How to Build a Local RAG App with Ollama and ChromaDB in the R Programming Language
How to Build a Local RAG App with Ollama and ChromaDB in the R Programming Language 관련


A Large Language Model (LLM) is a type of machine learning model that is trained to understand and generate human-like text. These models are trained on vast datasets to capture the nuances of human language, enabling them to generate coherent and contextually relevant responses.
You can enhance the performance of an LLM by providing context — structured or unstructured data, such as documents, articles, or knowledge bases — tailored to the domain or information you want the model to specialize in. Using techniques like prompt engineering and context injection, you can build an intelligent chatbot capable of navigating extensive datasets, retrieving relevant information, and delivering responses.
Whether it's storing recipes, code documentation, research articles, or answering domain-specific queries, an LLM-based chatbot can adapt to your needs with customization and privacy. You can deploy it locally to create a highly specialized conversational assistant that respects your data.
In this article, you will learn how to build a local Retrieval-Augmented Generation (RAG) application using Ollama and ChromaDB in R. By the end, you'll have a custom conversational assistant with a Shiny interface that efficiently retrieves information while maintaining privacy and customization.
What is RAG?
Retrieval-Augmented Generation (RAG) is a method that integrates retrieval systems with generative AI, enabling chatbots to access recent and specific information from external sources.
By using a retrieval pipeline, the chatbot can fetch up-to-date, relevant data and combine it with the generative model’s language capabilities, producing responses that are both accurate and contextually enriched. This makes RAG particularly useful for applications requiring fact-based, real-time knowledge delivery.
Project Overview
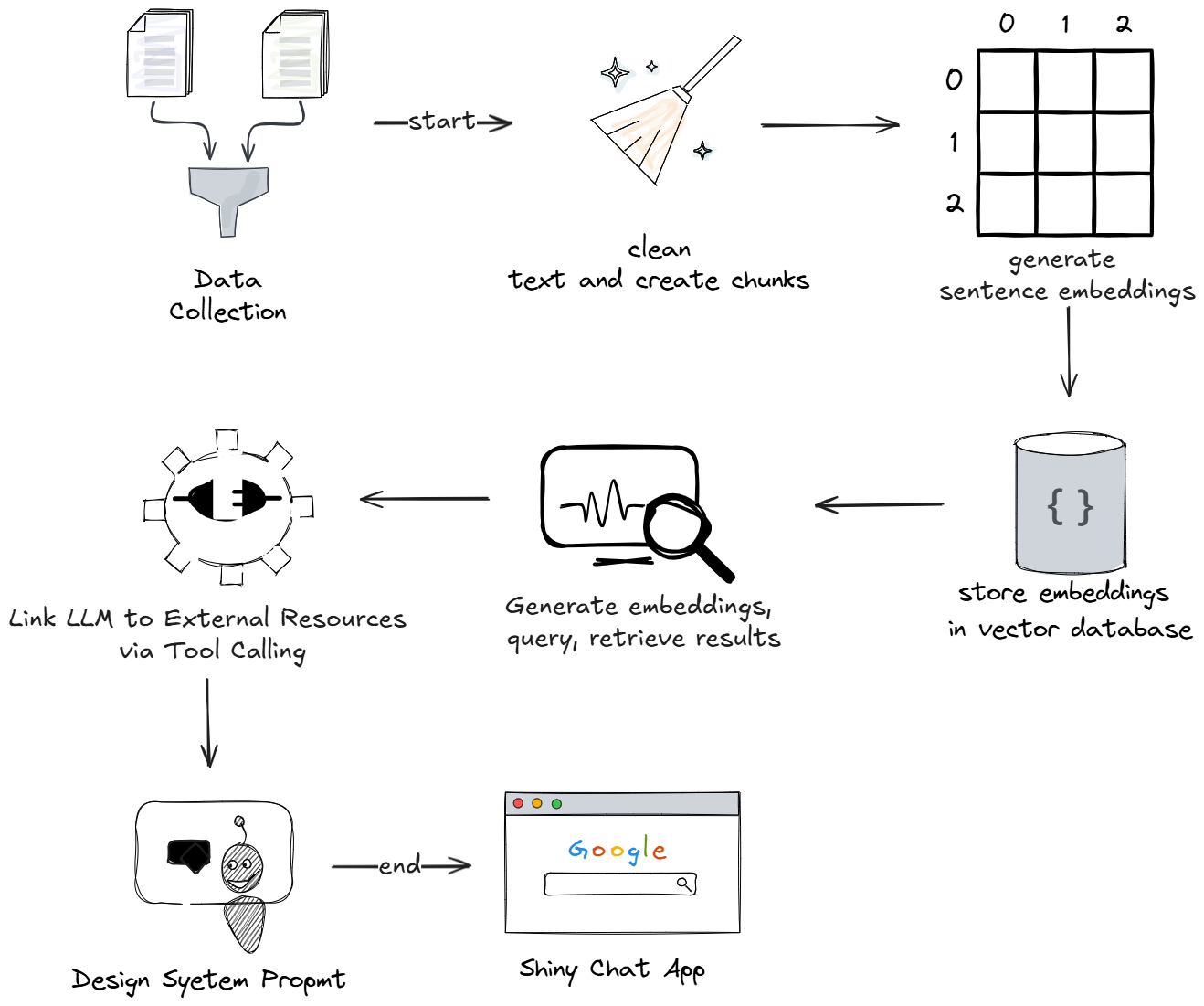
Project Setup
Prerequisites
Before you begin, ensure you have installed the latest version of the items listed here:
- RStudio: The IDE - RStudio is the primary workspace where you'll write and test your R code. Its user-friendly interface, debugging tools, and integrated environment make it ideal for data analysis and chatbot development.
- R: The Programming Language - R is the backbone of your project. You'll use it to handle data manipulation, apply statistical models, and integrate your recipe chatbot components seamlessly.
- Python - Some libraries, like the embedding library you'll use for text vectorization, are built on Python. It’s vital to have Python installed to enable these functionalities alongside your R code.
- Java - Java serves as a foundational element for certain embedding libraries. It ensures efficient processing and compatibility for text embedding tasks required to train your chatbot.
- Docker Desktop - Docker Desktop allows you to run ChromaDB, the vector database, locally on your machine. This enables fast and reliable storage of embeddings, ensuring your chatbot retrieves relevant information quickly.
- Ollama - Ollama brings powerful Large Language Models (LLMs) directly to your local computer, removing the need for cloud resources. It lets you access multiple models, customize outputs, and integrate them into your chatbot effortlessly.
Complete Code
The R scripts have been split in two, with data.R containing code that handles data gathering and cleaning, text chunking, sentence embeddings generation, creating a vector database, and loading documents to it.
The chat.R script contains code that handles user input querying, context retrieval, chat initialization, system prompt design, tool integration, and a chat Shiny app.
# install and load required packages
# install devtools from CRAN
install.packages('devtools')
devtools::install_github("benyamindsmith/RKaggle")
library(text)
library(rchroma)
library(RKaggle)
library(dplyr)
# run ChromaDB instance.
chroma_docker_run()
# Connect to a local ChromaDB instance
client <- chroma_connect()
# Check the connection
heartbeat(client)
version(client)
# Create a new collection
create_collection(client, "recipes_collection")
# List all collections
list_collections(client)
# Download and read the "recipe" dataset from Kaggle
recipes_list <- RKaggle::get_dataset("thedevastator/better-recipes-for-a-better-life")
# extract the first tibble
recipes_df <- recipes_list[[1]]
# convert to dataframe and drop the first column
recipes_df <- as.data.frame(recipes_df[, -1])
# drop unnecessary columns
cleaned_recipes_df <- subset(recipes_df, select = -c(yield,rating,url,cuisine_path,nutrition,timing,img_src))
---
## Replace NA values dynamically based on conditions
# Replace NA when all columns have NA values
cols_to_modify <- c("prep_time", "cook_time", "total_time")
cleaned_recipes_df[cols_to_modify] <- lapply(
cleaned_recipes_df[cols_to_modify],
function(x, df) {
# Replace NA in prep_time and cook_time where both are NA
replace(x, is.na(df$prep_time) & is.na(df$cook_time), "unknown")
},
df = cleaned_recipes_df
)
# Replace NA when either or columns have NA values
cleaned_recipes_df <- cleaned_recipes_df %>%
mutate(
prep_time = case_when(
# If cook_time is present but prep_time is NA, replace with "no preparation required"
!is.na(cook_time) & is.na(prep_time) ~ "no preparation required",
# Otherwise, retain original value
TRUE ~ as.character(prep_time)
),
cook_time = case_when(
# If prep_time is present but cook_time is NA, replace with "no cooking required"
!is.na(prep_time) & is.na(cook_time) ~ "no cooking required",
# Otherwise, retain original value
TRUE ~ as.character(cook_time)
)
)
# chunk the dataset
chunk_size <- 1
n <- nrow(cleaned_recipes_df)
r <- rep(1:ceiling(n/chunk_size),each = chunk_size)[1:n]
chunks <- split(cleaned_recipes_df,r)
#empty dataframe
recipe_sentence_embeddings <- data.frame(
recipe = character(),
recipe_vec_embeddings = I(list()),
recipe_id = character()
)
# create a progress bar
pb <- txtProgressBar(min = 1, max = length(chunks), style = 3)
# embedding data
for (i in 1:length(chunks)) {
recipe <- as.character(chunks[i])
recipe_id <- paste0("recipe",i)
recipe_embeddings <- textEmbed(as.character(recipe),
layers = 10:11,
aggregation_from_layers_to_tokens = "concatenate",
aggregation_from_tokens_to_texts = "mean",
keep_token_embeddings = FALSE,
batch_size = 1
)
# convert tibble to vector
recipe_vec_embeddings <- unlist(recipe_embeddings, use.names = FALSE)
recipe_vec_embeddings <- list(recipe_vec_embeddings)
# Append the current chunk's data to the dataframe
recipe_sentence_embeddings <- recipe_sentence_embeddings %>%
add_row(
recipe = recipe,
recipe_vec_embeddings = recipe_vec_embeddings,
recipe_id = recipe_id
)
# track embedding progress
setTxtProgressBar(pb, i)
}
# Add documents to the collection
add_documents(
client,
"recipes_collection",
documents = recipe_sentence_embeddings$recipe,
ids = recipe_sentence_embeddings$recipe_id,
embeddings = recipe_sentence_embeddings$recipe_vec_embeddings
)
# Load required packages
library(ellmer)
library(text)
library(rchroma)
library(shinychat)
ui <- bslib::page_fluid(
chat_ui("chat")
)
server <- function(input, output, session) {
# Connect to a local ChromaDB instance running on docker with embeddings loaded
client <- chroma_connect()
# sentence embeddings function and query
question <- function(sentence){
sentence_embeddings <- textEmbed(sentence,
layers = 10:11,
aggregation_from_layers_to_tokens = "concatenate",
aggregation_from_tokens_to_texts = "mean",
keep_token_embeddings = FALSE
)
# convert tibble to vector
sentence_vec_embeddings <- unlist(sentence_embeddings, use.names = FALSE)
sentence_vec_embeddings <- list(sentence_vec_embeddings)
# Query similar documents
results <- query(
client,
"recipes_collection",
query_embeddings = sentence_vec_embeddings ,
n_results = 2
)
results
}
# function that provides context
tool_context <- tool(
question,
"obtains the right context for a given question",
sentence = type_string()
)
# Initialize the chat system
chat <- chat_ollama(system_prompt = "You are a knowledgeable culinary assistant specializing in recipe recommendations.
You provide tailored meal suggestions based on the user's available ingredients and the desired amount of food or servings.
Ensure the recipes align closely with the user's inputs and yield the expected quantity.",
model = "llama3.2:3b-instruct-q4_K_M")
#register tool
chat$register_tool(tool_context)
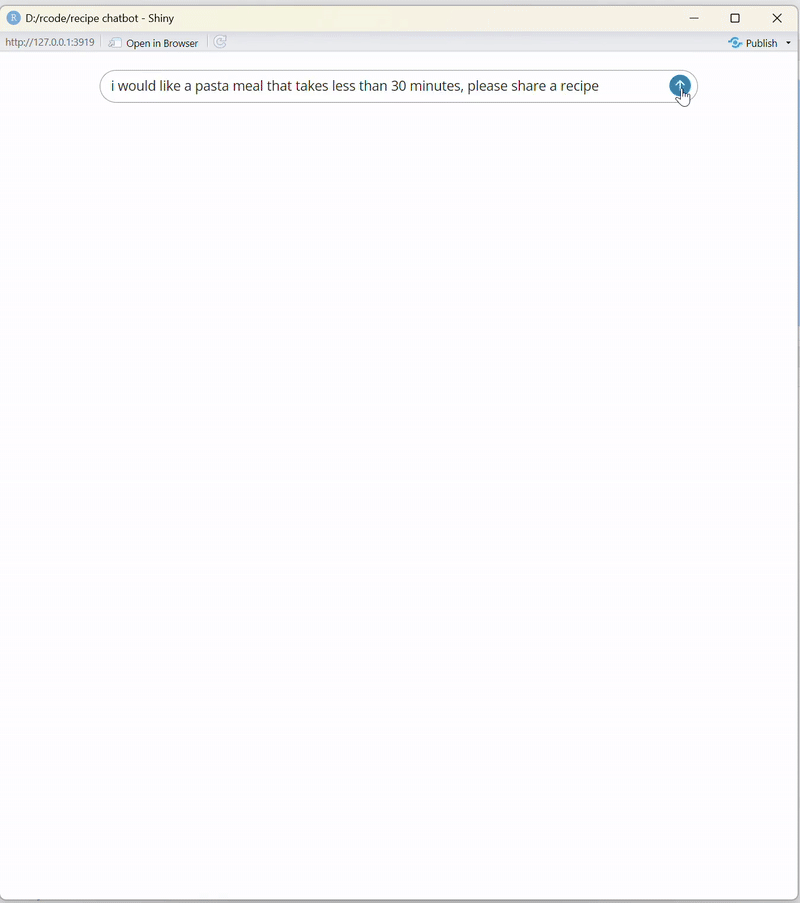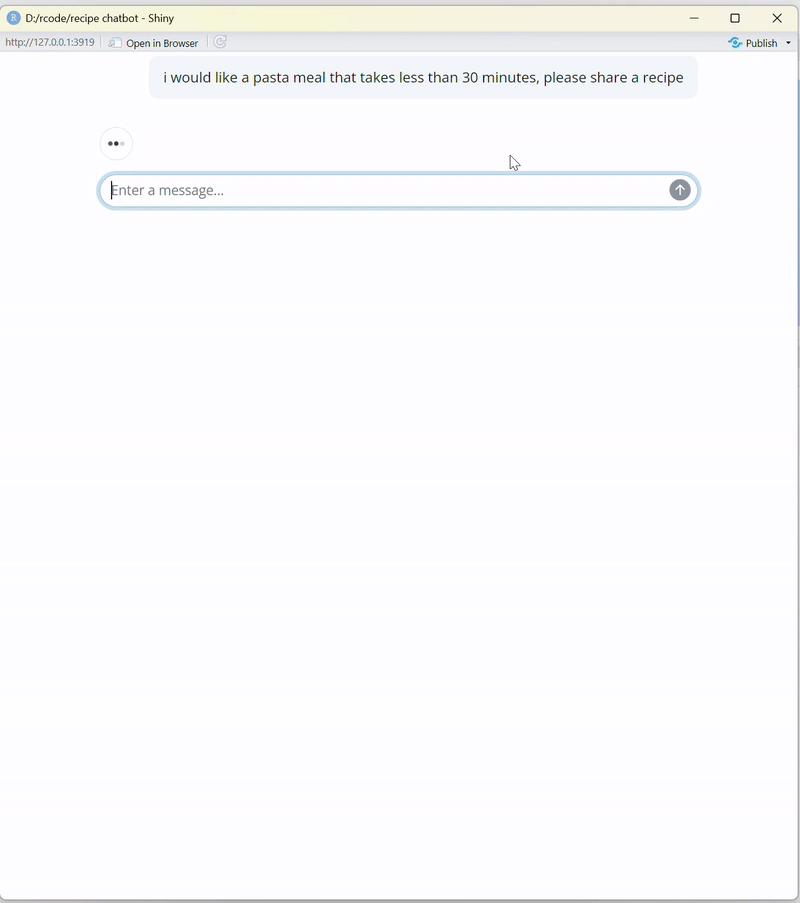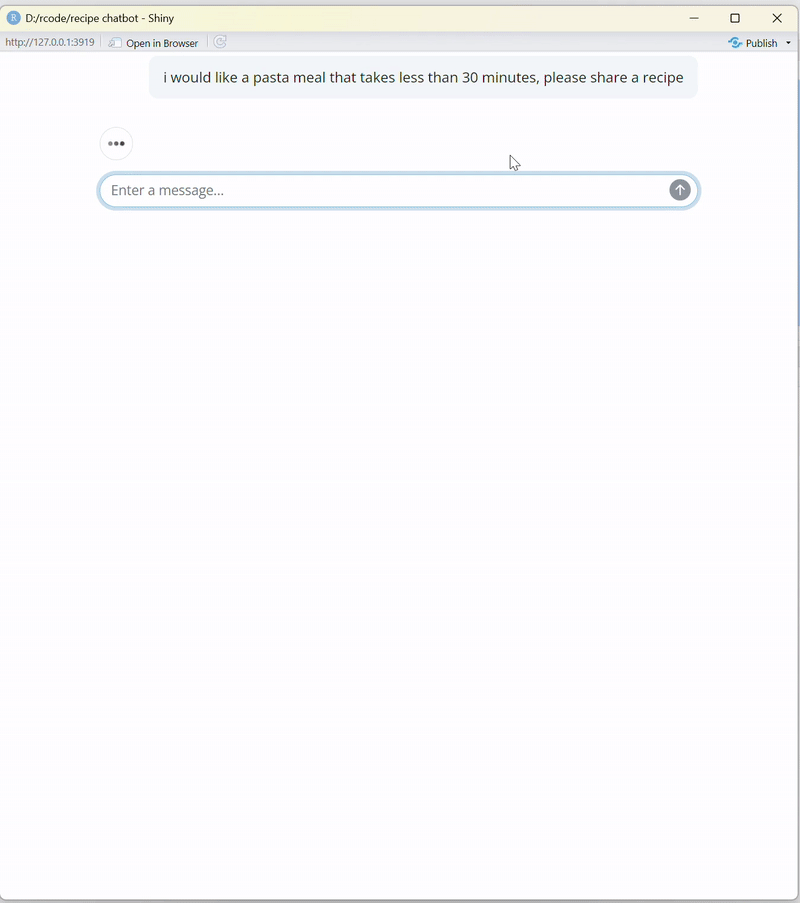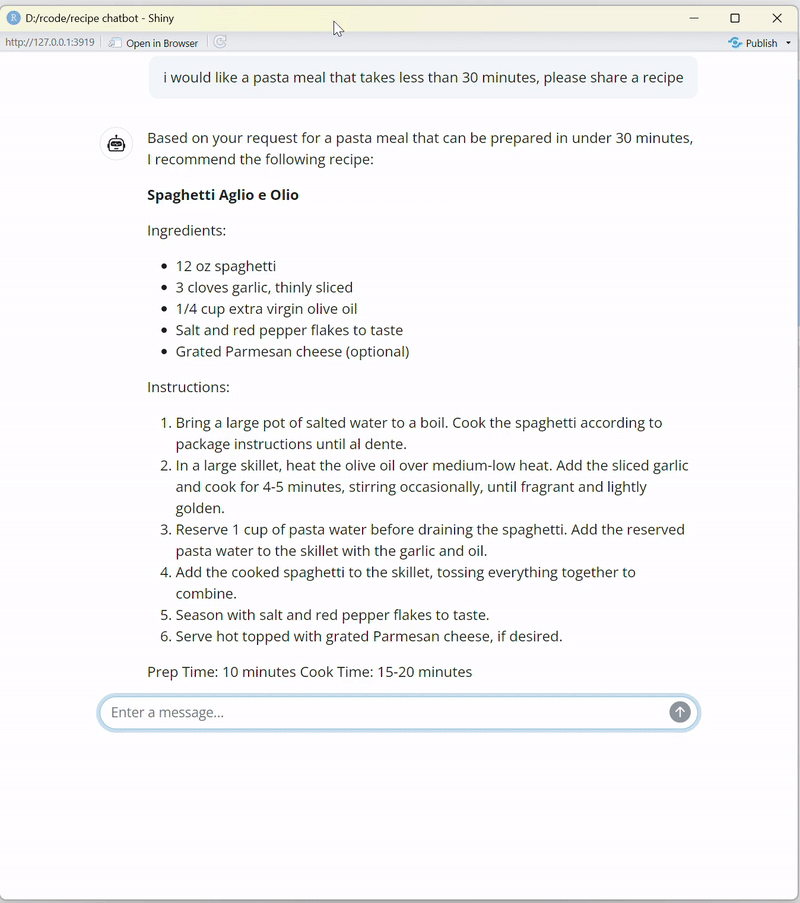
observeEvent(input$chat_user_input, {
stream <- chat$stream_async(input$chat_user_input)
chat_append("chat", stream)
})
}
shinyApp(ui, server)
You can find the complete code here (elabongaatuo/Recipe-Chatbot).
Conclusion
Building a local Retrieval-Augmented Generation (RAG) application using Ollama and ChromaDB in R programming offers a powerful way to create a specialized conversational assistant.
By leveraging the capabilities of large language models and vector databases, you can efficiently manage and retrieve relevant information from extensive datasets.
This approach not only enhances the performance of language models but also ensures customization and privacy by running the application locally.
Whether you're developing a cooking assistant or any other domain-specific chatbot, this method provides a robust framework for delivering intelligent and contextually aware responses.