
실시간 광고 사용자 ID 매핑
실시간 광고 사용자 ID 매핑 관련


네이버 광고 시스템에서는 광고 노출 사용자를 대표할 수 있는 ID를 생성하는 작업이 필요합니다. 실시간 광고 사용자 ID 매핑 시스템은 대량의 이벤트 로그에서 추출한 사용자 ID로 광고 사용자를 대표할 수 있는 그룹 ID를 매핑합니다.
이 글에서는 실시간 광고 사용자 ID 매핑 시스템의 설계부터 각 주요 모듈을 소개합니다. gRPC, Spark Structured Streaming을 이용한 마이크로서비스 아키텍처를 구축한 방법과 사용자 ID를 그래프 구조로 매핑하는 법을 포함합니다. 설명 과정에서 언급되는 예시 상황과 ID 타입(ad_id, mobile_id, browser_id)은 설명을 위해 가상으로 생성된 것입니다.
광고 사용자 ID 매핑 소개
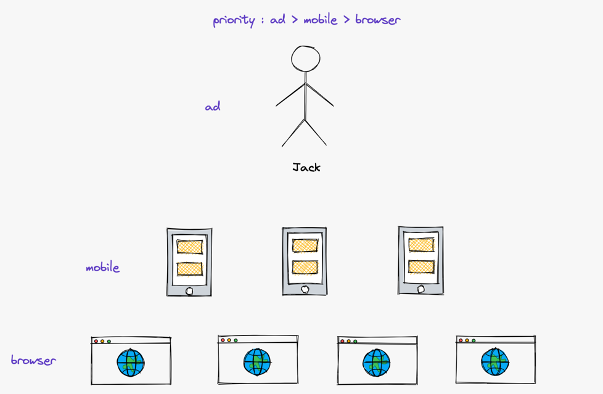
Jack이라는 가상의 인물이 있습니다. Jack은 여러 디바이스(pc, 모바일)를 가지고 있고 여러 브라우저를 사용합니다. Jack이 여러 디바이스와 브라우저로 서비스를 이용해 다음 그림과 같은 이벤트 로그가 발생했다고 가정해보겠습니다. 개별 로그만 봐서는 각 ID 타입의 여러 값이 한 명의 것이라는 것을 알 수 없습니다.

그렇다면 세 개의 로그를 모아서 중복된 값을 연결해보면 어떨까요? ad_id 값 a는 첫 번째 로그와 두 번째 로그에 있습니다. mobile_id 값 b는 첫 번째 로그와 세 번째 로그에 있습니다. 이렇게 중복된 값을 연결하면, 이 사용자가 누구인지는 모르지만 한 명에게서 세 개의 로그가 발생했다고 추론할 수 있습니다.
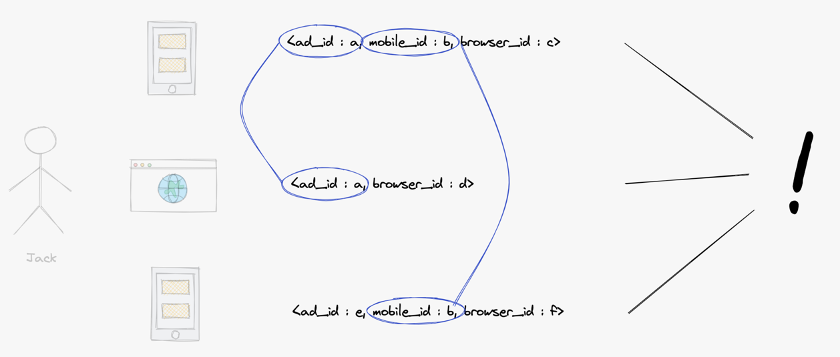
이 세 개의 로그에서 나온 사용자 ID에 하나의 group_id 값 j를 매핑합니다.
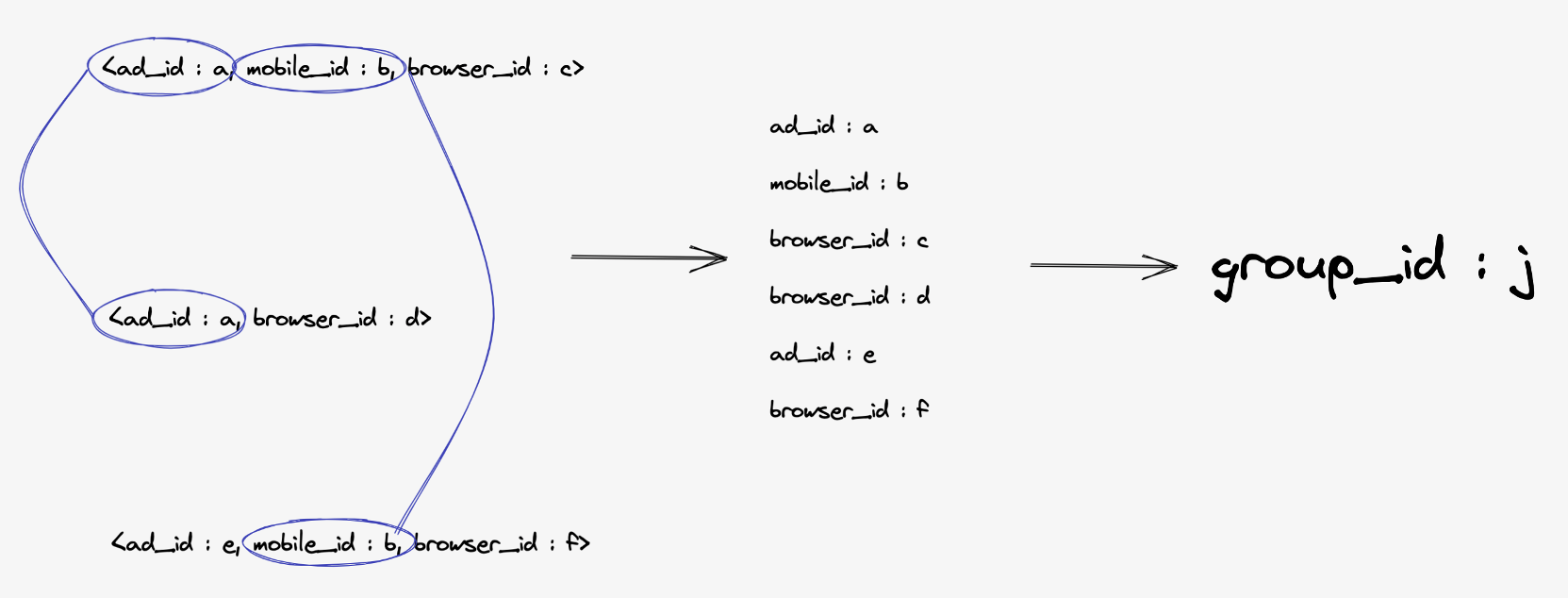
이와 같이, 실시간 대량 이벤트 로그에서 추출한 사용자 ID를 연결해서 가상 광고 그룹 ID에 매핑하는 시스템을 실시간 광고 사용자 ID 매핑 시스템이라고 부르고 있습니다.
시스템 설계
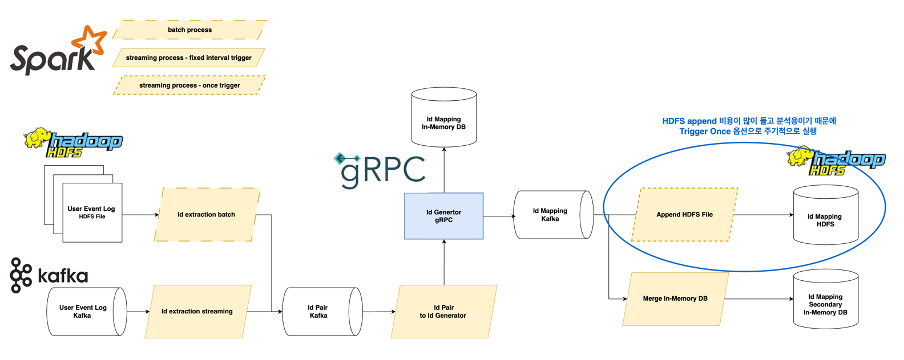
다음은 실시간 광고 사용자 ID 매핑 시스템 설계도입니다. 전체 파이프라인은 마이크로서비스 아키텍처를 지향하여 각 모듈이 Apache Kafka로 연결되어 디커플링되어 있습니다. 왼쪽에서 오른쪽의 흐름으로 데이터 처리 순서에 따라서 설명하겠습니다.
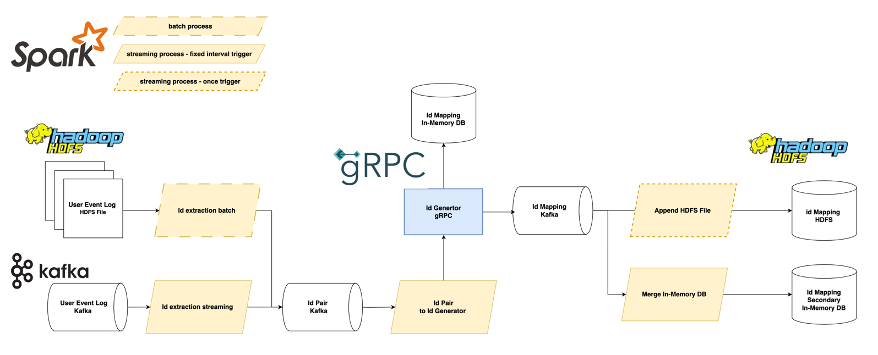
입력 데이터는 이벤트 로그로, HDFS에 저장된 파일 데이터와 Apache Kafka에 저장된 실시간 데이터입니다. 실시간 데이터는 5만 TPS 이상을 처리하고 있습니다.
id extraction이라는 Apache Spark 앱으로 이벤트 로그에서 사용자 ID만 추출해서 id pair 토픽을 생성합니다. 이때 입력 데이터 타입에 따라서 배치 앱과 Spark Structured Streaming 앱으로 분리해서 처리합니다. 앱에서는 특정 윈도우로 중복 제거를 실행하여 부하를 줄입니다.
id pair to id generator라는 Spark Structured Streaming 앱에서는 id pair 토픽을 소비(consume)해서 id generator gRPC에 ID 매핑 요청을 보냅니다. gPRC 서버에서는 매핑 결과를 인메모리 데이터베이스와 id mapping 토픽에 저장합니다. id generator gRPC 서버와 ID 매핑 과정은 뒤에서 더 자세히 설명하겠습니다. 인메모리 데이터베이스에 저장된 매핑 결과는 빠른 읽기가 필요할 때 사용됩니다.
id mapping 토픽에 저장된 매핑 결과는 소비되어 HDFS와 세컨더리 인메모리 데이터베이스에 저장되고 각각 배치와 Spark Structured Streaming 앱으로 처리됩니다. HDFS 데이터는 분석에 사용되고 세컨더리 인메모리 데이터는 HA가 목적입니다.
모든 모듈은 분산 처리를 하고 확장 가능한 설계로 이루어져 있어 데이터가 한 번에 몰리는 상황에서도 유연한 대처가 가능합니다.
ID 매핑 트리 알고리즘
대량의 이벤트 로그가 실시간으로 유입되었을 때 중복되는 사용자 ID를 연결하는 알고리즘이 필요합니다. 어떻게 사용자 ID를 연결할 수 있을까요?
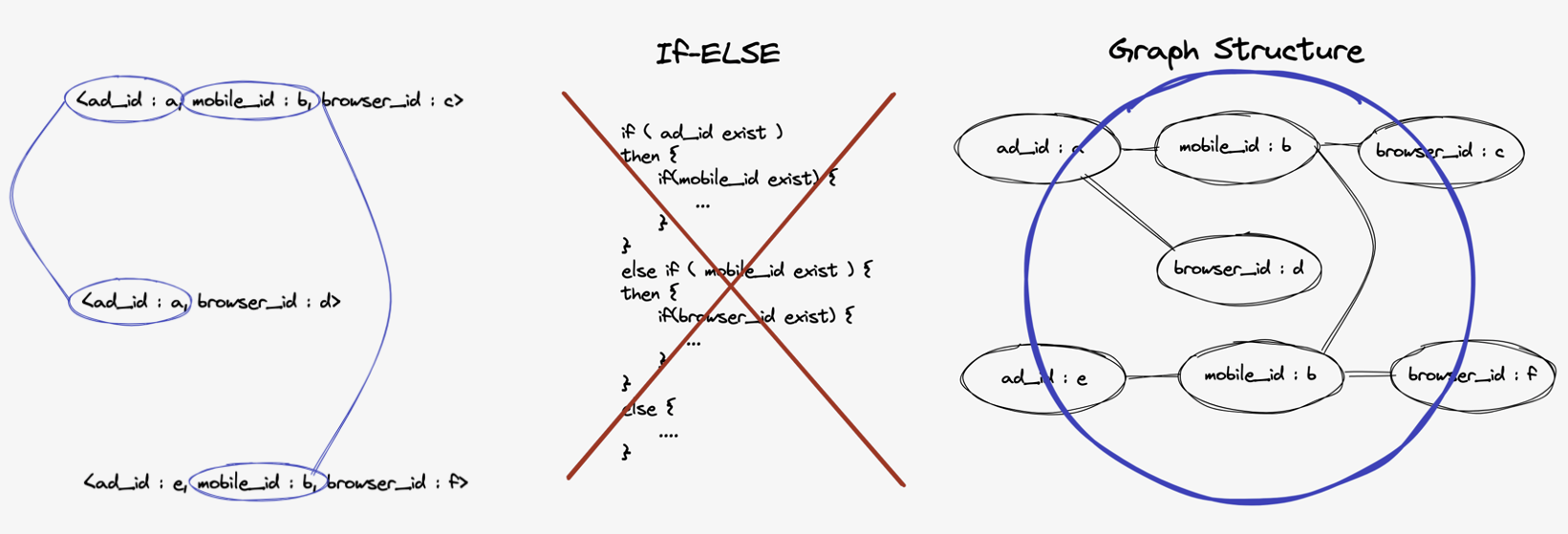
단순하게는 조건문을 사용할 수도 있습니다. 하지만 조건문을 사용하는 경우에는 모든 매핑 케이스를 파악하고 작성하지 않는다면 예기치 않은 매핑 결과를 생성할 수도 있습니다.
조금 더 생각을 해보면 사용자 ID를 연결하는 것은 그래프 구조를 만드는 문제로 치환할 수 있습니다. 각 사용자 ID를 노드(node)로 표현하고 동일한 사용자가 생성한 ID라고 판단되는 경우 간선(edge)으로 연결합니다. 다음 그림에서 오른쪽 그래프는 왼쪽의 이벤트 로그에서 생성한 그래프입니다.
ID 타입 우선순위
그래프 구조를 사용하면 사이클이 생성되거나 각 노드가 무한으로 연결될 수도 있습니다. 그래서 이런 사이클을 끊어내고 유한한 트리 구조를 만들기 위해서 사용자를 대표하기 용이한 ID 타입의 우선순위를 정의했습니다.
예를 들어 ad_id, mobile_id, browser_id가 존재할 때, ad_id는 사용자 단위로 발급되는 ID, mobile_id는 디바이스 단위로 발급되는 ID, browser_id는 브라우저 단위로 발급되는 ID라고 정의하겠습니다. 사용자를 대표하기 용이한 순서대로 ID 타입을 나열하면 ad_id > mobile_id > browser_id 순서가 됩니다. 이 순서를 트리 구조를 만드는 기준의 우선순위로 사용합니다.
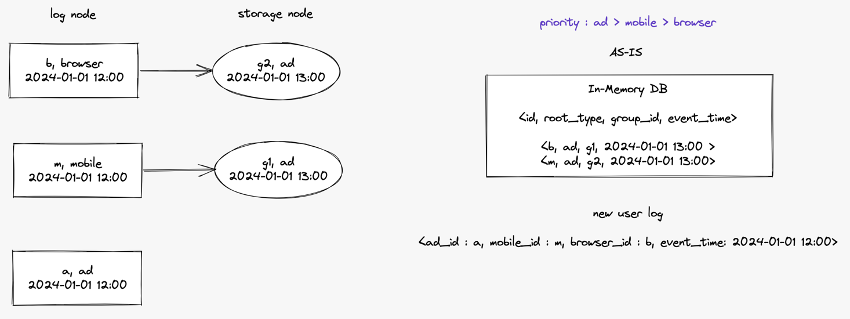
ID 매핑 트리 알고리즘 생성 예시
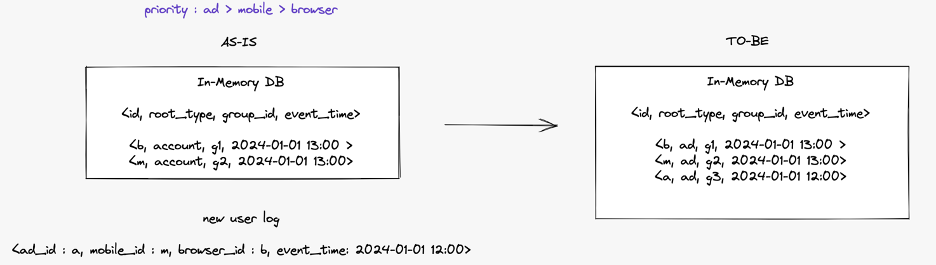
이미 매핑 결과가 인메모리 데이터베이스에 저장되어 있고 새로운 로그가 실시간으로 들어온 상황을 가정해 보겠습니다. 데이터베이스에는 사용자 ID가 저장된 id, 기준 ID 타입이 저장된 root_type, 매핑 그룹 ID가 저장된 group_id, 로그 이벤트 시간이 저장된 event_time 필드가 있습니다. 이 예시에서는 이미 저장된 ID 매핑의 이벤트 시간이 새로 유입된 이벤트 로그의 이벤트 시간보다 최신인 상황을 가정하고 있습니다. 이는 해당 알고리즘이 로그의 유입 순서와 상관없이 동일한 매핑 결과를 생성해내는 것을 강조하기 위한 상황입니다.

이어서 트리 구조 생성을 단계별로 설명하겠습니다.
1. 트리 노드 생성
먼저 노드를 생성합니다. 유입된 이벤트 로그에서 사용자 ID를 추출하여 로그 노드를 생성합니다. 그림에서는 사각형 노드로 표현되었습니다. 로그 노드에는 ID 값, ID 타입, 이벤트 시간이 저장됩니다. 그리고 각 로그 노드의 사용자 ID에 대해서 이미 매핑된 그룹 ID가 있는지 데이터베이스에 질의합니다. 각 로그 노드에 매핑된 그룹 ID가 있다면 해당 그룹 ID를 스토리지 노드로 생성하여 로그 노드의 자식 노드로 연결합니다. 스토리지 노드에는 그룹 ID, 기준 ID 타입, 이벤트 시간이 저장됩니다.
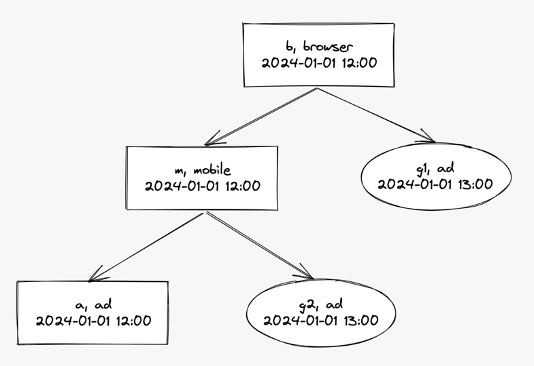
2. 트리 구조 생성
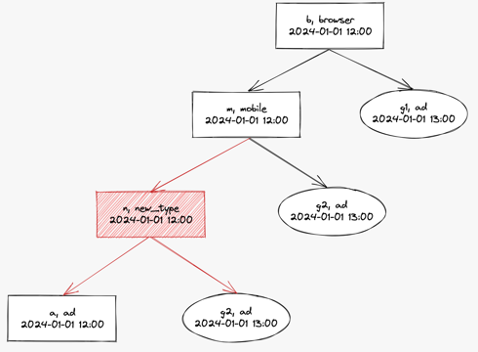
만들어진 노드를 가지고 완전한 트리 구조를 생성합니다. 로그 노드들을 ID 타입 우선순위의 오름차순으로 연결합니다. 즉, 우선순위가 가장 높은 ID 타입인 ad_id가 가장 말단 노드가 되고 우선순위가 가장 낮은 ID 타입인 browser_id가 루트 노드가 됩니다. 연결을 완료하면 다음과 같은 이진 트리를 얻을 수 있습니다.
3. 각 로그 노드의 기준 노드 찾기
각 로그 노드의 기준 노드를 검색합니다. 기준 노드는 사용자를 가장 잘 대표할 수 있는 노드입니다. 데이터베이스에 저장될 때 해당 노드의 ID 타입이 root_type으로 저장됩니다. 로그 노드 자신이 말단 노드인 경우는 스스로가 기준 노드가 되고 새로운 그룹 ID를 발급합니다. 로그 노드가 말단 노드가 아닌 경우는 해당 노드의 자식인 말단 노드 중에서 기준 노드를 찾습니다. 자식 말단 노드 중에서 기준 노드를 찾는 조건은 순서대로 다음 과 같습니다.
- ID 타입 우선순위가 가장 높은 노드
- 1이 동일한 경우, 이벤트 시간이 가장 최신인 노드
- 1, 2가 동일한 경우, 스토리지 노드
- 1, 2, 3이 동일한 경우, 경로가 가장 짧은 노드
b 로그 노드의 기준 노드를 검색하겠습니다. 자식 말단 노드는 a, g2, g1입니다. 그 중에서 기준 노드 조건 4에 따라 b 로그 노드의 기준 노드는 g1이 됩니다.
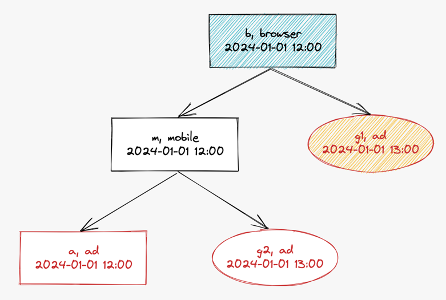
m 로그 노드의 기준 노드를 검색하겠습니다. 자식 말단 노드는 a, g2입니다. 그 중에서 기준 노드 조건 2에 따라서 m 로그 노드의 기준 노드는 g2가 됩니다.
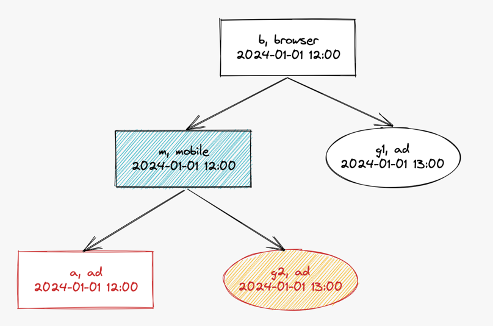
a 로그 노드는 말단 노드이므로 스스로 기준 노드가 되고 새로운 그룹 ID를 발급합니다.
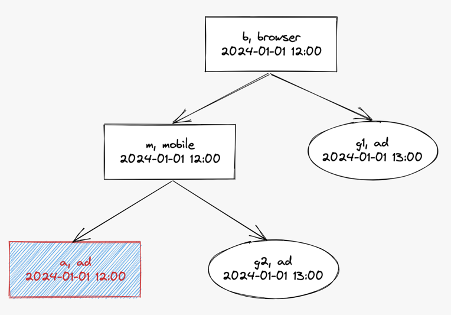
4. 데이터베이스에 결과 저장
생성된 트리를 기준으로 매핑 결과를 다음과 같이 저장합니다. b, m은 그룹 ID의 변동이 없기 때문에 업데이트가 없습니다. a는 새로 발급된 그룹 ID로 저장됩니다.
gRPC 기반 ID 생성기
ID 생성기는 ID 매핑 알고리즘을 구현한 구현체입니다. 좀 더 정확히 말하면, 입력으로 사용자 ID 목록을 갖고 출력으로 매핑된 광고 사용자 ID가 반환되는 gRPC API 서버입니다.
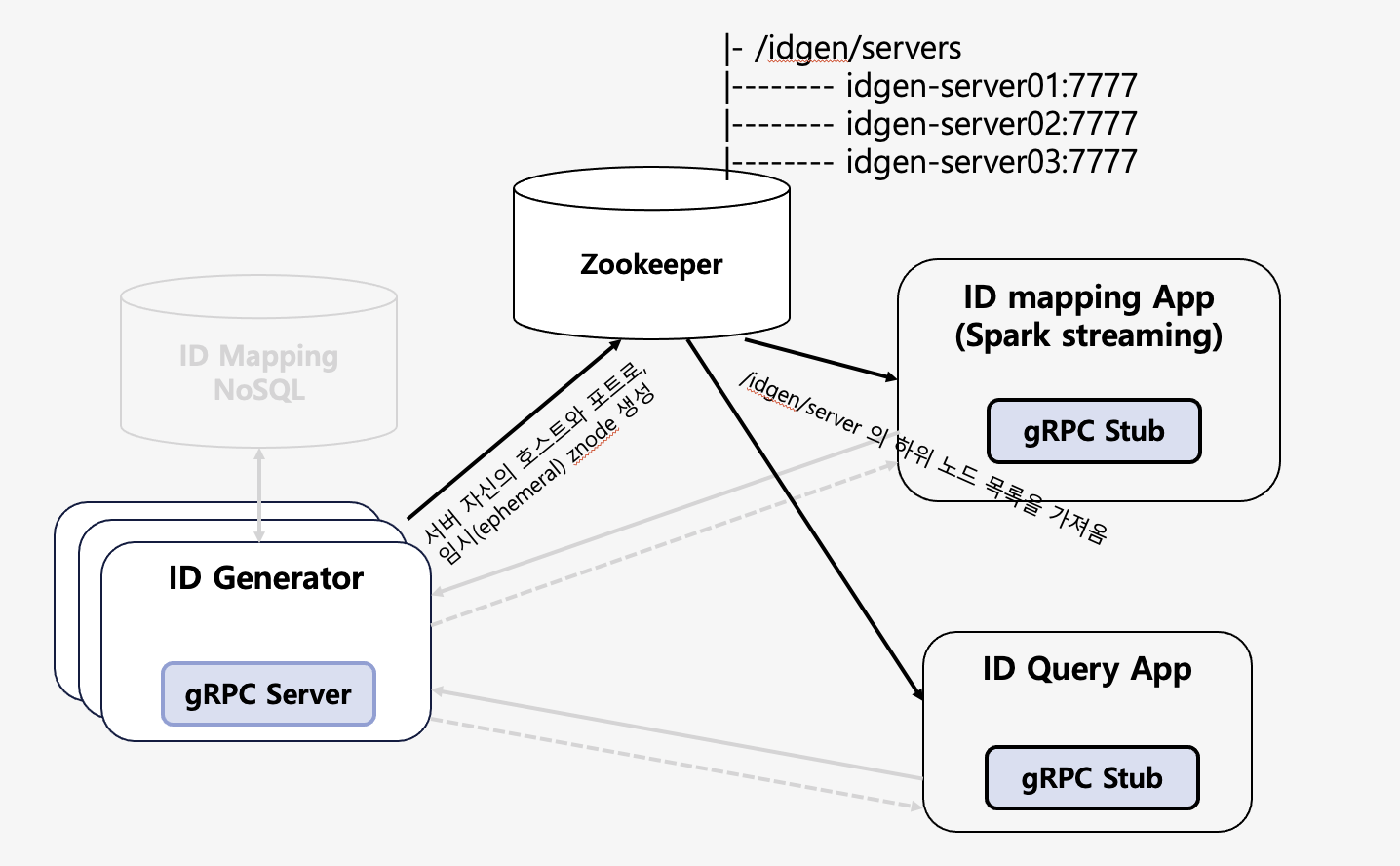
다음 그림에 ID 생성기 서버가 있습니다. 그리고 여러 개의 클라이언트 앱이 있습니다. 각 앱에는 gRPC 클라이언트가 내장되어 ID 매핑 함수를 호출합니다. ID 매핑 앱은 앞에서 설명한 Spark Structured Streaming으로 구현된 앱입니다. Apache Kafka 토픽을 통해서 실시간으로 매핑할 유저 ID 리스트가 들어오고, 이 리스트를 파라미터로 함수를 호출해 매칭된 광고 사용자 ID를 반환받습니다.
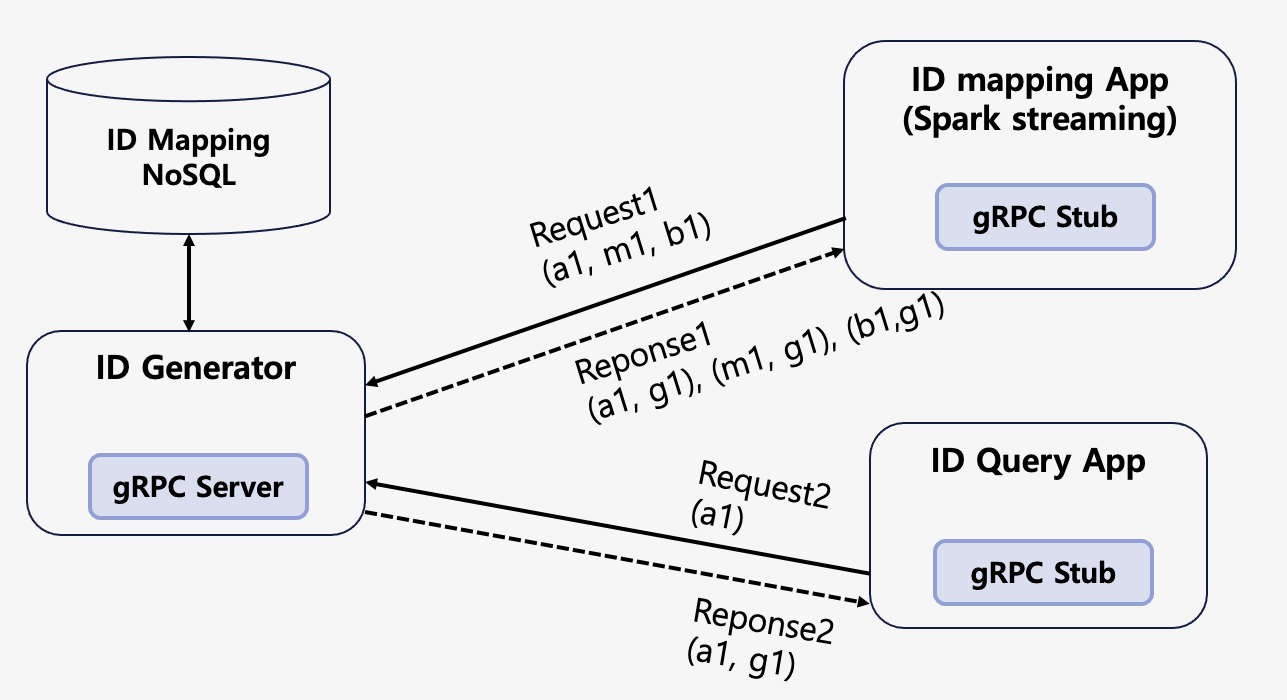
ID 생성기는 대량의 트래픽을 처리하기 위해서 클라이언트 단에서 로드 밸런싱을 하는 것으로 구성했습니다. 프록시를 이용한 로드 밸런싱은 반드시 프록시를 거쳐야 한다는 점에서 성능상의 손실이 있을 수 있습니다. 또한 gRPC는 클라이언트 단에서의 로드 밸런싱이 용이하다는 점도 주요했습니다. 서버의 목록과 간단한 몇 가지 옵션을 설정하면 로드 밸런싱을 해서 서버를 호출할 수 있습니다.
그러나 서버 목록을 얻는 것과 서버 중지, 투입 시에 목록을 갱신하는 것은 직접 구현해야 합니다. 그래서 이는 Apache ZooKeeper를 이용해서 구현했습니다. ID 생성기가 시작될 때 서버별 임시 지노드(znode)가 생성됩니다. 임시 지노드는 세션이 끊기면 삭제되기 때문에, 서버가 동작 중일 때는 임지 지노드를 유지하다 중지되면 세션이 끊기고 자동으로 삭제됩니다.
Spark Structured Streaming 앱
앞에서 설명한 것처럼, 실시간 광고 사용자 ID 매핑 시스템은 마이크로서비스 아키텍처로 Apache Kafka와 여러 Apache Spark 앱으로 구성되어 있습니다. 시스템 설계에서 설명한 Apache Spark 앱 중에서 Spark Structured Streaming 앱의 몇 가지 설정에 대해서 설명하겠습니다.
각 Spark Structured Streaming 앱은 입력과 출력에 따라 적절한 트리거 옵션을 사용해서 실행했습니다. 배치, 스트리밍 트리거 설정에 따라서 노란색 박스의 선으로 구분했습니다. 가장 왼쪽의 id extraction 앱은 입력이 실시간 데이터이고 윈도우 단위로 중복을 제거하기 때문에 fixed interval 트리거 옵션을 사용했습니다. 그리고 가장 오른쪽의 append HDFS file 앱은 출력이 HDFS이고 분석용이기 때문에 실시간 처리가 필요하지 않으므로 once 트리거 옵션을 사용했습니다.
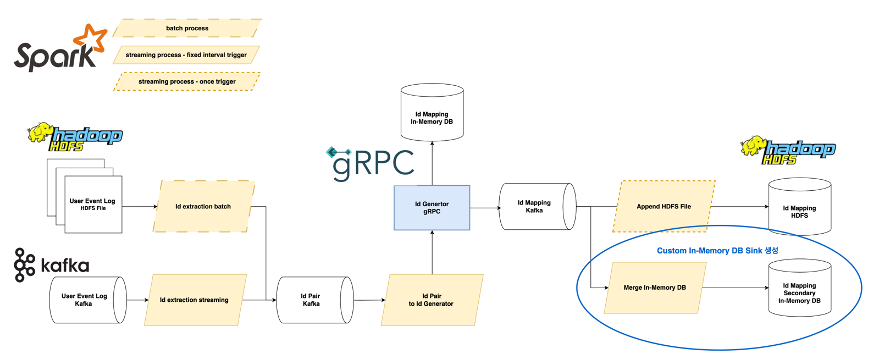
Spark Structured Streaming은 HDFS, Apache Kafka 등 몇 가지 싱크(sink) 옵션을 제공합니다. 하지만 기본 제공하지 않는 스토리지는 직접 싱크를 개발해야 됩니다. 세컨더리 인메모리 데이터베이스로 출력을 저장하는 merge in-memory db 앱에서는 직접 싱크를 개발해서 사용했습니다. 커스텀 싱크는 foreachBath로 구현할 수 있습니다. process 함수에 dataframe을 데이터베이스로 저장하는 코드를 작성할 수 있습니다. 다음은 수도 코드입니다.
df.writeStream
.outputMode(option.outputMode)
.option("checkpointLocation", option.checkpointPath)
.foreachBatch(process _)
def process(df: DataFrame, id: Long): Unit = {
import ss.implicits._
df.as[StorageRecord].foreachPartition { iter: Iterator[StorageRecord] =>
iter.grouped(batchSize).foreach(records => {
client.puts(-1, records.toList)
})
}
}
마치며
실시간 광고 사용자 ID 매핑의 강점을 정리하면 다음과 같습니다. 첫 번째로 분산 처리와 마이크로 시스템 아키텍처를 통한 확장 가능한 설계가 있습니다. 또한 gRPC를 통해서 클라이언트 앱이 늘어나도 유연하게 대처가 가능합니다. 그리고 트리 구조 알고리즘을 사용하여 ID 타입이 변경되거나 추가되어도 유연하게 대처할 수 있습니다.
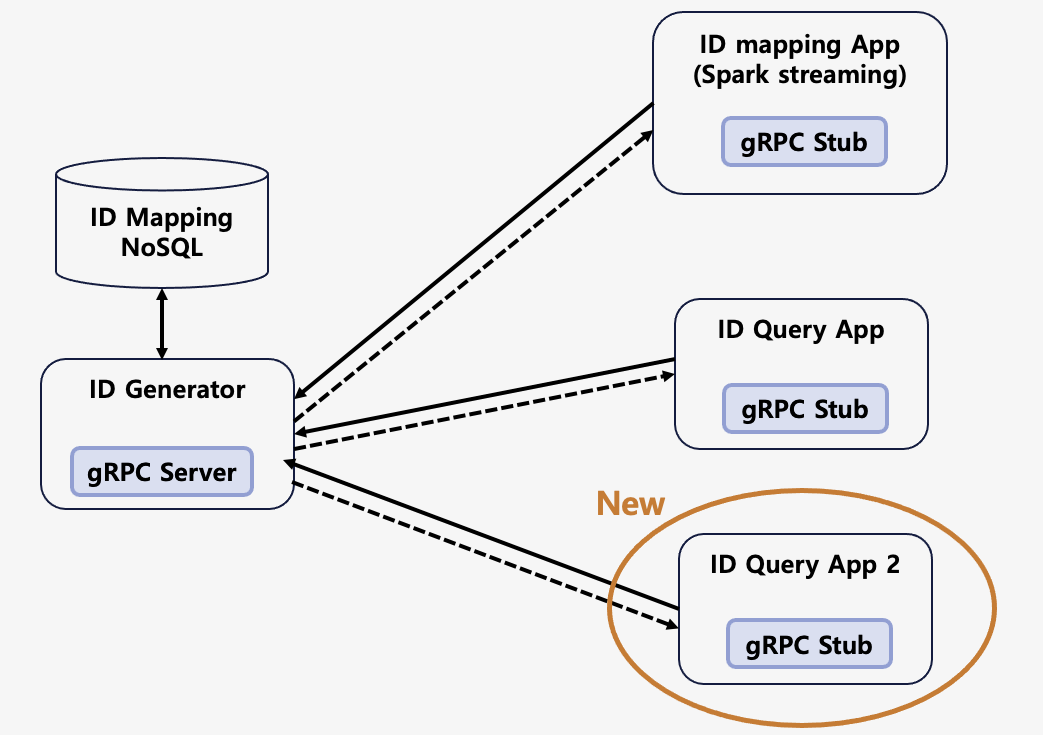
이 글을 통해서 저희가 사용자 ID 매핑을 구현하며 얻은 지식과 경험과 더불어 더 나은 서비스를 위한 인사이트를 얻으셨으면 좋겠습니다.
Info
위의 글은 사내 기술 공유 행사인 NAVER ENGINEERING DAY 2024에서 발표한 내용을 토대로 작성되었으며, 관련 영상은 링크에서 보실 수 있습니다.