
HDFS 쓰기 파이프라인을 활용한 HBase의 WAL 쓰기 최적화
HDFS 쓰기 파이프라인을 활용한 HBase의 WAL 쓰기 최적화 관련


네이버 검색에서는 검색 서비스 제공에 필요한 대규모 데이터를 HBase 기반의 데이터 저장소인 Cuve에 저장하고 있습니다. HBase는 Java 기반의 오픈 소스 NoSQL 분산 데이터베이스입니다. HDFS와 함께 사용되며 내구성(durability)과 지속성(persistence)을 보장합니다. 지연 시간이 매우 짧고 거의 실시간에 가까운 랜덤 읽기와 랜덤 쓰기를 지원합니다.
HBase 쓰기 경로는 다음과 같습니다.
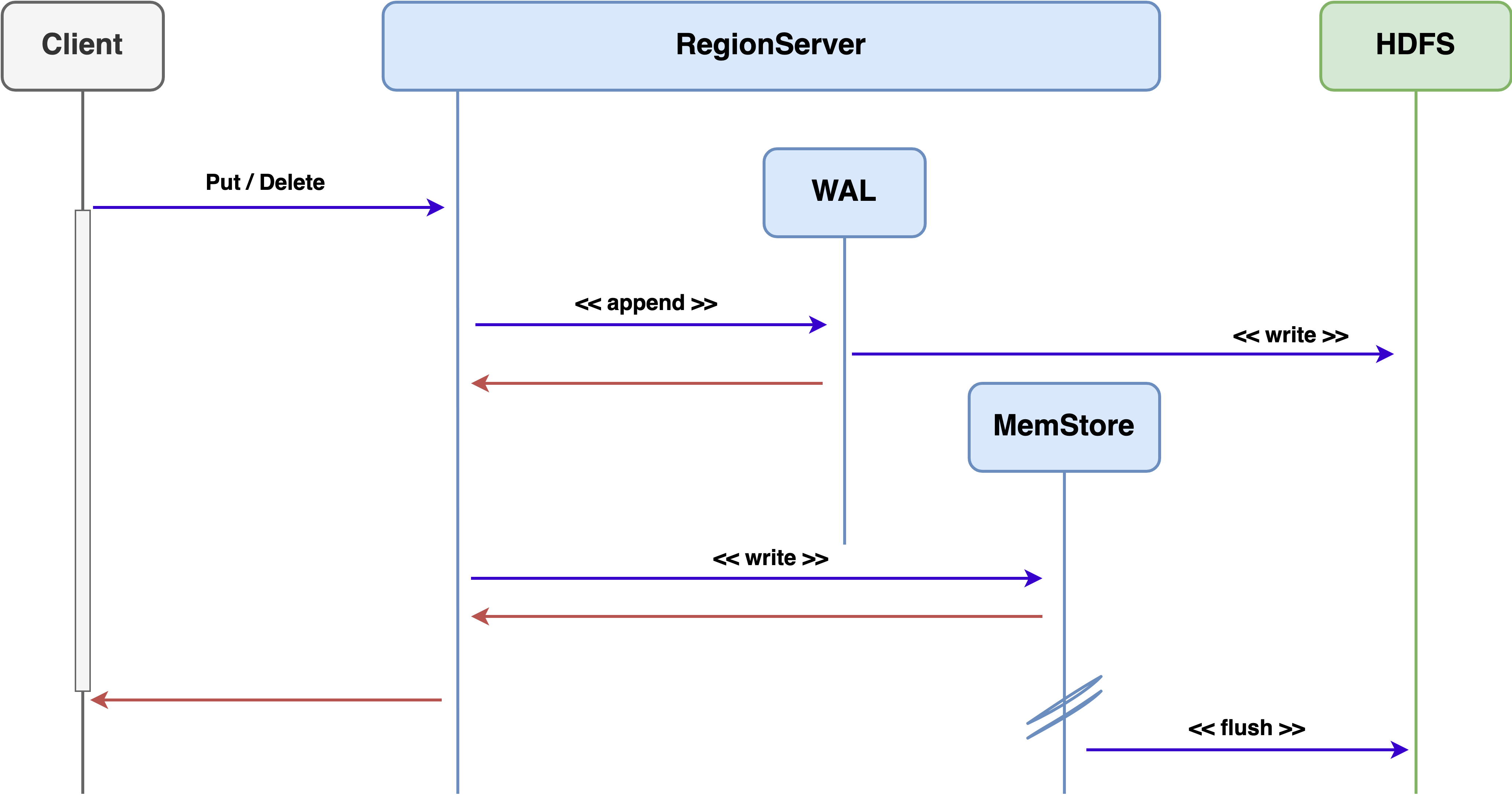
HBase는 쓰기 요청을 처리할 때 HDFS에 데이터를 바로 쓰지 않고 RegionServer의 MemStore라고 불리는 메모리 영역에 데이터를 먼저 저장합니다. MemStore에 저장된 데이터는 Flush 과정을 통해서 주기적으로 HDFS에 저장됩니다. HDFS에 데이터를 저장하기 전에 서버에 장애가 발생한다면 메모리 영역인 MemStore에 저장된 데이터는 유실될 수 있습니다. HBase는 데이터 유실을 방지하기 위해 WAL(Write-Ahead Log)에 모든 변경 사항을 기록합니다.
WAL은 MySQL의 BIN 로그와 비슷하게 모든 변경 사항을 로그에 기록하여 데이터 내구성을 보장하는 방법입니다. 변경 사항은 일반적으로 영구적인 데이터 저장 장치(예: HDD, SSD 등)에 저장하는데 HBase는 HDFS에 저장합니다. 서버에 장애가 발생하여 메모리의 모든 데이터가 유실되어도 WAL을 이용해 복구할 수 있습니다.
HBase 버전 1에서는 HDFS가 제공하는 DFSOutputStream을 통해서 WAL 데이터를 HDFS에 저장했습니다. 하지만 HDFS 쓰기 파이프라인을 따라 데이터가 3개의 DataNode에 쓰이다 보니 지연 시간이 증가하는 문제와 WAL 데이터를 쓰는 과정에서 오류가 발생했을 때 파이프라인 복구 실패로 인해 사용자 요청 처리가 지연되는 문제가 있었습니다. Cuve에서도 HBase 버전 1 클러스터에서 WAL 데이터 쓰기 파이프라인 복구 실패로 사용자의 요청을 처리하지 못하여 SLA를 위반하는 장애가 발생했었습니다. HBase 버전 2에서는 HBase에 WAL 쓰기 전용 Fan-out DFSOutputStream이 구현되어 이러한 문제가 해결되었습니다.
이 글에서는 Cuve에서 HBase 버전 1 기반으로 운영하던 HBase 클러스터에서 어떤 오류가 발생했는지 알아보고 HDFS 쓰기 파이프라인과 HBase의 Fan-out DFSOutputStream에서 HDFS 프로토콜을 어떻게 활용했는지 알아보겠습니다.
이 글은 HDFS와 HBase에 대한 기본적인 개념과 사용법에 익숙하다고 가정하고 있습니다. HDFS와 HBase의 구성 요소와 특징은 Hadoop 문서 HDFS Architecture와 HBase 문서 Architecture Overview를 참고하기 바랍니다.
파이프라인 복구 실패로 인한 장애 상황
HBase 버전 1의 RegionServer는 HDFS가 제공하는 DFSOutputStream을 통해 WAL 데이터를 쓴다. HDFS 클라이언트는 데이터를 쓰다가 DataNode에서 오류가 발생하면 클라이언트가 파일에 데이터를 계속 쓸 수 있도록 파이프라인을 복구한다. 네트워크 상태가 좋지 않거나 DataNode의 디스크가 고장 나는 경우 DataNode에서 오류가 발생할 수 있다.
WAL 데이터를 쓰는 도중 DataNode에 오류가 발생하면 파이프라인 복구가 시작되는데, 파이프라인 복구가 실패하여 RegionServer가 사용자의 요청을 처리하지 못하는 현상이 발생했었다. 파이프라인 복구에 실패했을 때 어떤 현상이 발생하는지 Cuve 사례를 통해 알아보겠다.
Cuve에서 운영하던 HBase 버전 1 클러스터의 RegionServer에서 WAL 데이터를 쓰는 도중 아래 RegionServer 오류 로그같이 IOException 오류가 발생했었다.
RegionServer 오류 로그
2023-XX-XX XX:XX:XX,XXX WARN [DataStreamer for file ...:blk_...] hdfs.DFSClient: DataStreamer Exception
java.io.IOException: Broken pipe
at org.apache.hadoop.hdfs.DFSPacket.writeTo(DFSPacket.java)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java)
파이프라인에서 오류가 발생하면 파이프라인 복구를 위해 오류가 발생한 DataNode는 파이프라인에서 제외되는데, 위와 같이 OutputStream에 데이터를 쓸 때 오류가 발생한 경우 오류가 발생한 DataNode를 식별할 수 없다. HDFS 클라이언트는 OutputStream에 데이터를 쓸 때 오류가 발생하면 아래 DFSOutputStream 코드 일부와 같이 tryMarkPrimaryDatanodeFailed() 메서드를 호출한다.
DFSOutputStream 코드 일부
try {
one.writeTo(blockStream); // IOException이 발생한 위치
blockStream.flush();
} catch (IOException e) {
tryMarkPrimaryDatanodeFailed();
throw e;
}
tryMarkPrimaryDatanodeFailed() 메서드는 아래 tryMarkPrimaryDatanodeFailed 메서드 구현 내용과 같이 오류가 발생한 DataNode가 식별되지 않은 경우 항상 파이프라인의 첫 번째 DataNode를 오류가 발생한 DataNode로 설정한다. 그 이유는 클라이언트에서 오류가 발생했을 때 errorIndex가 없으면 DataNode 오류가 아닌 클라이언트의 오류로 취급되는데, 클라이언트 오류로 취급되면 더 이상 재시도하지 않고 클라이언트가 종료될 수 있기 때문이다. OutputStream에서 데이터를 쓰다가 발생한 오류는 클라이언트 오류가 아닌 DataNode 오류이기 때문에, 오류가 발생한 DataNode가 식별되지 않은 경우 첫 번째 DataNode를 오류가 발생한 DataNode로 설정함으로써 오류가 DataNode 오류로 처리되고 파이프라인을 복구하게 한다.
tryMarkPrimaryDatanodeFailed 메서드 구현 내용
synchronized void tryMarkPrimaryDatanodeFailed() {
if ((errorIndex == -1) && (restartingNodeIndex.get() == -1)) {
errorIndex = 0; // errorIndex = 오류가 발생한 DataNode의 인덱스
}
}
tryMarkPrimaryDatanodeFailed() 메서드에 의해 첫 번째 DataNode를 오류가 발생한 DataNode로 인식한 HDFS 클라이언트는 파이프라인 복구를 위해 첫 번째 DataNode를 제외하고 새 파이프라인을 구성하려고 시도했다.
첫 번째 DataNode를 오류가 발생한 DataNode로 인식한 로그
Error Recovery for block ... in pipeline DatanodeInfoWithStorage[...], DatanodeInfoWithStorage[...], DatanodeInfoWithStorage[...]: datanode 0(DatanodeInfoWithStorage[...]) is bad.
하지만 파이프라인 구성에 실패했다. 이후 계속해서 파이프라인 복구를 다시 시도했지만 파이프라인 복구에 성공하지 못했다. 계속된 파이프라인 복구 실패로 인해 해당 RegionServer는 그림 2와 같이 RPC Handler가 꽉 차서 사용자의 요청을 제대로 처리하지 못했다.
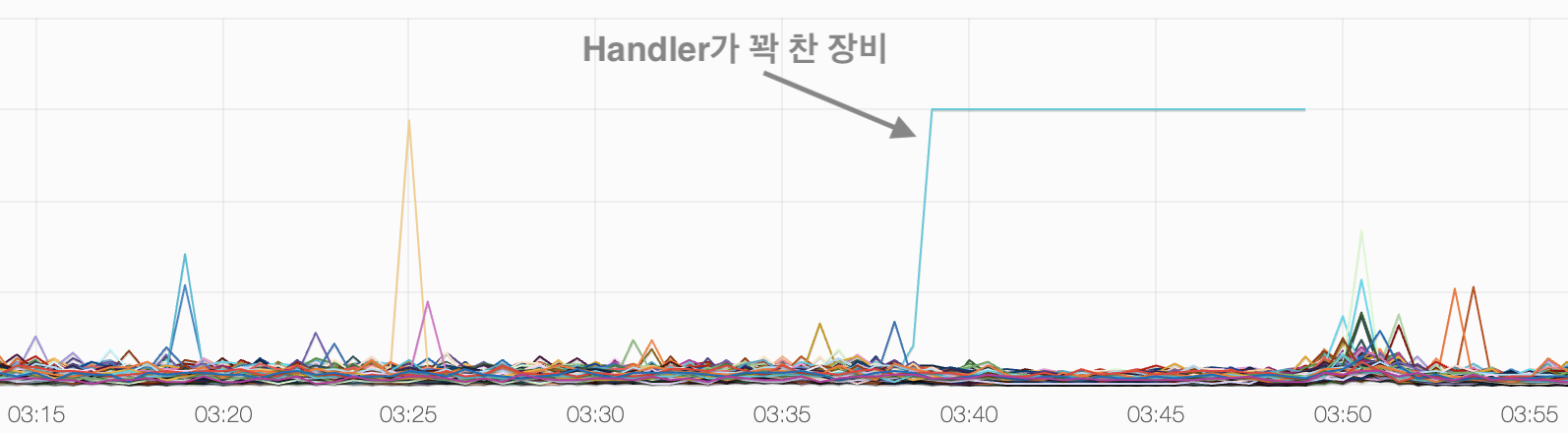
hbase.regionserver.ipc.numActiveHandler 지표장애 상황 이후 NameNode, DataNode, RegionServer의 로그를 확인해 보니 실제 오류가 발생했던 DataNode는 파이프라인의 마지막 DataNode였다. 오류가 발생한 DataNode를 잘못 식별하여 파이프라인 복구가 계속 실패했던 것으로 추정된다.
위와 같은 오류가 발생하면 운영자가 개입하여 해당 RegionServer를 재시작해야 오류가 해결되었다. 매번 운영자가 개입할 수 없기 때문에 자동화 처리도 했지만 근본적인 문제 해결은 아니었다. 따라서 장애 상황에 대한 이해를 높이고 해결 방법을 모색하고자 HDFS 쓰기 파이프라인과 동일한 문제가 상위 버전에서는 혹시 해결되었는지 알아보았다.
HDFS 쓰기 파이프라인
HDFS는 Hadoop의 기본(default) 파일 시스템이다. HDFS는 파일을 블록(Block)으로 나누어 DataNode에 저장하고 메타데이터는 NameNode에 저장한다. 데이터의 내결함성(fault tolerance)을 제공하기 위해 블록은 여러 DataNode에 복제되는데, 복제본의 수를 Replication Factor라고 하며 기본값은 3이다. DataNode에 물리적으로 저장된 블록은 Replica라고 부른다.
Replica에는 다음과 같은 5가지 상태가 존재한다.
- Replica의 데이터가 변경되지 않는 상태이다.
- Append를 위해 다시 Replica를 열지 않으면, 새로운 데이터가 Replica에 기록되지 않는다.
- Generation stamp(단조롭게 증가하는 숫자로, 블록의 오래된 Replica를 감지하기 위한 용도)가 동일한 Finalized Replica는 동일한 데이터를 가지고 있다.
Replica Being Written to
- 생성되거나 Append에 의해 데이터가 쓰이고 있는 Replica이다.
- 열린 파일의 마지막 블록은 항상 RBW이다.
Replica Waiting to be Recovered
- DataNode가 죽었다가 다시 시작된 경우 모든 RBW Replica는 RWR 상태로 변경된다.
- RWR Replica는 더 이상 쓸모가 없어져서 버려지거나 복구 과정에 참여한다.
Replica Under Recovery
- 복구 과정에 참여한 Replica이다.
- 블록 복제(Replication 모니터나 Cluster Balancer에 의해 생성)를 위해 생성된 Replica이다.
다음 그림은 HDFS 쓰기 파이프라인과 컴포넌트들이 서로 통신할 때 사용하는 프로토콜을 보여준다.
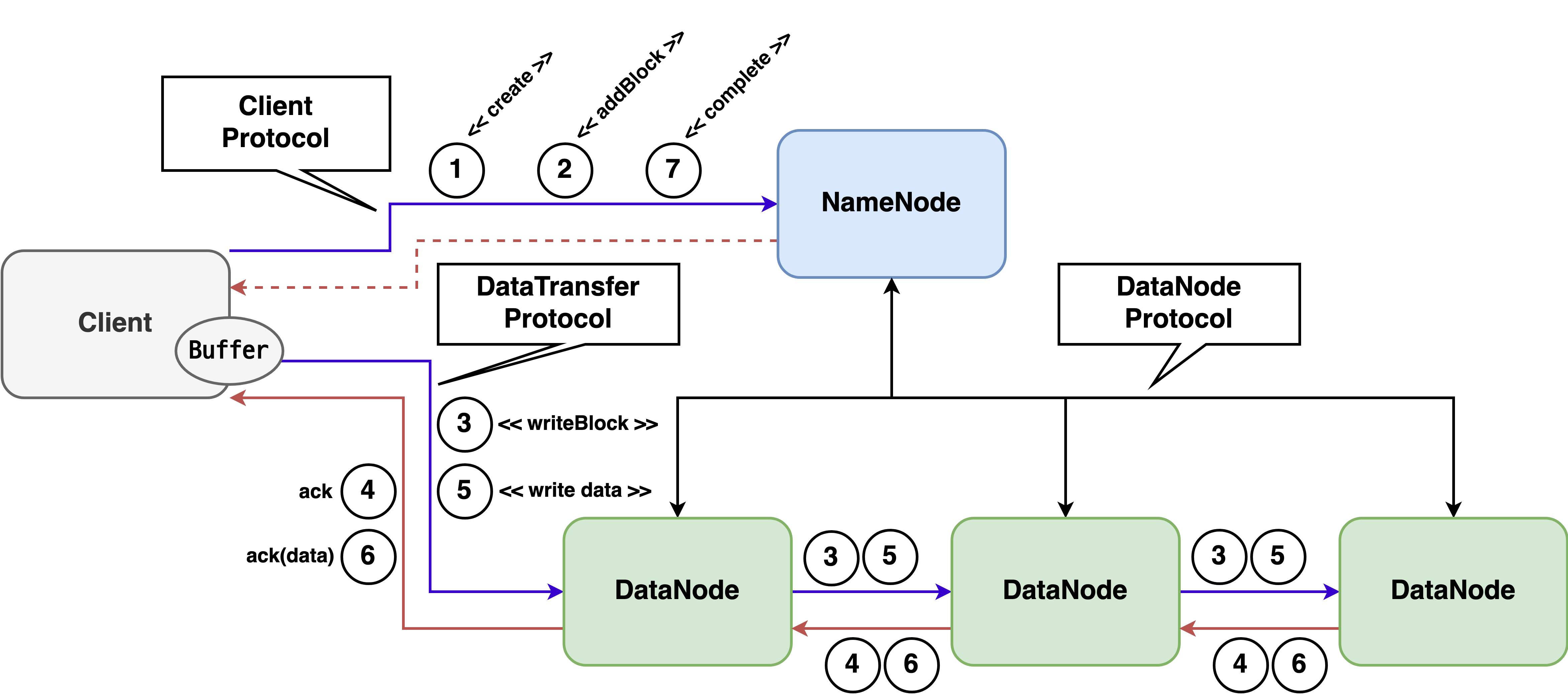
컴포넌트들은 TCP/IP 위에 설계된 프로토콜을 사용해서 서로 통신한다. Client Protocol (apache/hadoop)은 클라이언트와 NameNode 간의 통신을 위해 정의된 프로토콜이다. 클라이언트는 Client Protocol을 사용하여 새로운 파일을 만들거나 기존 파일을 관리(예: 블록 할당, 이름 변경, 삭제, 권한 설정 등)할 수 있다. 클라이언트가 데이터를 읽거나 쓰기 위해서는 DataNode와 통신을 해야 하는데 DataNode와 통신할 때는 DataTransfer Protocol (apache/hadoop)을 사용한다. Datanode Protocol (apache/hadoop)은 DataNode와 NameNode 간의 통신을 위해 정의된 프로토콜이다. DataNode에서 NameNode로 블록 리포트 등을 보낼 때 사용된다.
각 Protocol의 요청과 응답 데이터는 Protocol Buffer를 통해 직렬화, 역직렬화된다. Protocol Buffer는 구조화된 데이터를 직렬화, 역직렬화하는 방법을 제공한다. .proto 파일에 데이터가 어떻게 구조화되어 있는지 정의하고 Protobuf Compiler로 컴파일하면 데이터를 직렬화, 역직렬화할 수 있는 특수한 코드를 다양한 언어별로 생성할 수 있다. Protobuf Compiler가 생성한 코드를 사용하면 다양한 플랫폼과 언어에서 쉽게 데이터를 직렬화, 역직렬화가 가능하다.
Protocol 별 주요 기능
- 파일 관련
create: 네임스페이스에 새로운 파일 항목(Entry)을 만든다.append: 파일 끝에 추가한다.setPermission: 파일이나 디렉터리에 권한을 설정한다.setOwner: 경로(파일이나 디렉터리)에 소유자를 설정한다.addBlock: 쓰기를 위해 열려있는 파일에 블록을 쓰기 위해 호출한다. 새로운 블록과 블록을 복제할 DataNode를 할당받는다.complete: 클라이언트가 파일에 데이터 쓰기를 완료했을 때 호출한다.
- 네임스페이스 관련
rename: 네임스페이스의 파일이나 디렉터리 이름을 바꾼다.delete: 파일이나 디렉터리를 삭제한다.mkdirs: 새로운 디렉터리를 만든다.
- 시스템 관련
renewLease: 파일에 대한 변경 권한을 잃지 않기 위해 NameNode에 살아있다고 보고한다.recoverLease: Lease를 복구한다.
readBlock: 블록을 읽는다.writeBlock: DataNode 파이프라인에 블록을 쓴다.
registerDatanode: DataNode를 등록한다.sendHeartbeat: NameNode에 DataNode가 살아있음을 알리기 위해 Heartbeat 요청을 보낸다.blockReport: 블록 리포트를 보낸다.
새로운 파일 항목 생성
클라이언트가 HDFS에 새로운 파일을 생성하여 데이터를 쓰기 위해서는 먼저 네임스페이스에 새로운 파일 항목을 만들어야 한다. 새로운 파일 항목을 만들기 위해 클라이언트는 NameNode에 create 요청(그림 3의 1)을 보낸다.
message CreateRequestProto {
// 파일 경로
src: "/test_dir/file.txt"
// 클라이언트명
clientName: "DFSClient_..."
// File create semantic (CreateFlag)
createFlag: 3
// 부모 디렉터리 생성 여부
createParent: true
// block replication factor (dfs.replication)
replication: 3
// maximum block size (dfs.blocksize)
blockSize: 5242880
// Crypto protocol version
cryptoProtocolVersion: ENCRYPTION_ZONES
// Permision
masked {
perm: 420
}
unmasked {
perm: 438
}
}
NameNode는 fileId(Inode ID)가 포함된 파일 상태 정보를 클라이언트에게 응답으로 보낸다.
message CreateResponseProto {
// 파일 상태
fs: message HdfsFileStatusProto {
fileType: IS_FILE
...
owner: "owner"
group: "group"
...
block_replication: 3
blocksize: 5242880
// Inode ID
fileId: 17434
}
}
DataNode 할당
NameNode로부터 create 응답을 받은 후 클라이언트는 데이터를 쓸 DataNode를 할당받아야 한다. 클라이언트는 DataNode를 할당받기 위해 NameNode에 addBlock 요청(그림 3의 2)을 보낸다. 클라이언트는 addBlock 요청 시 create 응답으로 받았던 fileId(Inode ID)와 블록 할당을 위한 힌트 정보를 보낸다.
message AddBlockRequestProto {
// 파일 경로
src: "/test_dir/file.txt"
// 클라이언트명
clientName: "DFSClient_..."
// 블록 할당 시 제외하고 싶은 노드
excludeNodes: []
// Inode ID
fileId: 17434
// 클라이언트가 선호하는 노드
favoredNodes: ""
// 블록 할당에 대한 힌트(AddBlockFlag)
flags: ""
}
NameNode는 addBlock 응답으로 클라이언트에 블록 정보와 파이프라인 대상 DataNode 정보를 보낸다.
message AddBlockResponseProto {
block: message LocatedBlockProto {
// 블록 정보
b: message ExtendedBlockProto {
// Block Pool ID
poolId: "BP-..."
// Block ID
blockId: 1073742133
generationStamp: 1309
numBytes: 0
}
// 파일에서 블록의 첫 번째 바이트 오프셋
offset: 0
// 파이프라인 대상 DataNode 정보
locs: [DatanodeInfoProto, DatanodeInfoProto, message DatanodeInfoProto {
// DataNode IP 주소, 호스트명, 포트 정보
id: message DatanodeIDProto {
ipAddr: "x.x.x.x"
hostName: "example"
datanodeUuid: "..."
xferPort: 0
infoPort: 0
ipcPort: 0
infoSecurePort: 0
}
...
}]
storageTypes: [DISK, DISK, DISK]
storageIDs: [..., ... , ...]
...
}
}
파이프라인 구성 및 데이터 쓰기
NameNode로부터 파이프라인 대상 DataNode 정보를 획득한 클라이언트는 데이터를 쓰기 위해 파이프라인 대상 DataNode들로 블록 생성 파이프라인을 구성하고 블록을 패킷(네트워크 패킷이 아니라 HDFS 데이터 쓰기에서 사용되는 클래스를 의미)으로 나누어 파이프라인의 DataNode에 데이터를 쓴다. 파이프라인을 구성하고 데이터를 쓰는 과정은 그림 4와 같이 3 단계로 이루어진다.
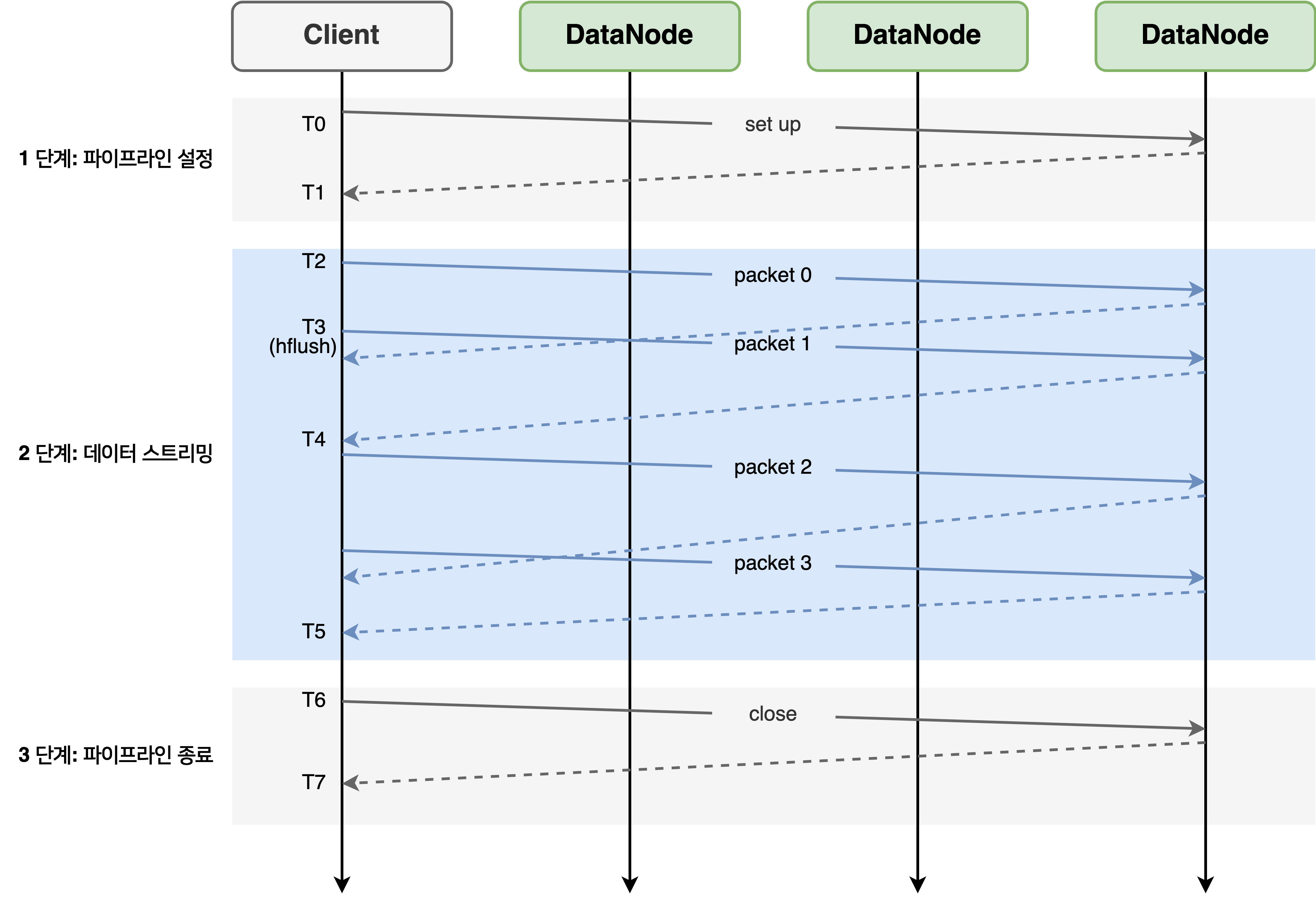
1 단계: 파이프라인 설정
그림 4의 T0~T1은 파이프라인 설정 단계이다. 파이프라인을 따라 다운스트림 DataNode에게 WRITE_BLOCK 요청을 전송한다.(그림 3의 3)
message OpWriteBlockProto {
header: message ClientOperationHeaderProto {
baseHeader: message ClientOperationHeaderProto {
// 블록 정보
block: message ExtendedBlockProto
...
}
// 클라이언트명
clientName: "DFSClient_..."
}
// 파이프라인 대상 DataNode 정보(IP 주소, 호스트명, 포트 정보, ...)
targets: [DatanodeInfoProto, DatanodeInfoProto]
// 파이프라인 스테이지(BlockConstructionStage)
stage: PIPELINE_SETUP_CREATE(블록 생성을 위한 파이프라인 설정)
// 파이프라인 크기
pipelineSize: 3
// minimum number of bytes received.
minBytesRcvd: 0
// maximum number of bytes received.
maxBytesRcvd: 0
// 블록의 latest Generation Stamp
latestGenerationStamp: 0
}
마지막 DataNode가 요청을 받은 후 파이프라인 업스트림으로 ACK가 전송된다.(그림 3의 4)
message BlockOpResponseProto {
// 파이프라인 상태
status: SUCCESS
// 연결 설정에 실패한 첫 번째 DataNode
firstBadLink: ""
}
파이프라인 설정 단계가 끝나면 파이프라인을 따라 네트워크 연결이 설정되고 DataNode에 Replica가 준비된다.
writeBlock요청에서stage가PIPELINE_SETUP_CREATE인 경우 DataNode는 새로운 RBW Replica를 만든다.writeBlock요청에서stage가PIPELINE_SETUP_APPEND인 경우 append를 위해 DataNode는 Finalized Replica를 RBW Replica로 바꾼다.
2 단계: 데이터 스트리밍
그림 4의 T2~T5는 데이터 스트리밍 단계이다. 그림 4의 T2에서 첫 번째 패킷이 전송되었고 T5에서 마지막 패킷의 ACK를 수신했다.
파이프라인 설정이 완료되면 클라이언트는 파이프라인에 데이터를 쓰는데, 데이터는 먼저 클라이언트 버퍼에 저장된다. 버퍼가 꽉 차면 파이프라인으로 데이터가 전송된다.(그림 3의 5)
이전 패킷의 ACK를 받기 전이라도 파이프라인을 통해 다음 패킷이 전송될 수 있다. 그림 4의 T3에서 hflush가 호출되었다. hflush가 명시적으로 호출된 경우에는 패킷이 채워지지 않았어도 파이프라인으로 전송된다. hflush는 동기 작업이기 때문에 flush된 패킷의 ACK를 받기 전에는 데이터를 쓸 수 없다. 그림 4의 packet 2는 packet 1의 ACK를 수신한 그림 4의 T4 이후에 전송된다.
3 단계: 파이프라인 종료
그림 3의 T6~T7은 파이프라인 종료 단계이다. 클라이언트는 모든 패킷의 ACK을 받은 후에 종료(close) 요청을 보낸다. 파이프라인의 모든 DataNode는 해당 Replica를 Finalized 상태로 변경하고 NameNode에 보고한다. NameNode는 Replica의 상태가 Finalized라고 보고한 DataNode의 수가 최소 복제 수 이상인 경우 블록의 상태를 완료(Complete)로 바꾼다. 파일을 닫으려면 파일의 모든 블록이 완료된 상태여야 한다
모든 데이터를 다 쓴 클라이언트는 해당 파일에 쓰기 작업이 완료되었다는 것을 NameNode로 알리고 파일을 닫기 위해 NameNode에 complete 요청(그림 3의 7)을 보낸다.
message CompleteResponseProto {
// 파일 경로
src: "/test_dir/file.txt"
// 클라이언트명
clientName: "DFSClient_..."
// 마지막 블록 정보
last: message ExtendedBlockProto {
poolId: "..."
blockId: "..."
generationStamp: ...
}
// Inode ID
fileId: 17434
}
message CompleteResponseProto {
// 성공 여부
result: true
}
HDFS 쓰기 파이프라인의 특징
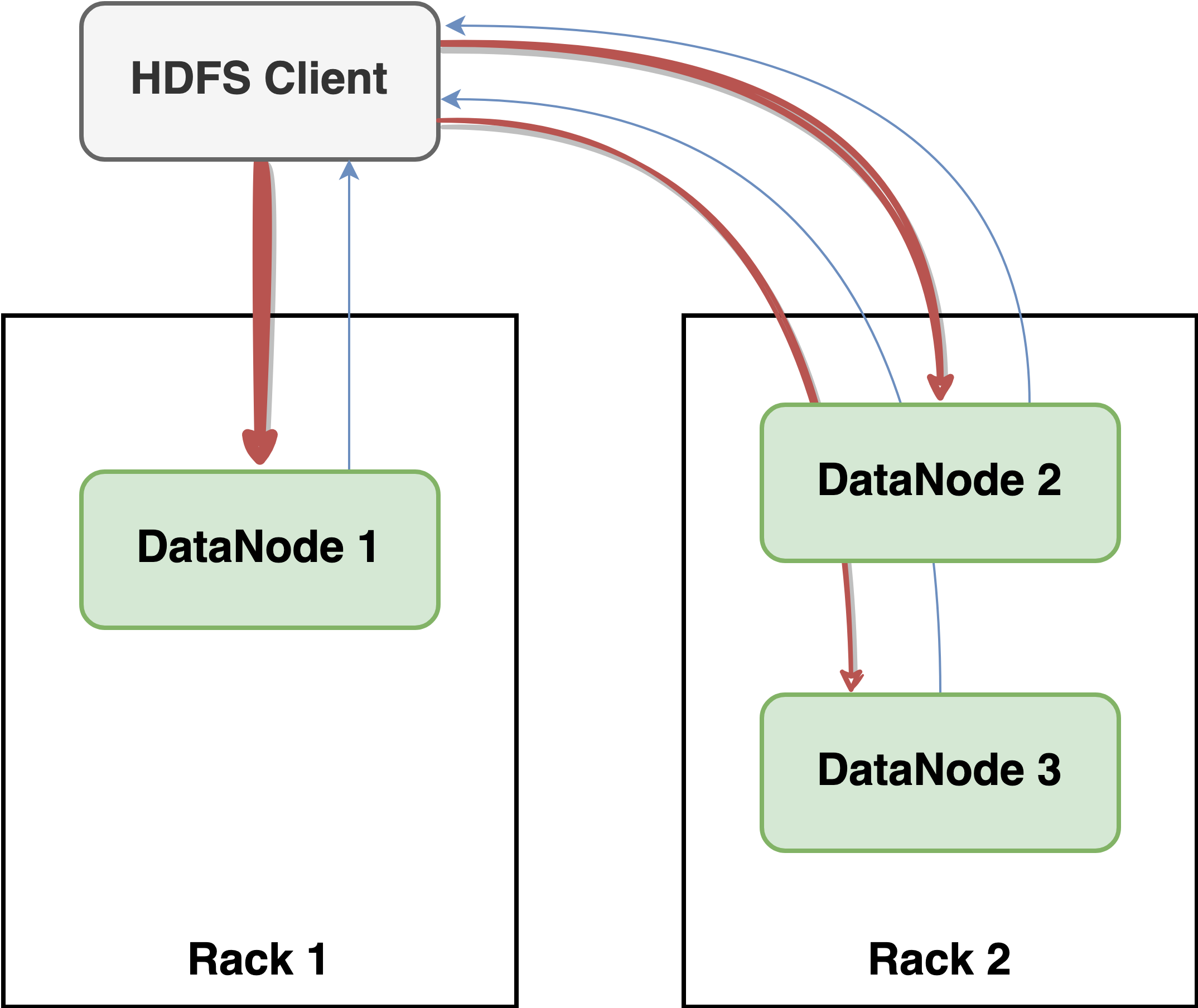
지금까지 HDFS 쓰기 파이프라인에 대해 알아보았다. HDFS 쓰기 파이프라인은 각 노드의 네트워크 대역폭을 최대한 활용하여 모든 데이터를 복제하는 데 걸리는 시간을 최소화하는 방식이다. 왜 HDFS 쓰기 파이프라인이 각 노드의 네트워크 대역폭을 최대한 활용하는 방식인지 그림 5와 그림 6의 비교를 통해 알아보겠다.
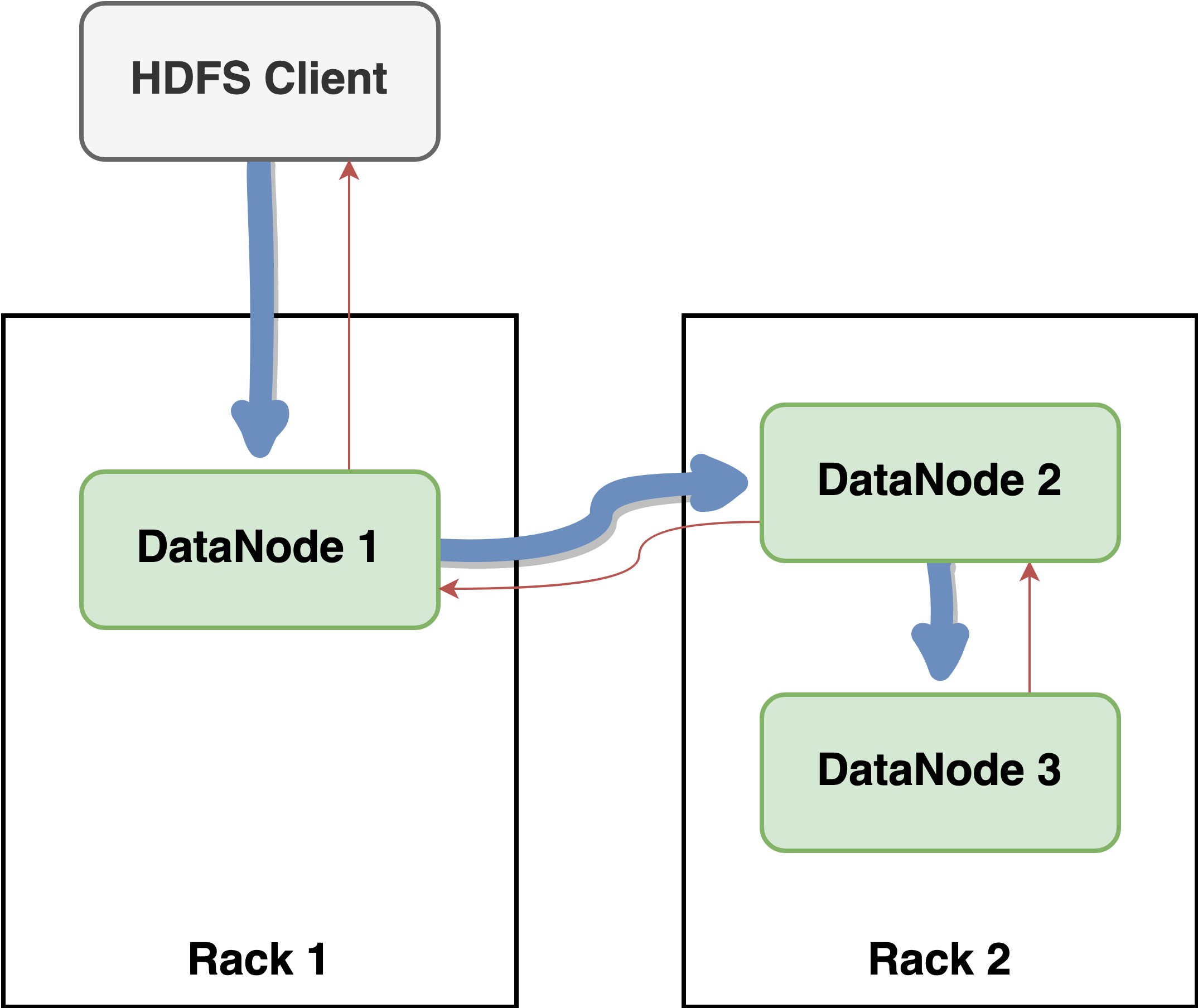
HDFS 클라이언트를 포함하여 각 노드의 사용 가능한 대역폭이 1Gbps라고 가정하면 그림 5의 경우 복제본 데이터를 포함하여 전송하는 전체 데이터의 양은 3Gbps가 된다. 실제로는 DataNode 2와 DataNode 3가 동일 Rack 안에 있기 때문에 지연 시간이 짧고 사용 가능한 대역폭도 더 커서 더 빠르게 데이터가 전송될 것이다.
하지만 그림 6과 같이 클라이언트가 데이터를 모든 DataNode에 전송하면 전송하는 전체 데이터의 양은 1Gbps가 된다. 일반적으로 HDFS에 저장하는 파일은 크기가 크다. 저장해야 하는 파일의 크기가 크기 때문에 복제를 위해 네트워크를 통해 전송해야 하는 데이터의 양도 많아진다.
즉, 각 노드의 대역폭을 최대한 활용하는 파이프라인 방식이 큰 파일을 저장하는 HDFS에서 효율적이다.
Fan-out DFSOutputStream를 통한 WAL 쓰기 최적화
HBase는 아래와 같이 4가지의 WAL Durability 설정을 제공하며, SYNC_WAL이 기본값이다.
- WAL을 비활성화한다.
- 데이터 손실이 발생할 수 있는 옵션이다.
- 클라이언트가 WAL에 쓴 데이터가 sync되는 것을 기다리지 않는다.
- 데이터 손실이 발생할 수 있는 옵션이다.
- 클라이언트에 리턴하기 전에 데이터가 sync되길 기다린다.(HDFS의
hflush호출)
- 클라이언트에 리턴하기 전에 데이터가 fsync되길 기다린다.(HDFS의
hsync호출)
WAL Durability 설정이 SYNC_WAL인 경우 HBase는 WAL에 데이터를 쓰고 데이터 손실을 방지하기 위해 HDFS의 hflush를 호출해 데이터가 sync되길 기다린다. hflush는 동기 작업으로, 클라이언트는 전송한 패킷의 ACK가 오길 기다린다.(2 단계: 데이터 스트리밍 참고)
WAL 데이터는 상대적으로 데이터의 크기가 작기 때문에 WAL 쓰기는 네트워크 대역폭의 영향은 덜 받지만, 전송한 패킷의 ACK가 오길 기다려야 하기 때문에 지연 시간이 긴 경우 WAL 쓰기 성능이 낮아질 수 있다. 따라서 WAL 쓰기 성능을 높이기 위해서는 지연 시간을 감소시키는 게 중요한데, 그림 5와 같이 파이프라인을 통해 데이터를 전달하면 ACK가 여러 노드를 거쳐서 클라이언트로 전달되기 때문에 지연 시간이 길어질 수 있다. 그림 6과 같이 클라이언트가 동시에 모든 데이터를 전송하고 ACK를 직접 받으면 지연 시간을 줄일 수 있다.
HBase는 WAL 쓰기 성능을 개선하기 위해 Netty 기반으로 그림 6처럼 DataNode에 데이터를 동시에 쓰는 WAL 쓰기용 Fan-out DFSOutputStream을 개발했다. HBase는 다음과 같이 hbase.wal.provider를 설정하여 WAL 구현체를 지정할 수 있는데 hbase.wal.provider를 asyncfs(HBase 2에서 기본값)로 설정한 경우 Fan-out DFSOutputStream이 사용된다.
- HBase 2에서 기본값이다.
- HBase 2에서 추가되었으며 WAL 데이터를 블록 생성 파이프라인을 따라서 쓰지 않고 동시에(Fan-out) 쓰기 때문에 지연 시간을 줄일 수 있다.
- HBase 1에서 기본값이다.
- DFSClient를 기반으로 만들어졌으며 블록 생성 파이프라인을 따라 데이터를 쓴다.
- 여러 개의
asyncfs또는 여러 개의filesystem을 사용하는 설정이다. - RegionServer에서 단일 WAL을 사용하면 병목 현상이 생길 수 있는데 여러 개의 WAL을 병렬로 쓸 수 있게 하여 총 처리량을 증가시킬 수 있는 방법이다.
Fan-out DFSOutputStream은 모든 DataNode에 동시에 데이터 쓰기를 진행하기 때문에 일반적으로 대기 시간이 단축된다. 또한 오류가 발생했을 때 파이프라인 복구를 수행하지 않고 새로운 WAL 파일을 만들어서 데이터를 다시 쓴다. 파이프라인 복구를 수행하지 않기 때문에 앞에서 언급한 파이프라인 복구 실패로 인한 문제가 발생하지 않는다. Fan-out DFSOutputStream의 구조는 다음과 같다.
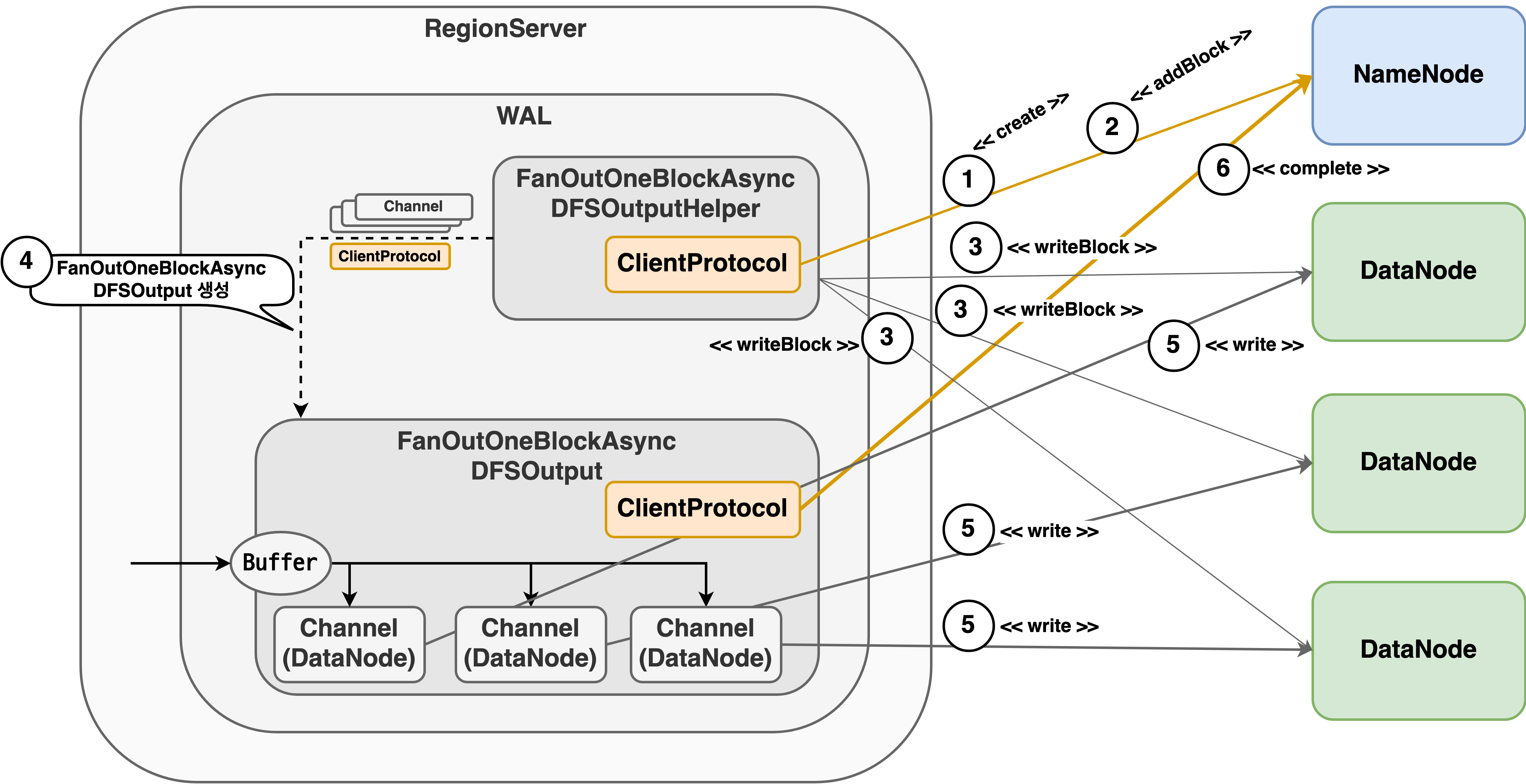
새로운 WAL 파일이 요청되면 FanOutOneBlockAsyncDFSOutputHelper는 HDFS 쓰기 파이프라인와 동일하게 Client Protocol의 create 요청(그림 7의 1)을 보내 네임스페이스에 새로운 WAL 파일 항목을 만든다. 각 Protocol의 요청과 응답 데이터가 Protocol Buffer를 통해 직렬화, 역직렬화되기 때문에 HBase는 HDFS의 Protocol Buffer 코드를 통해 쉽게 동일한 요청을 만들고 응답을 파싱할 수 있다.
NameNode로부터 응답을 받은 후 블록을 쓸 DataNode를 할당받기 위해 FanOutOneBlockAsyncDFSOutputHelper는 addBlock 요청(그림 7의 2)을 NameNode로 보낸다. NameNode로부터 블록을 쓸 DataNode를 할당받은 후에는 Netty Channel을 사용해서 DataNode와 연결을 맺고 writeBlock 요청(그림 7의 3)을 보낸다. FanOutOneBlockAsyncDFSOutputHelper가 보내는 writeBlock 요청은 다음과 같다.
FanOutOneBlockAsyncDFSOutputHelper에서 보내는 writeBlock 요청 예
message OpWriteBlockProto {
header: message ClientOperationHeaderProto {
// 블록 정보
block: message ExtendedBlockProto
...
}
// 클라이언트명
clientName: "DFSClient_..."
// 파이프라인 대상 DataNode 정보(IP 주소, 호스트명, 포트 정보, ...)
targets: []
// 파이프라인 스테이지(BlockConstructionStage)
stage: PIPELINE_SETUP_CREATE
// 파이프라인 크기
pipelineSize: 1
// ...
}
FanOutOneBlockAsyncDFSOutputHelper가 보내는 writeBlock 요청을 살펴보면 HDFS 쓰기 파이프라인에서 보내는 writeBlock 요청과 다르게 파이프라인 대상 DataNode 정보가 없고 파이프라인 크기가 1이다. 이 요청을 받은 DataNode는 파이프라인 대상 DataNode 정보가 없기 때문에 자신을 파이프라인의 마지막 DataNode로 인식하고 다른 DataNode와 추가적인 연결을 만들지 않는다. 즉, DataNode끼리 블록 생성 파이프라인을 만들지 않는다.
하지만 이 방식은 HDFS의 가시성(visibility)이 보장되지 않는다. 데이터를 쓰고 있는 파일의 경우 HDFS의 가시성 보장에 따라 파이프라인의 마지막 DataNode에 쓰인 데이터까지 클라이언트에서 사용 가능한 데이터가 되는데, Fan-out DFSOutputStream은 모든 DataNode가 파이프라인의 마지막 DataNode로 취급되기 때문에 아직 데이터를 쓰고 있는 WAL 파일을 읽을 경우 데이터 불일치가 발생할 수 있다. HBase는 이 문제를 해결하기 위하여 HDFS에 sync된 파일의 길이를 별도로 관리하여 내부 프로세스에서 데이터를 읽을 때 해당 길이까지만 데이터를 읽을 수 있도록 제한한다.
DataNode와 기존 HDFS 쓰기 파이프라인에 파이프라인 설정 단계까지 마친 FanOutOneBlockAsyncDFSOutputHelper는 클라이언트가 데이터를 쓸 수 있도록 FanOutOneBlockAsyncDFSOutput을 생성한다.(그림 7의 4) 이후 FanOutOneBlockAsyncDFSOutput은 Netty Channel을 이용하여 모든 DataNode에 동시에 WAL 데이터를 쓴다.(그림 7의 5)
HBase는 데이터를 쓰고 있는 WAL의 파일 크기가 HDFS 블록 크기(hbase.regionserver.hlog.blocksize 설정)의 50%(hbase.regionserver.logroll.multiplier 설정)가 되거나 기존 파일에 데이터를 쓰다 오류가 발생하면 기존 WAL 파일을 닫고 새로운 WAL 파일을 만든다.
- WAL 파일의 HDFS 블록 크기(기본값: HDFS 기본 블록 크기의 2배)
- WAL 파일의 크기가 HDFS 블록 크기의 multiplier만큼 도달하면 새로운 WAL 파일을 만든다.(기본값: 0.5)
기존 WAL 파일을 닫고 새로운 WAL 파일을 만들 때 기존 FanOutOneBlockAsyncDFSOutput은 닫고 새로운 FanOutOneBlockAsyncDFSOutput을 만드는데, FanOutOneBlockAsyncDFSOutput이 닫힐 때 FanOutOneBlockAsyncDFSOutput은 DataNode와 연결을 정리하고 NameNode에 complete 요청(그림 7의6)을 보내 현재 WAL 파일에 쓰기 작업이 완료되었다는 것을 알린다.
마치며
이 글에서는 HDFS 쓰기 파이프라인과 HBase가 WAL 쓰기 최적화를 위해 개발한 Fan-out DFSOutputStream에 대해 알아보았다.
Fan-out DFSOutputStream은 아직 일반적인 쓰기 작업에서는 사용할 수 없다. 일반적인 쓰기 작업에서 사용하기 위해서는 Fan-out DFSOutputStream이 여러 블록을 쓸 수 있도록 개선하고 HDFS 가시성이 보장되지 않는 문제를 해결해야 한다. 또한 추후 해당 기능을 적용하려면 그 전에 쓰기 작업이 네트워크 대역폭을 최대로 활용하는 것이 중요한지, 아니면 지연 시간을 줄이는 것이 중요한지 먼저 판단할 필요가 있다.
HBase에서 WAL 성능은 사용자 요청 처리 시간에 영향을 많이 준다. 따라서 HBase는 WAL 성능을 높이기 위해서는 지연 시간을 줄이는 것이 필요했다. 이를 위해 HBase는 HDFS 프로토콜을 사용하여 Fan-out DFSOutputStream을 개발했다. 2.5.0 버전에는 패킷 처리 시간이 느린 DataNode를 빠르게 탐지하여 OutputStream에서 제거하는 기능이 추가되었는데(HBASE-26347 Support detect and exclude slow DNs in fan-out of WAL) 이러한 기능은 자체 개발한 Fan-out DFSOutputStream에서 ACK가 돌아오는 시간을 측정할 수 있었기 때문에 가능했다. 만약 HDFS 프로토콜에 대한 이해가 없었다면 이러한 기능을 추가하기 어려웠을 것이다.
추후 기회가 된다면 각 컴포넌트가 프로토콜을 어떻게 처리하는지 알아보겠다. 이 글이 HDFS 쓰기 과정을 이해하는 데 조금이나마 도움이 되길 바란다.
참고 자료



