
Building Async APIs in ASP.NET Core - The Right Way
Building Async APIs in ASP.NET Core - The Right Way 관련


Most APIs follow a simple pattern. The client sends a request. The server does some work. The server sends back a response.
This works well for fast operations like fetching data or simple updates. But what about operations that take longer?
Think about processing large files, generating reports, or converting videos. These operations can take minutes or even hours.
Making clients wait for these operations causes problems.
Understanding Async APIs
The key to handling long-running operations is to change how we think about API responses. An async API splits work into two parts:
- Accept the request
- Process it later
First, we accept the request and return a tracking ID immediately. This gives users a quick response. Then, we process the actual work in the background, which won't block other requests. Users can check the status of their request using the tracking ID whenever they want.
This is different from async/await in C#. That's about handling many requests at once (concurrently). This is about handling long-running tasks better. We're not just making the code asynchronous - we're making the entire operation asynchronous from the user's perspective.
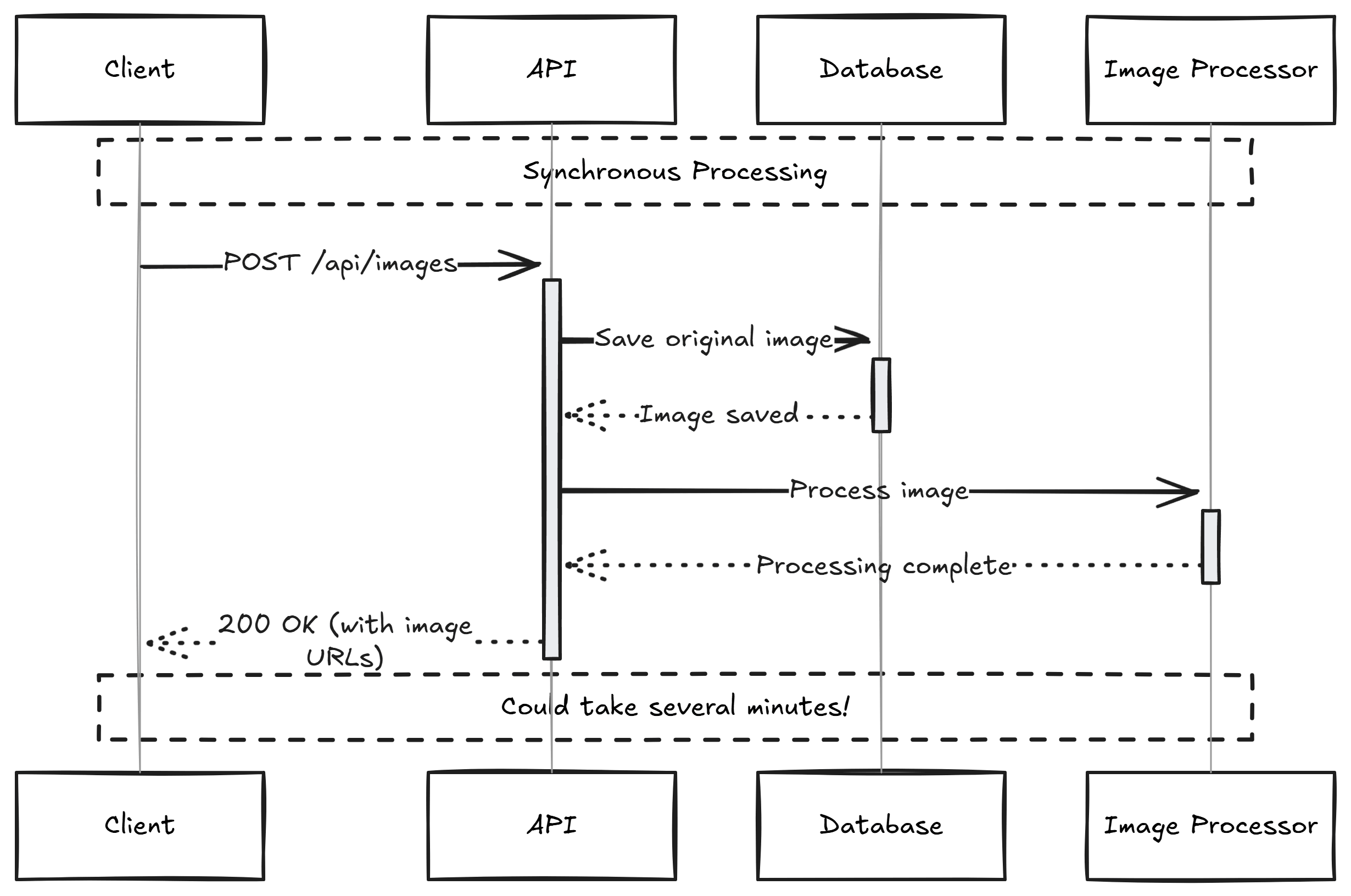
The Problem with Sync APIs
Let's see this in practice with image processing. A typical image upload API might look like this:
[HttpPost]
public async Task<IActionResult> UploadImage(IFormFile file)
{
if (file is null)
{
return BadRequest();
}
// Save original image
var originalPath = await SaveOriginalAsync(file);
// Generate thumbnails
var thumbnails = await GenerateThumbnailsAsync(originalPath);
// Optimize all images
await OptimizeImagesAsync(originalPath, thumbnails);
return Ok(new { originalPath, thumbnails });
}
The client must wait while we save the file, generate thumbnails, and optimize images. On a slow connection or with a large file, this request could time out. The server is also stuck processing one image at a time.
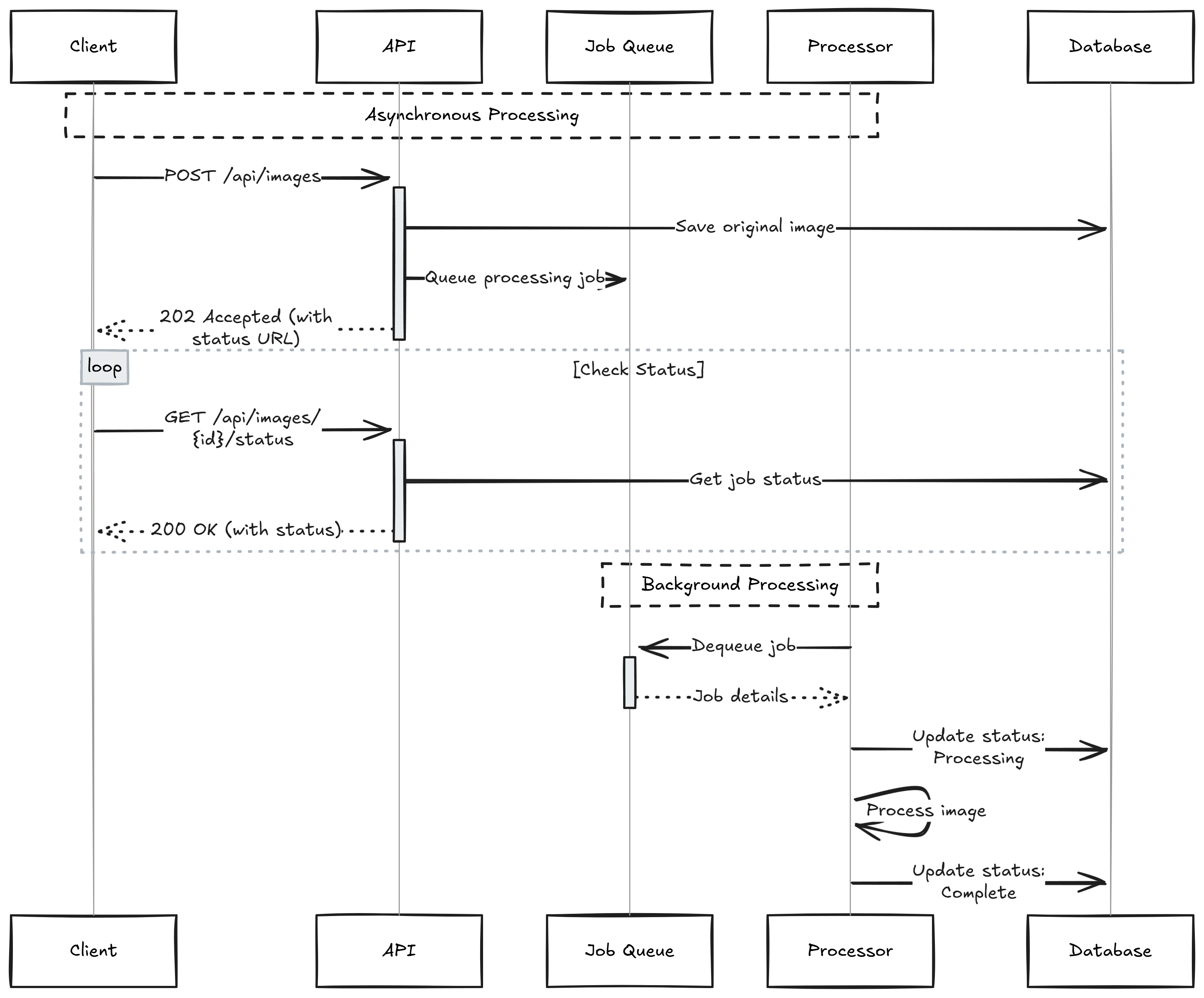
A Better Way: Async Processing
Let's fix these problems. We'll split the work into two parts:
- Accept the upload and return quickly
- Do the heavy work in the background
Uploading Images
Here's the new upload endpoint:
[HttpPost]
public async Task<IActionResult> UploadImage(IFormFile? file)
{
if (file is null)
{
return BadRequest("No file uploaded.");
}
if (!imageService.IsValidImage(file))
{
return BadRequest("Invalid image file.");
}
// Phase 1: Accept the work
var id = Guid.NewGuid().ToString();
var folderPath = Path.Combine(_uploadDirectory, "images", id);
var fileName = $"{id}{Path.GetExtension(file.FileName)}";
var originalPath = await imageService.SaveOriginalImageAsync(
file,
folderPath,
fileName
);
// Queue Phase 2 for background processing
var job = new ImageProcessingJob(id, originalPath, folderPath);
await jobQueue.EnqueueAsync(job);
// Return status URL immediately
var statusUrl = GetStatusUrl(id);
return Accepted(statusUrl, new { id, status = "queued" });
}
This new version only saves the original file during the HTTP request. The heavy work moves to a background process. The client immediately gets a status URL in the Location header instead of waiting.
Checking Progress
Clients can check their image's status using a separate endpoint:
[HttpGet("{id}/status")]
public IActionResult GetStatus(string id)
{
if (!statusTracker.TryGetStatus(id, out var status))
{
return NotFound();
}
var response = new
{
id,
status,
links = new Dictionary<string, string>()
};
if (status == "completed")
{
response.links = new Dictionary<string, string>
{
["original"] = GetImageUrl(id),
["thumbnail"] = GetThumbnailUrl(id, width: 200),
["preview"] = GetThumbnailUrl(id, width: 800)
};
}
return Ok(response);
}
Processing Images in Background
The real work happens in the background processor. While the API handles new requests, a separate process works through the queued jobs. This separation gives us flexibility in how we handle the processing.
For single-server deployments, we can use .NET's Channel type to queue jobs in memory:
public class JobQueue
{
private readonly Channel<ImageProcessingJob> _channel;
public JobQueue()
{
var options = new BoundedChannelOptions(1000)
{
FullMode = BoundedChannelFullMode.Wait
};
_channel = Channel.CreateBounded<ImageProcessingJob>(options);
}
public async ValueTask EnqueueAsync(ImageProcessingJob job,
CancellationToken ct = default)
{
await _channel.Writer.WriteAsync(job, ct);
}
public IAsyncEnumerable<ImageProcessingJob> DequeueAsync(
CancellationToken ct = default)
{
return _channel.Reader.ReadAllAsync(ct);
}
}
For multi-server setups, we need a distributed queue like RabbitMQ or even Redis.
The background processor handles the time-consuming work:
public class ImageProcessor : BackgroundService
{
protected override async Task ExecuteAsync(CancellationToken ct)
{
await foreach (var job in jobQueue.DequeueAsync(ct))
{
try
{
await statusTracker.SetStatusAsync(
job.Id,
"processing"
);
// Generate thumbnails
await GenerateThumbnailsAsync(
job.OriginalPath,
job.OutputPath
);
// Optimize images
await OptimizeImagesAsync(
job.OriginalPath,
job.OutputPath
);
await statusTracker.SetStatusAsync(
job.Id,
"completed"
);
}
catch (Exception ex)
{
await statusTracker.SetStatusAsync(
job.Id,
"failed"
);
logger.LogError(ex, "Failed to process image {Id}", job.Id);
}
}
}
}
The background processor needs to handle failures gracefully. We can improve resilience by adding a retry policy with Polly. Status updates keep users informed throughout the process. Instead of just "processing", we tell them exactly what's happening. This improves the user experience and helps with debugging.
Beyond Polling: Real-Time Updates
Our status endpoint works, but it puts the burden on clients. They must repeatedly check for updates, leading to unnecessary server load. A client polling every second creates 60 requests per minute, yet most of these requests return the same status.
We can flip this model around. Instead of clients asking for updates, the server can push updates when they happen. This creates a more efficient and responsive system.
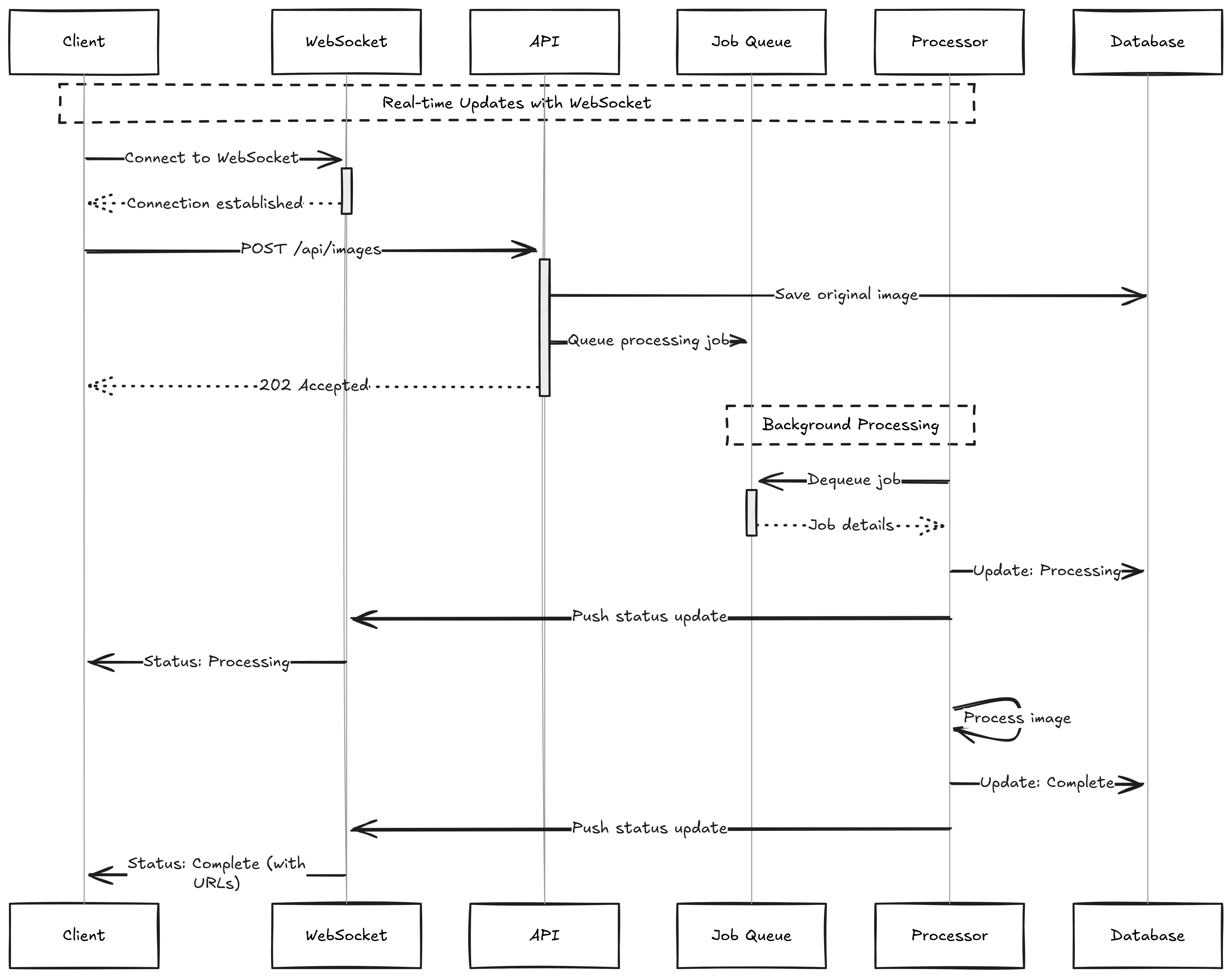
SignalR and WebSockets enable real-time communication between server and client. When a job's status changes, the server immediately notifies interested clients. This approach reduces network traffic and gives users instant feedback.
For longer-running jobs, email notifications make more sense. Users don't need to keep their browsers open. They can close the tab and come back when notified. This works well for reports that take hours to generate or batch processes that run overnight.
Webhooks offer another option, especially for system-to-system communication. When a job completes, your server can notify other systems. This enables workflow automation and system integration without constant polling.
Summary
Processing tasks asynchronously creates better experiences for everyone. Users get immediate responses instead of watching spinning loading indicators. They can start other tasks while waiting, and they'll know if something goes wrong.
The benefits extend beyond user experience. Servers can handle more requests because they're not tied up with long-running tasks. Background processors can retry failed operations without affecting the main application. You can even scale your processing separately from your web servers.
Error handling improves too. When a long operation fails halfway through, you can save the progress and try again. Users know exactly what's happening because they can check the status. The system stays stable because one slow operation can't bring down your entire API.
That's all for today. Hope this was helpful.