
AI 스마트폰의 핵심, LLM 경량화 테크닉
AI 스마트폰의 핵심, LLM 경량화 테크닉 관련

최근 갤럭시 S24를 시작으로 서버나 클라우드에 연동할 필요 없이 스마트폰에서 직접 생성형 AI 기능을 활용할 수 있는 ‘AI 스마트폰’이 관심을 모으고 있습니다. 삼성전자는 갤럭시 스마트폰 기기에 자체 개발한 초거대언어모델(이하 LLM) 삼성 가우스(Gauss)를 탑재하여 실시간 자동 번역, 채팅, 사진 편집 등 다양한 기능을 제공하고 있습니다. 애플 역시 자사 AI 플랫폼 ‘애플 인텔리전스’에 GPT, 제미나이(Gemini), 클로드(Claude) 등 다양한 LLM을 활용한 서비스를 제공할 계획을 밝혔죠.
LLM은 그 이름에서 알 수 있듯 거대한 모델 사이즈와 방대한 양의 훈련 데이터에서 나오는 압도적인 성능이 특징입니다. 일반적으로 언어 모델은 심층신경망(DNN)의 가중치(weight)와 편향(bias)의 정보를 담고 있는 매개 변수(parameter)가 많으면 많을수록 성능이 좋습니다. 이를 통해 언어의 문맥과 세부적인 뉘앙스까지 파악해 추론할 수 있죠. 그에 따라 자연스럽게 LLM은 매개 변수의 양을 늘려가는 방식으로 발전해 왔습니다.
매개 변수 확대로 성능 개선을 노리는 경향은 비단 GPT-4o나 클로드 소넷(Sonnet)처럼 API로 제공되며 엄청난 크기를 가진 모델에서만 나타나지 않습니다. 얼마 전 출시된 메타의 LLaMA 3.1은 경량화와 가성비를 추구하던 오픈 소스 모델로서는 다소 파격적으로 4,050억 개(405B)의 매개 변수를 자랑하며 개발자들 사이에서 화제가 되었습니다.
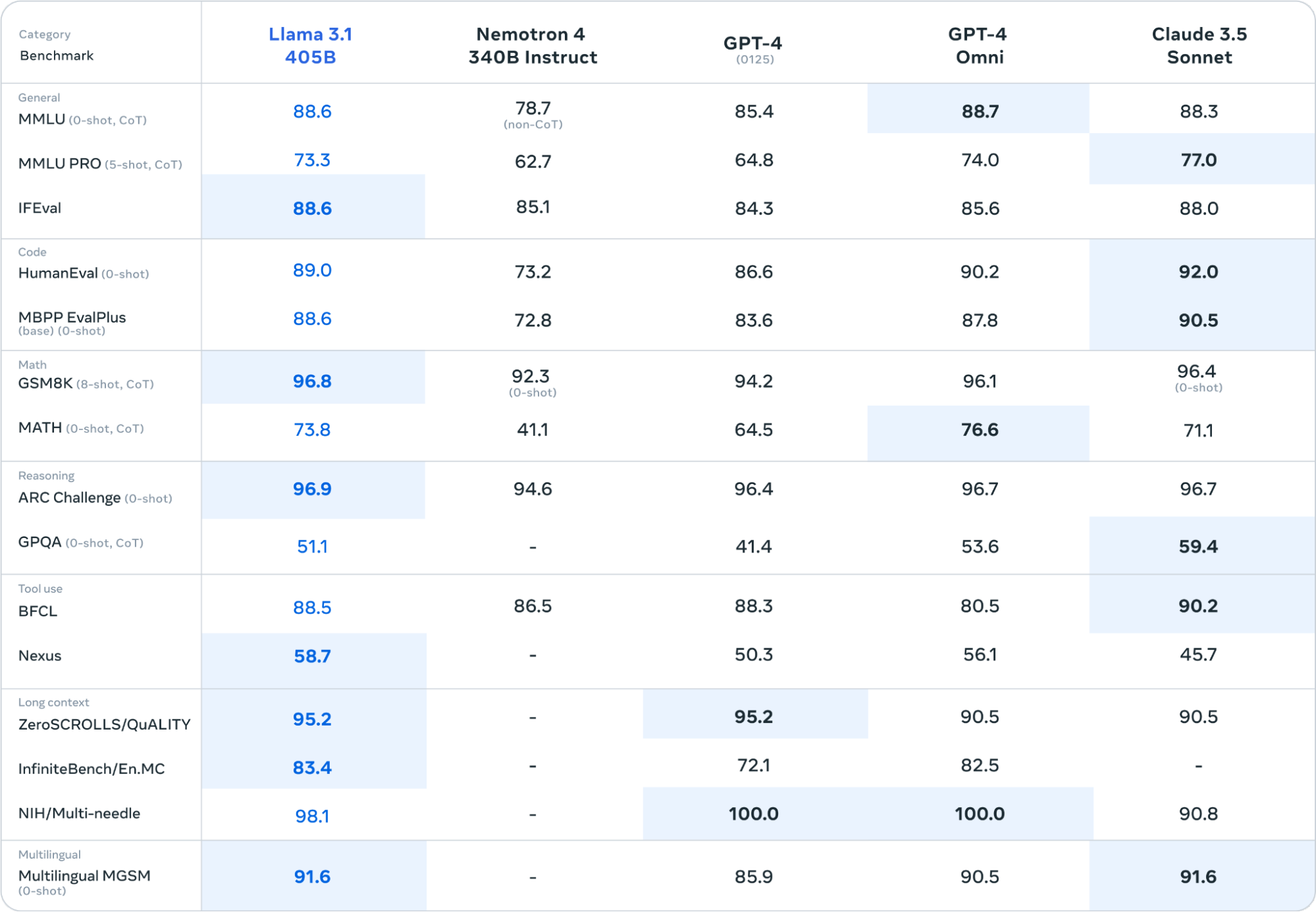
<출처: Meta>
이러한 LLM을 활용하려면 천문학적인 양의 연산을 처리하기 위한 병렬 처리 기술과 고성능 GPU로 무장한 서버/데이터 센터가 필수입니다. 그런데 여기서 의문이 생깁니다. 이 커다란 LLM 모델이 어떻게 그 작은 스마트폰 속으로 들어갈 수 있었을까요? 그 해답은 바로 ‘LLM 경량화 테크닉’에 있습니다.
대표적인 LLM 경량화 테크닉
LLM의 커다란 사이즈로 발생하는 문제를 해결하기 위해 언어 모델 연구자와 개발자들은 모델의 사이즈를 줄이면서도 성능을 비슷하게 유지할 방법을 고심하기 시작했습니다. 곧 “매개 변수가 큰 모델을 경량화해서 사용하는 것이 대체로 매개 변수가 작은 모델을 그대로 사용하는 것보다 성능이 좋다.”라는 결론을 내리게 됩니다.
LLM 경량화 테크닉의 기초를 이해하려면 우선 변수 형태 변환으로 모델 성능을 거의 동일하게 유지하면서 크기를 줄이는 ‘양자화(quantization)’ 개념을 아는 것이 중요합니다. 그다음으로 최근 실전에서 많이 쓰이는 대표적인 경량화 테크닉인 파인튜닝 기술, ‘PEFT(Parameter Efficient Fine-Tuning)’ 개념을 소개하겠습니다.
양자화(quantization)란?
마블(Marble) 영화 ‘앤트맨’의 주인공 스콧은 슈트에 달린 버튼으로 ‘핌 입자’를 활성화해 몸의 크기를 줄일 수 있습니다. 왼손의 버튼으로 축소했다 오른손의 버튼으로 돌아가는 것이 가능하죠. 개미만한 크기로 작아진 앤트맨은 마치 초인과 같은 힘을 냅니다. 남성 한 명의 전체 질량을 유지한 상태에서 극도로 좁아진 타격 면적에 직격하면 엄청난 위력을 낼 수 있기 때문입니다.
LLM도 마치 앤트맨처럼 작게 줄일 수 있다는 사실을 아시나요? 양자화는 강력한 LLM을 보다 작은 크기로 축소해 활용할 수 있게 해줍니다. 정확한 이해를 위해 조금 더 기술적 관점에서 양자화에 대해 이야기해보도록 하겠습니다.
**양자화(quantization)**란 LLM의 매개 변수를 실수형 변수(floating-point type)에서 정수형 변수(integer or fixed point)로 변환해 더 작은 비트로 바꾸는 과정을 말합니다. 양자화를 거친 LLM은 거의 동일한 성능을 가지지만 실제 사이즈보다 작은 모델처럼 보이도록 변환됩니다. 예를 들어 원래 32비트 부동 소수점을 가지고 있는 모델의 매개 변수를 8비트 정수로 변환하는 것처럼, 언어 모델이 가진 각각의 매개 변수 비트 수를 줄여주는 것입니다.
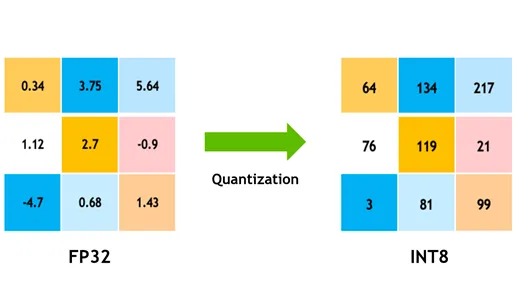
<출처: Florian June 미디엄 블로그>
이렇게 양자화를 거친 LLM은 크기가 줄어들 뿐만 아니라 계산 효율성 역시 좋아집니다. 보통 비트 수를 N배 줄이면 곱셈 복잡도는 NxN 만큼 줄어들죠. 예시처럼 float32 대신 int8을 쓰면 단순 계산만으로도 모델 크기가 1/4까지 작아집니다. 이에 따라 추론 속도 역시 2배에서 4배까지 빨라집니다. 마찬가지로 2배에서 4배까지 적은 메모리로도 비슷한 성능의 LLM 연산이 가능해집니다.
이처럼 양자화는 LLM 크기를 줄여 주고 계산 효율성을 향상시켜 줍니다. 그러나 양자화로 모델의 성능 저하가 생길 수 있다는 점을 염두에 둬야 합니다. 양자화의 목적은 훈련 및 계산 비용을 줄이면서도 성능을 유지하는 것으로 매개 변수의 일부만을 조정하여 활용하기 때문에 원래 모델과 동일한 성능을 보장하지는 않습니다. 따라서 양자화 모델은 어디까지나 가성비에 중점을 두어야 하며 사용 전에 철저한 모델 평가가 필요합니다.
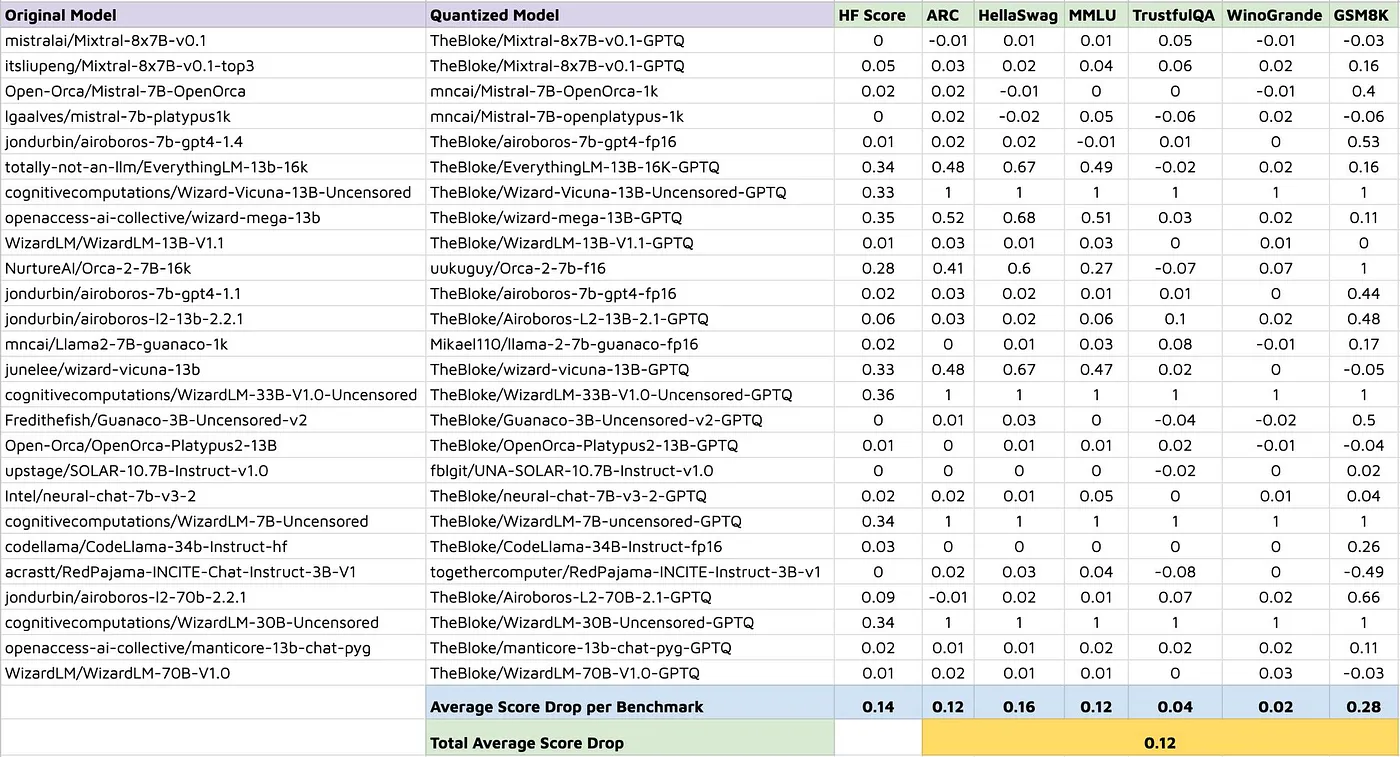
<출처: Olga Zem 미디엄 블로그>
PEFT(Parameter Efficient Fine-Tuning)란?
생성형 AI 열풍으로 최근 ‘파인튜닝(Fine-tuning)’이라는 단어를 한 번쯤 들어봤을 것입니다. GPT와 같은 LLM 기초 모델은 두 가지 단계를 거쳐 만들어집니다. 첫째, 백지상태 모델에 방대한 양의 텍스트 데이터를 학습시켜 전반적인 언어 능력 및 생성 능력을 향상시키는 사전학습(pre-training)과 둘째, 비교적 적은 데이터셋을 활용해 LLM을 특정 분야의 전문 지식과 태스크에 특화시키는 파인튜닝이죠.
PEFT(Parameter Efficient Fine-Tuning)란 적은 수의 매개 변수 학습만으로 빠른 시간에 새로운 문제를 효과적으로 해결하는 파인튜닝 기법을 말합니다. 최근 적게는 수천억 개에서 많게는 조 단위 이상의 매개 변수를 가진 LLM도 파라미터 일부만 조절하여 유사한 성능을 낼 수 있다는 연구 결과가 있었습니다. 이를 기반으로 PEFT 방법론 연구가 활발히 진행되는 중이죠.
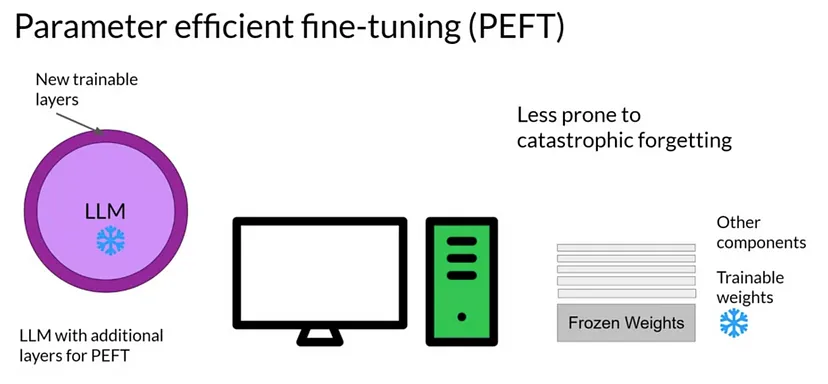
<출처: kanika adik 미디엄 블로그>
PEFT의 중요한 특징은 파인튜닝 시 전체 모델을 조정하는 것보다 적은 계산 자원과 데이터만을 사용한다는 점입니다. 이는 다양한 언어와 도메인 데이터에 모델을 적용할 때 특히 유용합니다. 각 언어 또는 도메인별로 작은 체크포인트만 로컬에 저장하면 효율적으로 작동하기 때문이죠. 따라서 AI 스마트폰처럼 다운로드나 업데이트의 제한이 있는 환경에서 모델의 다양성을 유지하는 데에 큰 도움이 됩니다.
또한 PEFT는 다양한 태스크에 모델을 신속히 적용하고자 하는 연구자나 개발자에게 특히 유용합니다. 기존에 학습된 LLM 위에 추가 레이어를 덧붙여 미세 조정하며 새로운 작업에 대한 모델 적용 및 평가가 가능하기 때문입니다.
마치며: LLM 경량화 테크닉은 만능이 아니다
이처럼 LLM 경량화 테크닉은 모바일 기기나 기타 제한된 자원을 사용하는 환경에서 생성형 AI 기능을 효율적으로 활용하는 데 매우 효과적입니다. 특히 실시간 자동 번역, 채팅, 사진 편집 등 다양한 기능을 제공해야 하는 AI 스마트폰에서는 모델 경량화 테크닉이 필수죠. 이 기술이 거대한 모델 사이즈라는 LLM의 고질적인 문제점을 해결해 생성형 AI 확산에 기여할 수 있을 것으로 기대됩니다.
그러나 양자화나 PEFT 같은 LLM 경량화 테크닉은 만능이 아닙니다. 기술을 활용할 때 그 한계점을 이해하는 것은 매우 중요합니다.
예를 들어 양자화의 경우, 모델의 매개 변수를 정수형으로 변환하는 과정에서 일부 정보 손실이 발생할 수 있습니다. 따라서 특히 복잡한 언어 이해나 생성 작업에서는 이로 인한 성능 저하가 생길 수 있음을 충분히 인지하고 활용해야 합니다. 마찬가지로 PEFT 역시 적은 수의 매개 변수만을 조정하기 때문에 전체 모델을 튜닝하는 것보다 특정 태스크에서의 최적 성능을 달성하기 어려울 수 있습니다. 경량화 테크닉을 내 제품에 활용할 예정인 개발자라면 이 사실을 꼭 염두에 두고 적용 방법을 모색하기 바랍니다.