
The Quicksort Algorithm in Python
The Quicksort Algorithm in Python 관련

Just like merge sort, the Quicksort algorithm applies the divide-and-conquer principle to divide the input array into two lists, the first with small items and the second with large items. The algorithm then sorts both lists recursively until the resultant list is completely sorted.
Dividing the input list is referred to as partitioning the list. Quicksort first selects a pivot element and partitions the list around the pivot, putting every smaller element into a low array and every larger element into a high array.
Putting every element from the low list to the left of the pivot and every element from the high list to the right positions the pivot precisely where it needs to be in the final sorted list. This means that the function can now recursively apply the same procedure to low and then high until the entire list is sorted.
Implementing Quicksort in Python
Here’s a fairly compact implementation of Quicksort:
from random import randint
def quicksort(array):
# If the input array contains fewer than two elements,
# then return it as the result of the function
if len(array) < 2:
return array
low, same, high = [], [], []
# Select your `pivot` element randomly
pivot = array[randint(0, len(array) - 1)]
for item in array:
# Elements that are smaller than the `pivot` go to
# the `low` list. Elements that are larger than
# `pivot` go to the `high` list. Elements that are
# equal to `pivot` go to the `same` list.
if item < pivot:
low.append(item)
elif item == pivot:
same.append(item)
elif item > pivot:
high.append(item)
# The final result combines the sorted `low` list
# with the `same` list and the sorted `high` list
return quicksort(low) + same + quicksort(high)
Here’s a summary of the code:
- Line 6 stops the recursive function if the array contains fewer than two elements.
- Line 12 selects the
pivotelement randomly from the list and proceeds to partition the list. - Lines 19 and 20 put every element that’s smaller than
pivotinto the list calledlow. - Lines 21 and 22 put every element that’s equal to
pivotinto the list calledsame. - Lines 23 and 24 put every element that’s larger than
pivotinto the list calledhigh. - Line 28 recursively sorts the
lowandhighlists and combines them along with the contents of thesamelist.
Here’s an illustration of the steps that Quicksort takes to sort the array [8, 2, 6, 4, 5]:
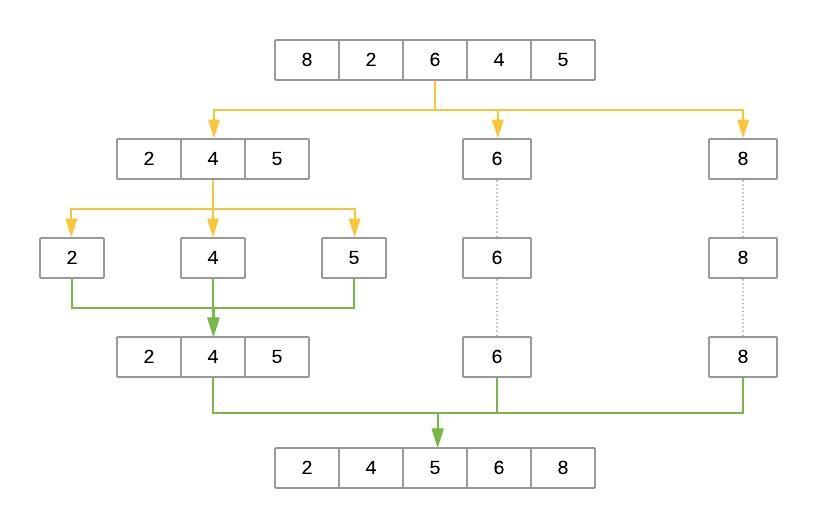
The yellow lines represent the partitioning of the array into three lists: low, same, and high. The green lines represent sorting and putting these lists back together. Here’s a brief explanation of the steps:
- The
pivotelement is selected randomly. In this case,pivotis6. - The first pass partitions the input array so that
lowcontains[2, 4, 5],samecontains[6], andhighcontains[8]. quicksort()is then called recursively withlowas its input. This selects a randompivotand breaks the array into[2]aslow,[4]assame, and[5]ashigh.- The process continues, but at this point, both
lowandhighhave fewer than two items each. This ends the recursion, and the function puts the array back together. Adding the sortedlowandhighto either side of thesamelist produces[2, 4, 5]. - On the other side, the
highlist containing[8]has fewer than two elements, so the algorithm returns the sortedlowarray, which is now[2, 4, 5]. Merging it withsame([6]) andhigh([8]) produces the final sorted list.
Selecting the pivot Element
Why does the implementation above select the pivot element randomly? Wouldn’t it be the same to consistently select the first or last element of the input list?
Because of how the Quicksort algorithm works, the number of recursion levels depends on where pivot ends up in each partition. In the best-case scenario, the algorithm consistently picks the median element as the pivot. That would make each generated subproblem exactly half the size of the previous problem, leading to at most levels.
On the other hand, if the algorithm consistently picks either the smallest or largest element of the array as the pivot, then the generated partitions will be as unequal as possible, leading to recursion levels. That would be the worst-case scenario for Quicksort.
As you can see, Quicksort’s efficiency often depends on the pivot selection. If the input array is unsorted, then using the first or last element as the pivot will work the same as a random element. But if the input array is sorted or almost sorted, using the first or last element as the pivot could lead to a worst-case scenario. Selecting the pivot at random makes it more likely Quicksort will select a value closer to the median and finish faster.
Another option for selecting the pivot is to find the median value of the array and force the algorithm to use it as the pivot. This can be done in time. Although the process is little bit more involved, using the median value as the pivot for Quicksort guarantees you will have the best-case Big O scenario.
Measuring Quicksort’s Big O Complexity
With Quicksort, the input list is partitioned in linear time, , and this process repeats recursively an average of times. This leads to a final complexity of .
That said, remember the discussion about how the selection of the pivot affects the runtime of the algorithm. The best-case scenario happens when the selected pivot is close to the median of the array, and an scenario happens when the pivot is the smallest or largest value of the array.
Theoretically, if the algorithm focuses first on finding the median value and then uses it as the pivot element, then the worst-case complexity will come down to . The median of an array can be found in linear time, and using it as the pivot guarantees the Quicksort portion of the code will perform in .
By using the median value as the pivot, you end up with a final runtime of . You can simplify this down to because the logarithmic portion grows much faster than the linear portion.
Note
Although achieving is possible in Quicksort’s worst-case scenario, this approach is seldom used in practice. Lists have to be quite large for the implementation to be faster than a simple randomized selection of the pivot.
Randomly selecting the pivot makes the worst case very unlikely. That makes random pivot selection good enough for most implementations of the algorithm.
Timing Your Quicksort Implementation
By now, you’re familiar with the process for timing the runtime of the algorithm. Just change the name of the algorithm in line 8:
if __name__ == "__main__":
# Generate an array of `ARRAY_LENGTH` items consisting
# of random integer values between 0 and 999
array = [randint(0, 1000) for i in range(ARRAY_LENGTH)]
# Call the function using the name of the sorting algorithm
# and the array you just created
run_sorting_algorithm(algorithm="quicksort", array=array)
You can execute the script as you have before:
python sorting.py
#
# Algorithm: quicksort. Minimum execution time: 0.11675417600002902
Not only does Quicksort finish in less than one second, but it’s also much faster than merge sort (0.11 seconds versus 0.61 seconds). Increasing the number of elements specified by ARRAY_LENGTH from 10,000 to 1,000,000 and running the script again ends up with merge sort finishing in 97 seconds, whereas Quicksort sorts the list in a mere 10 seconds.
Analyzing the Strengths and Weaknesses of Quicksort
True to its name, Quicksort is very fast. Although its worst-case scenario is theoretically , in practice, a good implementation of Quicksort beats most other sorting implementations. Also, just like merge sort, Quicksort is straightforward to parallelize.
One of Quicksort’s main disadvantages is the lack of a guarantee that it will achieve the average runtime complexity. Although worst-case scenarios are rare, certain applications can’t afford to risk poor performance, so they opt for algorithms that stay within regardless of the input.
Just like merge sort, Quicksort also trades off memory space for speed. This may become a limitation for sorting larger lists.
A quick experiment sorting a list of ten elements leads to the following results:
Algorithm: bubble_sort. Minimum execution time: 0.0000909000000000014
Algorithm: insertion_sort. Minimum execution time: 0.00006681900000000268
Algorithm: quicksort. Minimum execution time: 0.0001319930000000004
The results show that Quicksort also pays the price of recursion when the list is sufficiently small, taking longer to complete than both insertion sort and bubble sort.