 대시보드에서 바로 확인하고 장애가 각 레이어에 어떻게 영향을 주는지 파악할 수 있었습니다. 또한, 모든 담당자가 볼 수 있는 공통된 대시보드가 존재하기 때문에 특정 서비스, 레이어의 개별 대시보드를 찾아보는 비용과 담당자와의 커뮤니케이션 비용을 줄일 수 있었습니다.
서비스별 지표 뷰잉 및 알림
개별 서비스의 레이어별 대시보드를 공통된 뷰로 제공해, 상위 레벨 모니터링 시스템 안에서 개별 서비스 내부의 문제 식별이 가능합니다.
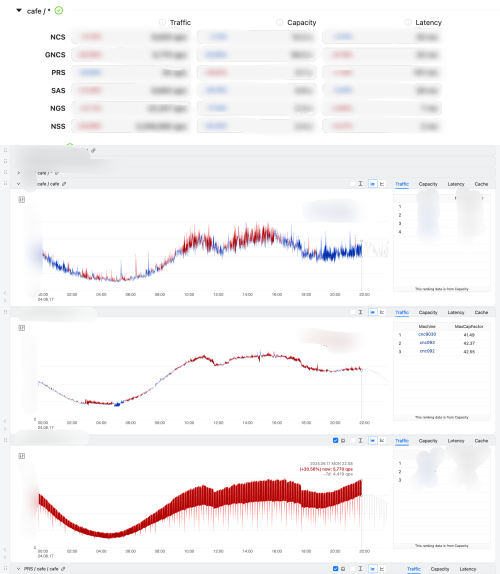
서비스 내 개별 레이어의 트래픽을 확인할 수 있어, 문제 및 영향도 파악에 도움이 되었습니다.
간단하지만 강력한 가용량 규칙 개발
최대가용배수와 부하증가배수라는 개념을 도입하여 갑작스러운 트래픽 증가와 같은 가용량 임계 상황에 대비했습니다.
- 최대가용배수: 현재 받는 트래픽을 기준으로 더 받을 수 있는 트래픽의 배수
- 부하증가배수: 복제 서버 중 1대에서 문제 발생해 복제에서 빠질 경우 남은 서버에 생기는 부하의 배수
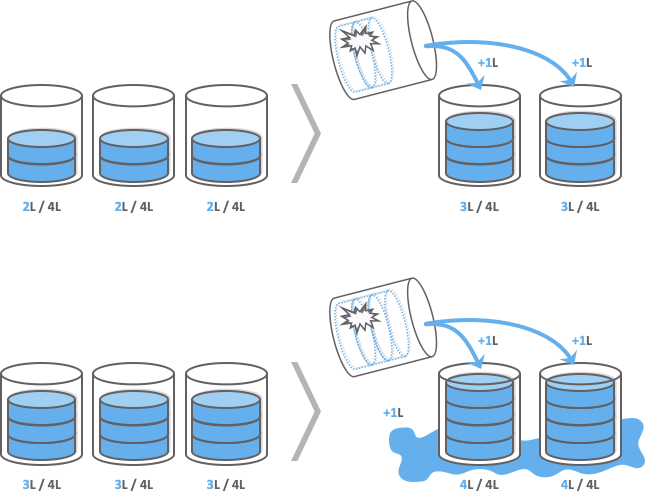
서비스별 가용량을 측정해서 부하증가배수 > 최대가용배수의 경우 위험한 상황으로 판단해 서비스 담당자에게 알림을 보내거나 가용량을 확보하도록 권고합니다. 또한, 평상시에도 가용량을 계산해 적정한 가용량을 확보하기 위해 상위 레벨 모니터링 시스템을 사용해 관리 중입니다.
시각화된 데이터를 이용해 인사이트 도출
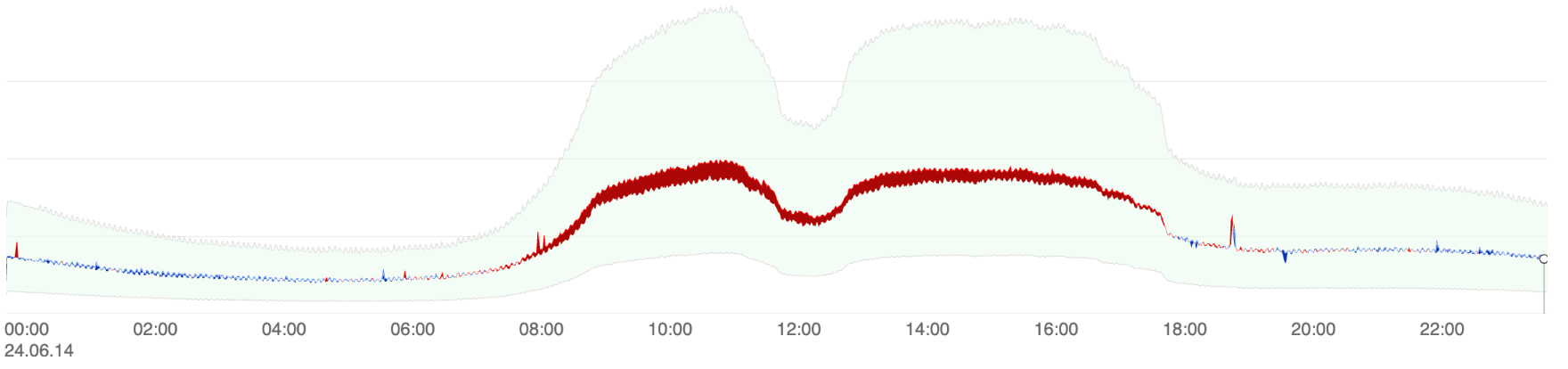
네이버 검색에 유입되는 트래픽을 시각화한 결과, 네이버 검색은 한국인의 생활 주기(24시간, 1주일 단위)에 맞춰 같은 요일 같은 시간에는 비슷한 트래픽이 유입된다는 인사이트를 도출했습니다.
- 24시간 단위 그래프에서 사람들의 활동 시간 및 업무 시간에 맞춰 트래픽이 들어오는 것을 확인
- 1주일 단위 그래프에서 평일과 공휴일의 트래픽 차이를 확인
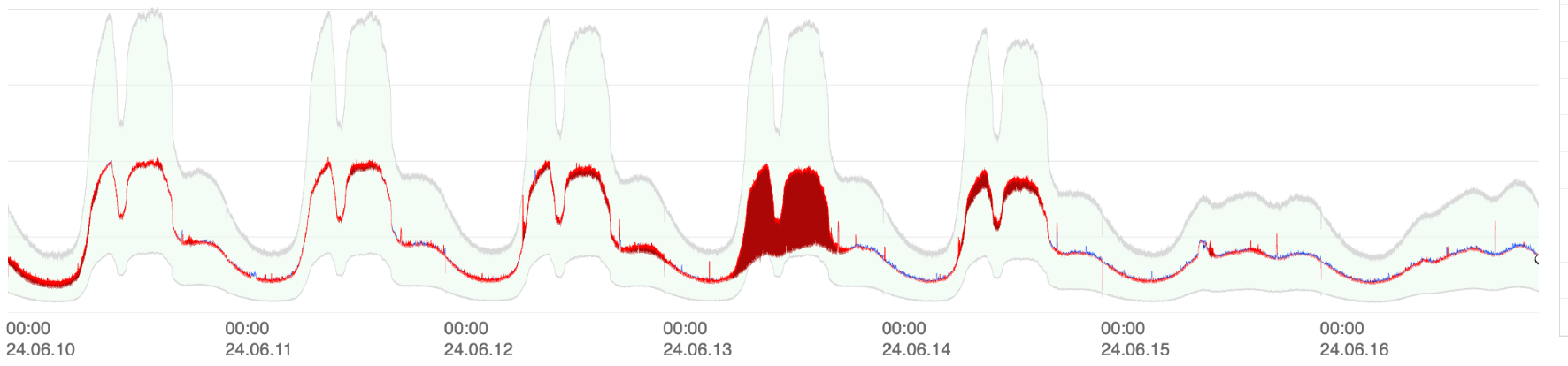
인사이트를 활용한 이상 탐지
앞에서 도출한 인사이트에 따라 데이터를 분석하여, 다음과 같은 이상 탐지 규칙을 만들었습니다.
- 이전 5주와 같은 요일 같은 시간의 트래픽 중앙값을 기준으로, 트래픽의 기준의 40% 이하 또는 200% 이상이면 이상 상황으로 판단
- 이상 상황 발생 시 담당자 및 IC(Incident Commander), IO(Incident Operator)에게 알림
- 트래픽이 전혀 유입되지 않으면 장애로 판단
- 장애 발생 시 담당자에게 경보
- 주말 외의 공휴일에는 이전 공휴일의 트래픽 지표를 활용하여 예측된 값을 기준으로 경보 설정
이와 같이, 모니터링을 통해 인사이트를 도출하고 이를 기반으로 규칙을 만들어 이상 상황을 빠르게 탐지할 수 있었습니다.
ChatOps를 활용한 커뮤니케이션
장애 발생 시 영향도 파악 및 담당자 대응 여부를 확인하는 것은 매우 중요합니다. 네이버 검색 SRE에서는 경보 발생 시 담당자에게 바로 경보 메시지가 발송되고 담당자의 대응 여부가 전파되도록 정책 및 시스템을 구성했습니다.
네이버 검색 SRE에서는 트래픽 급증에 대비해, 지진과 같은 행정안전부의 재난문자 발송 상황에서 IC, IO에 경보 메시지를 발송합니다. 다음은 2023년 11월 30일 새벽 4시 55분경 경주 지진 발생 시 발송한 경보 메시지입니다. '제가 대응하겠습니다' 버튼을 누르면 다른 관련 담당자들에게 누가 대응 중인지 메시지가 발송됩니다.
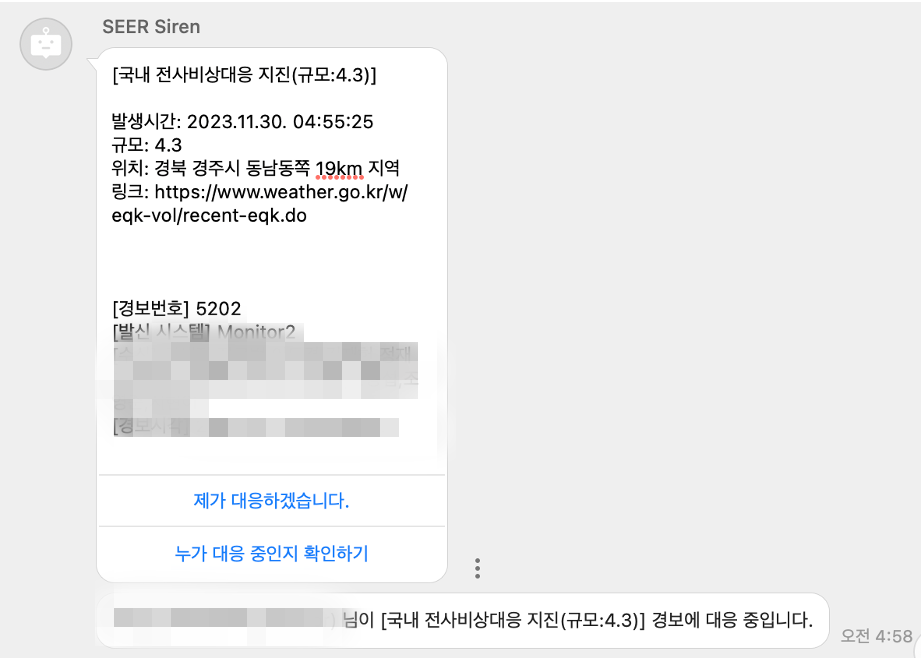
이처럼 시스템을 통해 대응 현황이 전파되므로 커뮤니케이션 비용을 줄일 수 있습니다.
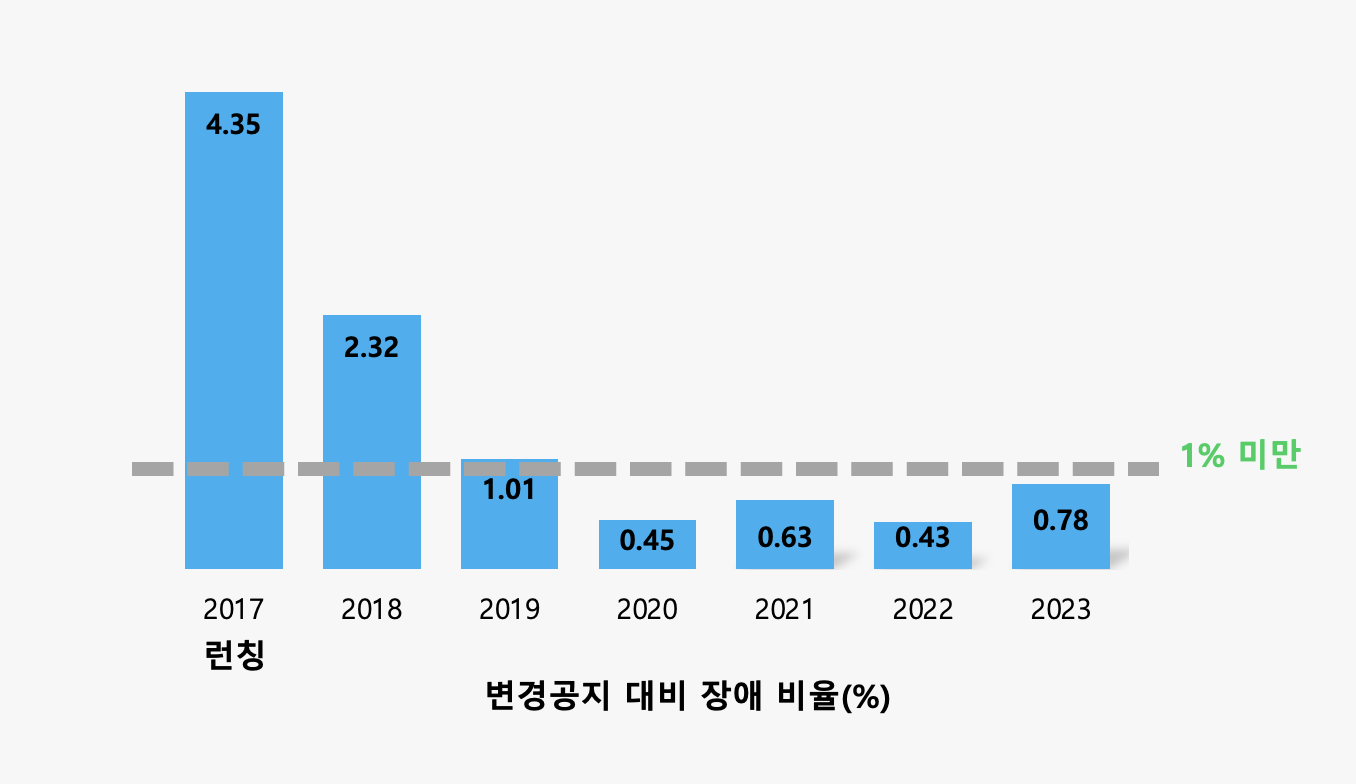
상위 레벨 모니터링 시스템의 효과 - 변경 건수 대비 장애율 1% 미만
네이버 검색은 본격적으로 상위 레벨 모니터링 시스템 도입을 시작한 2017년을 기점으로 변경 수 대비 장애율이 감소했고 2020년부터는 1% 미만을 계속 유지해오고 있습니다.
지속적인 운영을 위한 노력
상위 레벨 모니터링 시스템을 성공적으로 운영하기 위해서는 시스템 자체의 성능뿐만 아니라 지속적인 개선이 필요입니다. 지속적인 운영을 위한 주요 점검 포인트는 다음과 같습니다.
알림 규칙의 지속적인 조정
알림 규칙이 잘 동작하는지 데이터와 통계를 확인하며 지속적으로 조정해야 합니다.
- 규칙에 필터 추가: 잦은 오경보를 줄이기 위해 알림 조건을 조정하고, 필요하면 필터를 추가합니다. 예를 들어, 트래픽 주기성이 낮은 서비스에 대해서는 가용량 부족 시 경보 발생과 같은 추가 필터 조건을 설정합니다.
- 규칙의 임계 조건 조정: 5주 중앙값 규칙의 임계 조건(40~200%)을 시스템 변화에 따라 적절히 조정합니다.
담당자 정보의 최신화
서비스의 담당자는 변경될 수 있기 때문에 지속해서 확인하고 갱신해 이상 탐지 시 담당자에게 제대로 알림이 도달하게 해야 합니다.
사후 리뷰(post-incident review, PIR) 문화 정착을 통한 재발 방지
장애 발생 후 사후 리뷰를 통해 문제의 원인을 분석하고 재발 방지 대책을 마련합니다. 사후 리뷰는 담당자가 자발적으로 작성하게 해야 하며, 원활한 사후 리뷰 문화 정착을 위해서는 리뷰 시 비난하는 의도가 담기지 않아야 합니다.
마치며
네이버 검색 시스템은 상위 레벨 모니터링 시스템 도입으로 시스템 운영의 안정성과 신뢰성을 크게 향상할 수 있었습니다. 서비스의 장애율을 낮추고 사용자에게 더 나은 경험을 제공할 수 있게 되었습니다. 마지막으로 상위 레벨 모니터링 시스템에서 중요한 것들을 다시 짚어보고 글을 마무리하겠습니다.
통합 모니터링과 정보 체계 일원화의 중요성
다양한 서비스와 레이어가 존재하는 복잡한 시스템에서는 통합 대시보드에서 전체 시스템의 상태를 한눈에 파악하고 빠르게 대응하는 것이 중요합니다. 또한, 서비스별 ID 발급, 표준 서비스 구조 가시화, 담당자 매핑 등을 통해 정보 체계를 일원화하여 효율적인 모니터링과 알림을 제공할 수 있습니다.
규칙 기반의 이상 탐지 및 알림 시스템
단순하지만 강력한 규칙 기반의 알림 시스템은 장애 상황을 빠르게 탐지하고 대응하는 데 효과적입니다. 주기적인 트래픽 패턴 분석과 이를 기반으로 한 경보 규칙 설정은 빠른 문제 인식에 도움이 됩니다. IC, IO, 담당자는 모니터링 시스템의 알림을 받으며 시스템과 서비스 변화에 맞춰 지속해서 알림 규칙을 검토하고 조정해야 합니다.
빠르고 효율적인 커뮤니케이션
장애 상황에서 커뮤니케이션은 빠르고 정확해야 합니다. 통합 대시보드는 빠르고 효율적인 커뮤니케이션을 돕고 ChatOps를 통해 담당자의 대응 여부를 확인하고 공유함으로써 효율적인 커뮤니케이션이 가능합니다.