round(0.5)는 0도 맞고 1도 맞습니다
round(0.5)는 0도 맞고 1도 맞습니다 관련


세상에는 수많은 프로그래밍 언어와 이를 활용해 개발된 소프트웨어가 존재합니다. 프로그래밍 언어는 소프트웨어를 개발하는 데 사용되는 도구이며, 이를 통해 다양한 기능을 수행할 수 있는 소프트웨어가 만들어집니다. 특히 우리는 복잡한 계산이나 데이터 분석을 할 때, 다양한 프로그래밍 언어와 소프트웨어를 사용합니다. 그러나 소프트웨어마다 계산 방식이나 수학적 라이브러리가 다를 수 있어, 동일한 문제를 다루더라도 결과가 다를 수 있습니다. 이러한 차이를 최소화하여 데이터 분석의 일관성을 유지하는 것은 매우 중요한 과제입니다.
이번 글에서는 이러한 소프트웨어 간 계산 차이의 예시(Rounding)와 이유를 살펴보고, 이러한 문제를 해결하고자 진행 중인 ‘CAMIS’ 연구 프로젝트에 대해 알아보겠습니다.
소프트웨어의 규칙
프로그래밍 언어는 아래 첨부한 ‘어쩔랭’같은 특수한 경우를 제외하면 사용하기 쉽거나, 특정 연산과 기능을 제공하거나, 라이브러리를 통해 확장이 가능하다 등의 특징을 가져야 합니다.
assertive-lang/asserlang) 깃허브 리포지토리>이어서 **“동일한 입력값으로 동일한 연산을 수행하면 동일한 출력이 나와야 한다”**라는 특징은 모든 프로그래밍 언어와 이들이 만들어내는 수많은 소프트웨어, 비즈니스까지 근본적인 약속이 됩니다.
예를 들어, “1+1” 같은 합 연산을 사용한다면, 개발자가 의도적으로 + 연산자를 다른 연산으로 오버로딩하거나, 해당 프로그래밍 언어에서 다른 목적으로 정의하지 않는 이상 언제나 2라는 결과를 만들어야 합니다. 그렇지 않으면 의도치 않은 오류가 생기고, 더 나아가 이로 인한 리소스를 필요로 하게 되죠.
r/ProgrammerHumor)>또한 프로그래밍 언어는 일반적인 개발뿐만 아니라 데이터 과학에서도 중요한 역할을 합니다. 예를 들어, 퍼널 분석을 통해 프로덕트를 개선하는 과정에서 ‘이벤트를 진행하기 전과 후의 퍼널 단계의 이탈률을 비교하고, 통계적 유의성을 계산하기 위해 비율 검정을 수행하는 경우’를 생각해 볼 수 있습니다.
데이터 과학자 또는 데이터 분석가들은 각자 익숙한 방법을 사용하기 때문에, 위와 같은 작업을 위해 SAS나 Python, R 등 다양한 선택지를 활용합니다. 대부분 속해있는 조직에서 사용 중인 레거시와 코드 베이스를 기준으로 하지만, 결과만 만들어 낼 수 있다면 방법은 자유롭게 허용하는 조직도 있습니다.
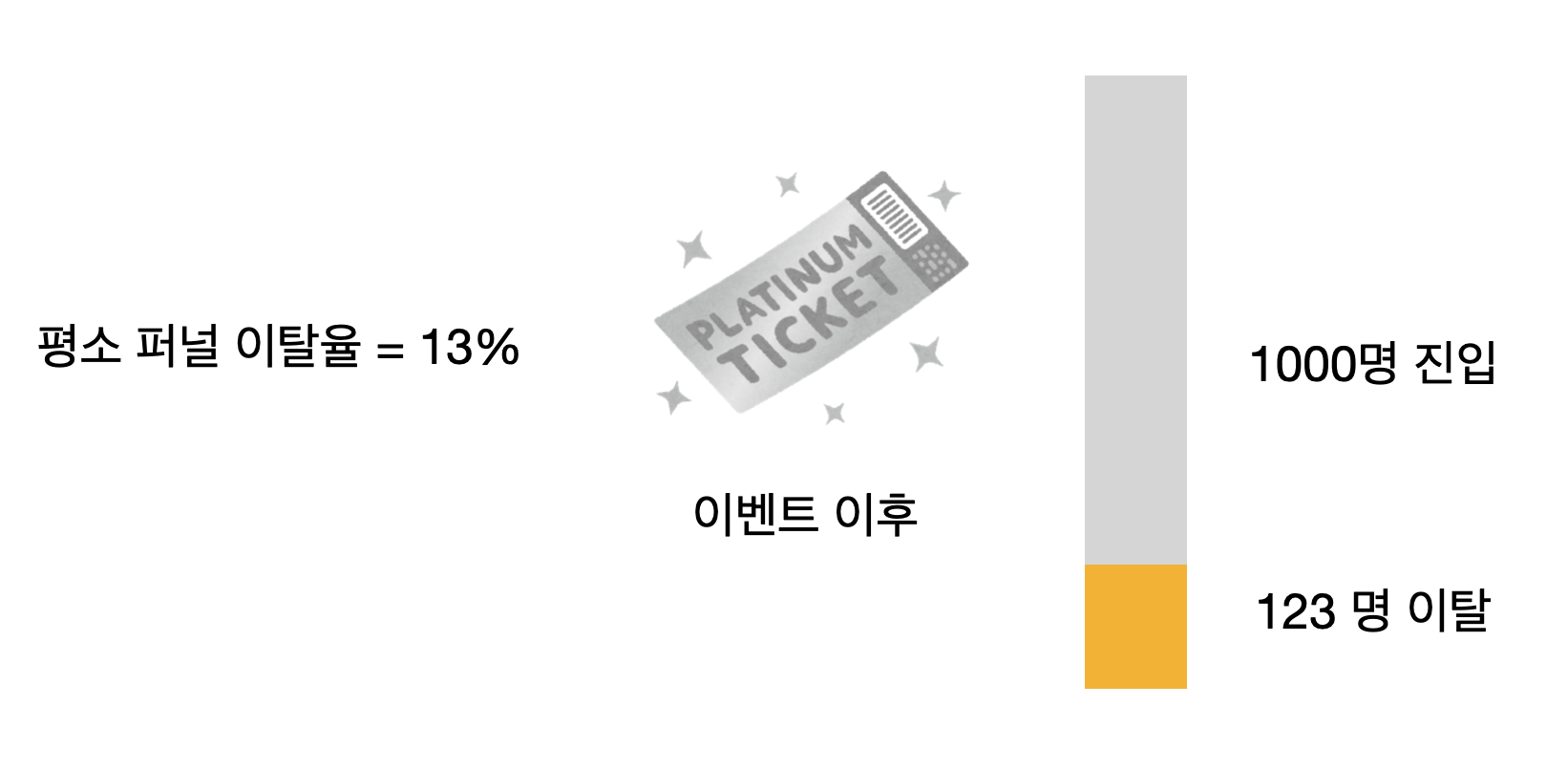
그런데 여기서 만약 사용한 프로그래밍 언어와 소프트웨어에 따라, 다른 결과가 만들어진다면 어떤 문제가 발생할까요? 다음 이미지는 예시의 값으로 비율 검정을 R과 Python, STATA에서 실행한 결과입니다.

여기서 1,000명과 123명이라는 동일한 값을 사용했지만, 비율 검정의 유의성을 나타내는 p-value가 방법에 따라 조금씩 다른 것을 확인할 수 있습니다. 이렇게 사용한 방법에 따라 연산 값이 다른 이유는 프로그래밍 언어의 코어 로직 알고리즘이 다르거나, 함수에 쓰이는 파라미터의 기본 설정값이 다른 것 등 여러 이유가 있습니다.
즉, 위 예시에서 R을 사용할 때 ‘correct’라는 파라미터의 값을 바꾸어, “연속성 수정”을 연산에 반영하면 결과가 STATA와 동일하게 나오는 것을 확인할 수 있습니다.

Rounding 사례 살펴보기
이번에는 데이터 과학에서 주로 쓰이는 통계 분석 방법이 아닌, 조금 더 일반적인 상황으로 ‘round(반올림)’ 사례를 자바스크립트를 포함해 비교해 보겠습니다.
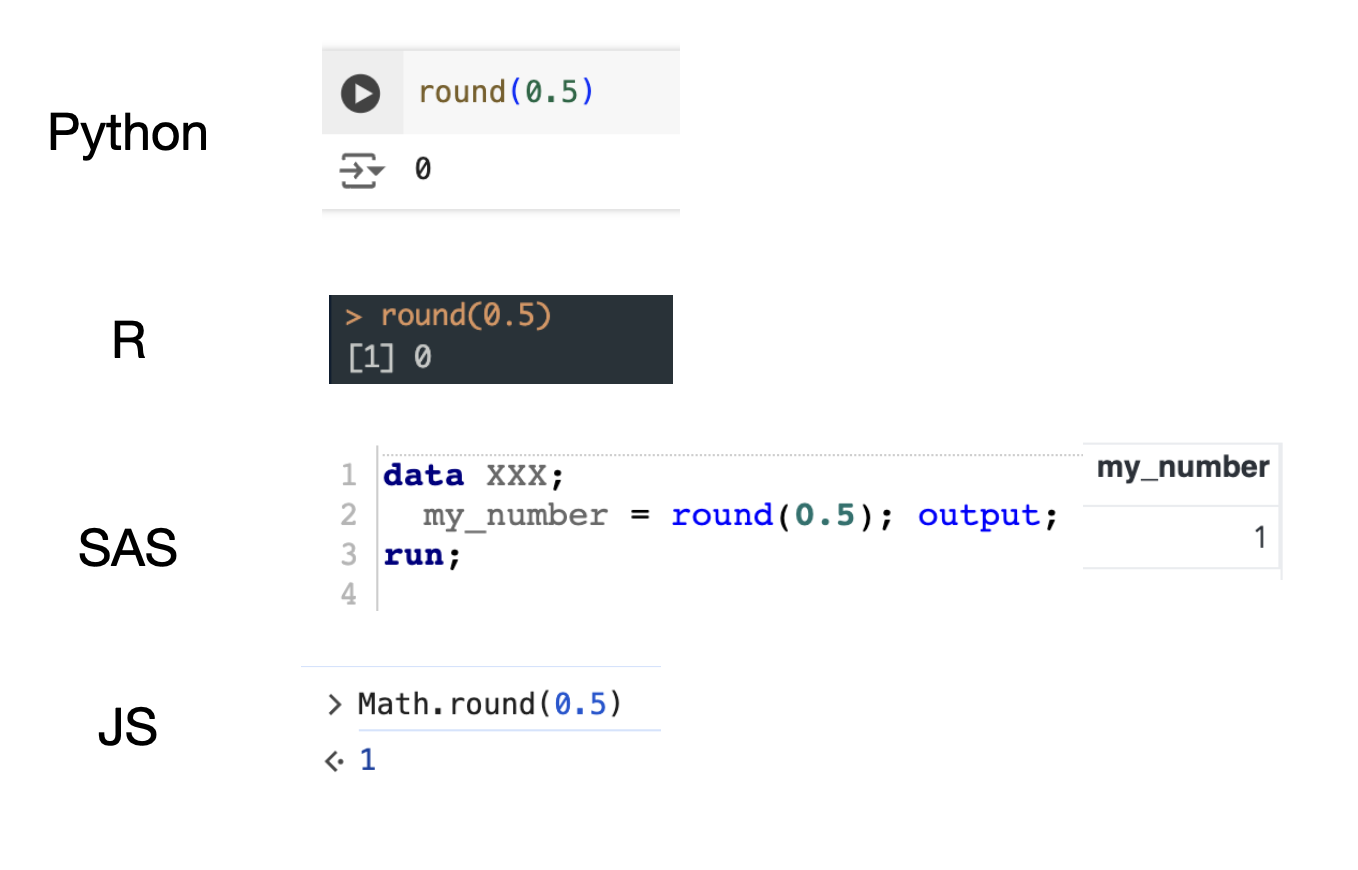
마찬가지로 를 반올림하는 단순한 round 함수도 사용하는 언어에 따라, 값이 바뀌는 것을 확인할 수 있습니다. 만약 대규모 금융 거래에서 내야 할 수수료가 0.5억이라면 반올림을 어떤 방법으로 계산하느냐에 따라 비용이 0원이 될 수도, 1억이 될 수도 있습니다. 또한 개발이 아닌 데이터 과학에서는 로지스틱 회귀에서 round를 사용하여, 예측 결과가 반대로 바뀌어 버릴 수도 있습니다.
Round는 왜 다를까?
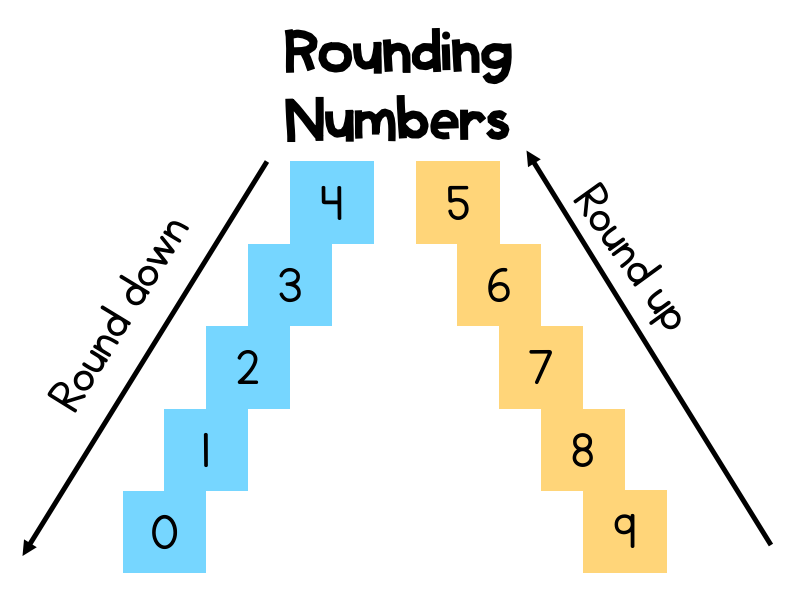
이번엔 round의 결과가 다른 이유에 대해 조금 더 설명해 보고자 합니다. 우리가 일반적으로 인지하는 반올림은 아래 그림처럼 0~4는 0으로, 5~9는 10으로 변경하는 방법을 의미합니다.
정수가 아닌 소수점 단위에서의 반올림은 .0~.4999…는 0으로, .5~.9999…는 1로 바꾸어 가장 가까운 정수로 반올림합니다. 그런데 여기서 값이 정확하게 인 경우와 음수일 때는 여러 가지 수학적인 해석을 할 수 있습니다.
만약 값이 음수라면, 예를 들어 round(-23.5)는 과 중 어떤 결과를 만들어야 할까요? 정답은 둘 다 가능하며, 각각 ‘Rounding half up’, ‘Rounding half down’이라는 이름으로 표현합니다.
여기서 더 나아가 양수와 음수를 모두 0에 가깝거나, 그 반대로 반올림하는 방법도 있습니다. 즉, round(-23.5)는 -23으로 round(23.5)는 23으로 반올림하거나, 각각 -24와 24로 반올림하게 됩니다. (각각 Rounding half toward zero, Rounding half away from zero라는 이름으로 표현합니다.)
마지막으로 ‘Rounding half to even’과 ‘Rounding half to odd’라는 방법이 있는데, 각각 가까운 정수를 짝수와 홀수로 간주하겠다는 의미를 갖습니다.
특히 Rounding half to even 방법은 Convergent rounding, Statistician’s rounding, Dutch rounding, Gaussian rounding, Bankers’ rounding이라는 이름으로도 불리며, IEEE 754에 따른 공식 표준 방법의 하나이기도 합니다.
Bankers’ rounding
Rounding half to even 방법이 많이 나온 만큼, 나오게 된 배경을 좀 더 설명해 보겠습니다. 아래 이미지는 부터 까지의 rounding 결과를 나타낸 그림입니다.
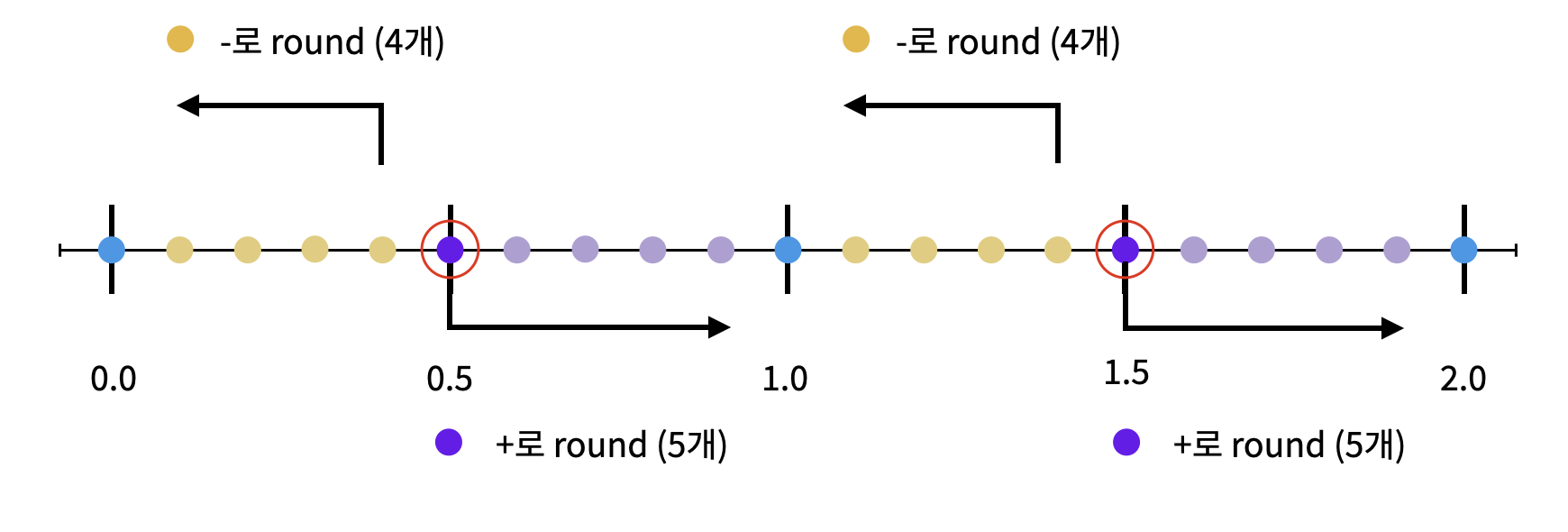
이는 문제가 없어 보이지만, 사실 한 가지 문제가 있습니다. 바로 가 무조건 다음 정수로 반올림되기 때문에, + 값으로 반올림되는 Bias가 무조건 발생한다는 것입니다.
그래서 아래와 같이 반올림을 수정하면, 이전에 발생하던 Bias를 피할 수 있게 됩니다.
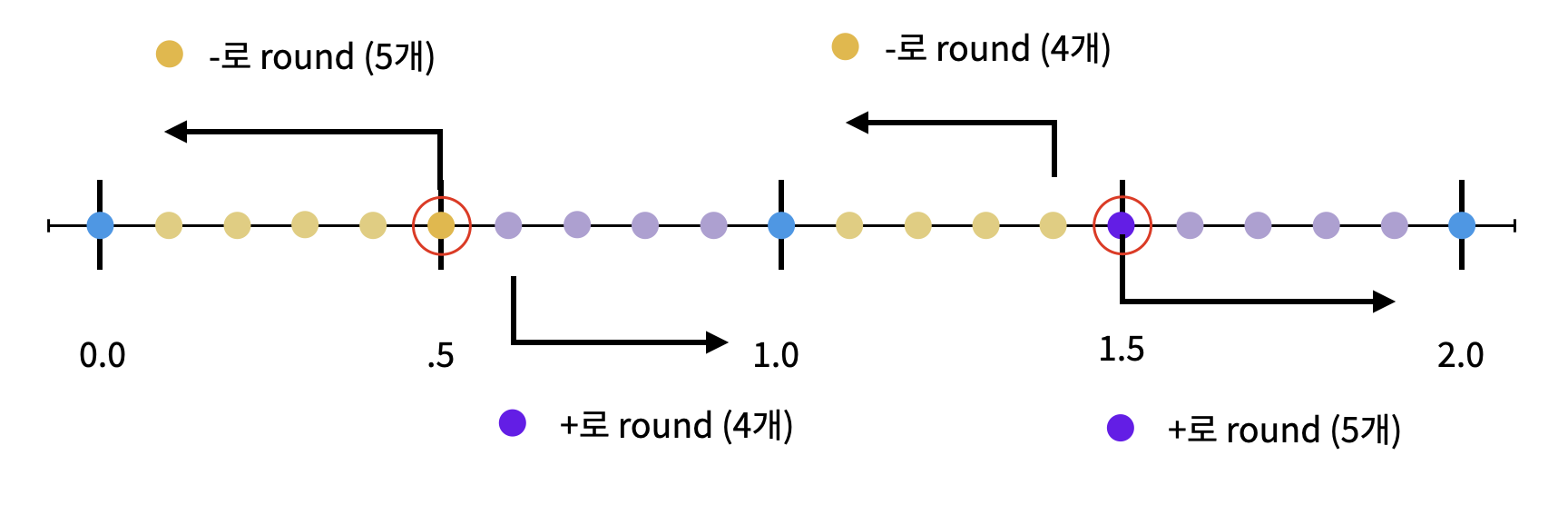
서로 다른 결과가 만들어내는 문제점
최근 제약과 금융 산업을 포함한 여러 산업에서 기존의 SPSS, SAS, Stata 등의 ‘상업용 소프트웨어’에서 파이썬과 R, 줄리아 (Julia) 같은 ‘오픈소스 소프트웨어’로의 전환을 시도하고 있습니다. 동시에 위 사례처럼 결과가 바뀌는 문제점도 함깨 제기되고 있죠.
비율 검정 사례처럼 p-value가 0.25 ~ 0.27의 다른 값을 갖는다면, 값은 다르더라도 유의성이 있지 않다는 큰 맥락에서 차이가 없어, 문제가 크게 발생하지는 않습니다. 그러나 만약 R을 사용했을 때는 p-value가 로, 파이썬을 사용했을 때는 으로 나온다면 이 결과를 다른 팀원 또는 이해관계자들에게 어떻게 공유해야 할까요? (이는 p-해킹 혹은 체리피킹으로 표현되는 ‘유리한 결과를 선택’하는 방향으로 이어지기도 합니다.)
또는 이전에 SAS를 사용했을 때 유의성 있던 신약 임상시험 결과가, 프로젝트 마이그레이션 이후 R을 사용했을 때 유의성이 있지 않다는 결과가 나온다면, 식약처나 FDA와 같은 규제기관에서는 기존 규제에 대해 어떻게 대처해야 할까요?
이처럼 검증이 되지 않은 상태로 여러 방법을 혼용하는 과정은 재현성(Reproducibility)과 불확정성(Uncertainty), 정확성(Accuracy), 추적가능성(Traceability)의 관점에서 큰 문제를 만들 수 있습니다.
물론 소프트웨어와 방법마다 철학, 목적, 연산 옵션 그리고 코어 알고리즘이 다를 수 있기 때문에 결과가 같을 필요는 없습니다. 그러나 현재 여러 방법을 활용하고 있다면, 그 방법에 따라 결과가 다른 이유와 동일한 결과를 만들어내려면 어떻게 해야 할지 알고 있어야 합니다.
CAMIS 프로젝트

CAMIS는 ‘Comparing Analysis Method Implementations in Software’의 줄임말로, 앞서 소개한 것처럼 여러 소프트웨어를 사용할 때 나타날 수 있는 계산 방법의 차이를 비교하고, 동일한 결과를 내는 방법과 표준을 연구하는 프로젝트입니다.
프로젝트의 핵심 영역은 계산인 만큼, 웹이나 앱 개발 같은 일반적인 개발 업계보다는 데이터 과학 업계에서 더 많이 기여하고 있습니다. 그러나 특정 도메인에 제한을 두지 않아, 전 세계 다양한 사람들이 정기적인 논의와 협업, 프로젝트 진행 공유 등으로 만들어 가는 오픈소스 프로젝트입니다.
다음은 CAMIS 프로젝트 웹 페이지에 공개된 비교 사례인데요. 단일 그룹 t 검정(One sample t-test)을 각 소프트웨어로 어떻게 실행하고 결과가 어땠는지, 마지막으로는 서로 간의 결과를 어떻게 호환할 수 있는지 등을 리뷰하고 있습니다.
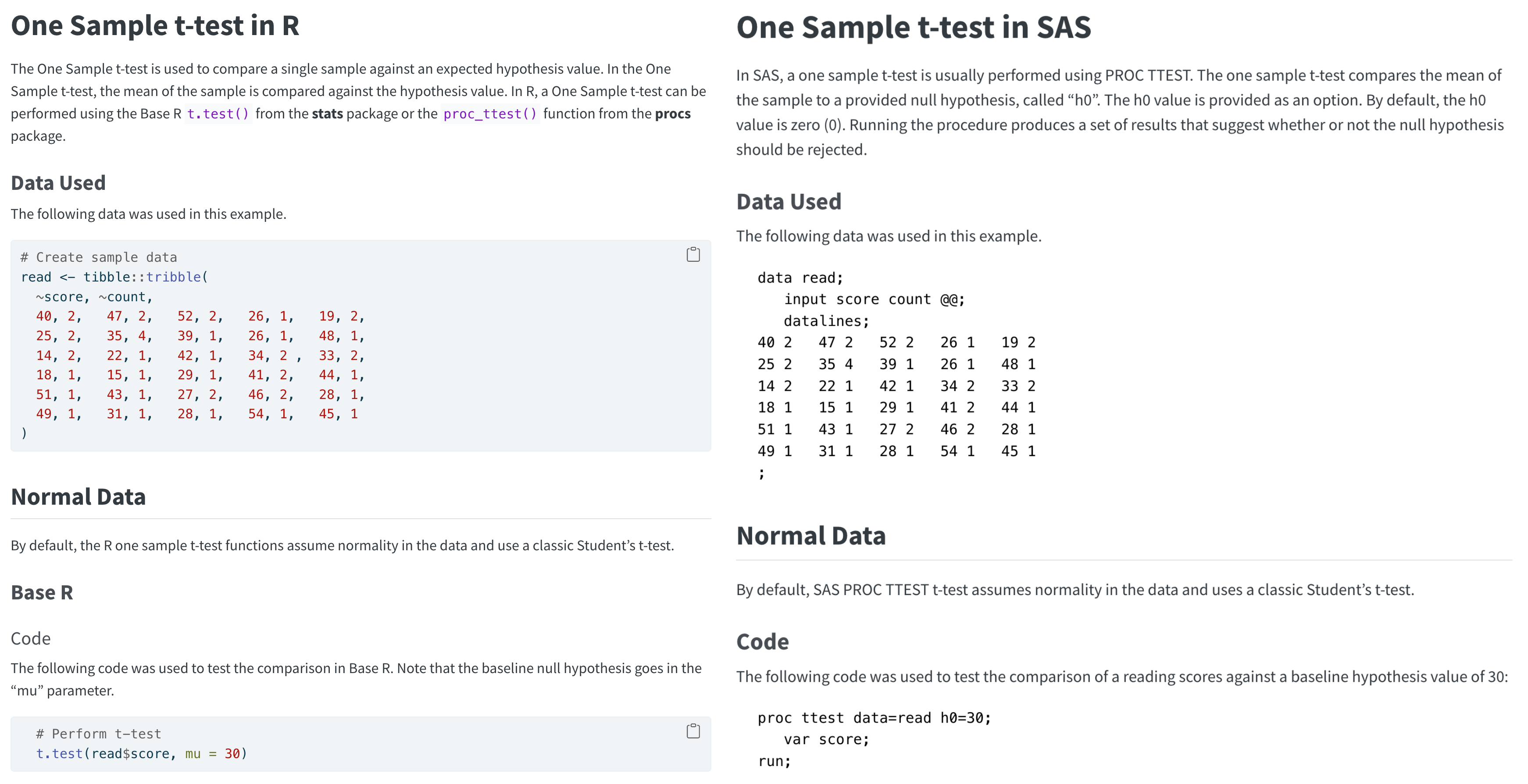
CAMIS 프로젝트는 최근 의학, 제약 업계의 트렌드 중 하나인 ‘SAS에서 R로의 전환’에 관심 있는 구성원들이 시작한 프로젝트인데요. 주요 통계 데이터 분석에 대해 R과 SAS 위주로 다루고 있지만, 최근에는 데이터 과학에서 더 넓게 활용하는 파이썬도 함께 연구하고 있습니다.
또한 고전적인 통계 분석 방법 외에도, 베이지안 통계(Bayesian statistics), 인과 추론(Causal inference), 기존 분석 방법의 새로운 접근법 구현(MMRM: Mixed Model for Repeated Measurements) 등 현대 데이터 과학 주제에 대한 작업이 예정되어 있습니다. 이에 더해 많은 연구자와 기여자들이 여러 컨퍼런스, 세미나에서 프로젝트를 홍보하거나, 레퍼런스로서의 활용을 권장하는 세션도 점차 늘고 있고요.
마지막으로 CAMIS 프로젝트는 ‘The American Statistician’과 ‘Drug Information Association’ 등 오래전부터 비슷한 내용의 논문이 출판된 적이 있는 만큼, 데이터 과학 산업계를 넘어 다양한 학계와 협업하고 있습니다. 최근에는 학생들과 “A comparison of MMRM methodology in SAS and R software(SAS와 R 소프트웨어의 MMRM 방법론 비교)”라는 제목으로 논문 작업이 진행 중이며, 그 외의 주제에서도 협업, 제안에 적극적으로 열려있습니다.

정리
한때 개발자들 사이에서는 여러 가지 프로그래밍 언어를 사용하는 개념이 ‘폴리글랏(polyglot)’이라는 이름으로 소개되기도 했습니다. 예를 들어, 백엔드는 자바와 SQL로 작성하고, 프론트엔드는 리엑트(자바스크립트), 데이터 처리는 파이썬으로 하는 경우를 생각해 볼 수 있습니다.

이는 데이터 과학자들에게도 낯설지 않은 개념으로, 특히 도메인에 따라 조직에서 사용 중인 라이브러리나 소프트웨어가 특정 언어에 종속되어, 개인이 선호하는 방법과 혼용되는 경우가 있습니다. 그래서 이때 주의하지 않으면, 방법에 따라 결과가 달라질 수도 있죠.
만약 데이터 분석 작업에서 여러 소프트웨어를 사용한다면, 각 소프트웨어의 차이점을 이해하고 의도한 최적의 방법을 시도해 보면 좋겠습니다. 또한 현재 데이터 과학 관련 업무를 하고 있다면, CAMIS 프로젝트에 관심을 두거나 기여하며, 글로벌 협업에 도전해 보는 것도 추천합니다.
