Introduction to Unsupervised Learning
Introduction to Unsupervised Learning 관련

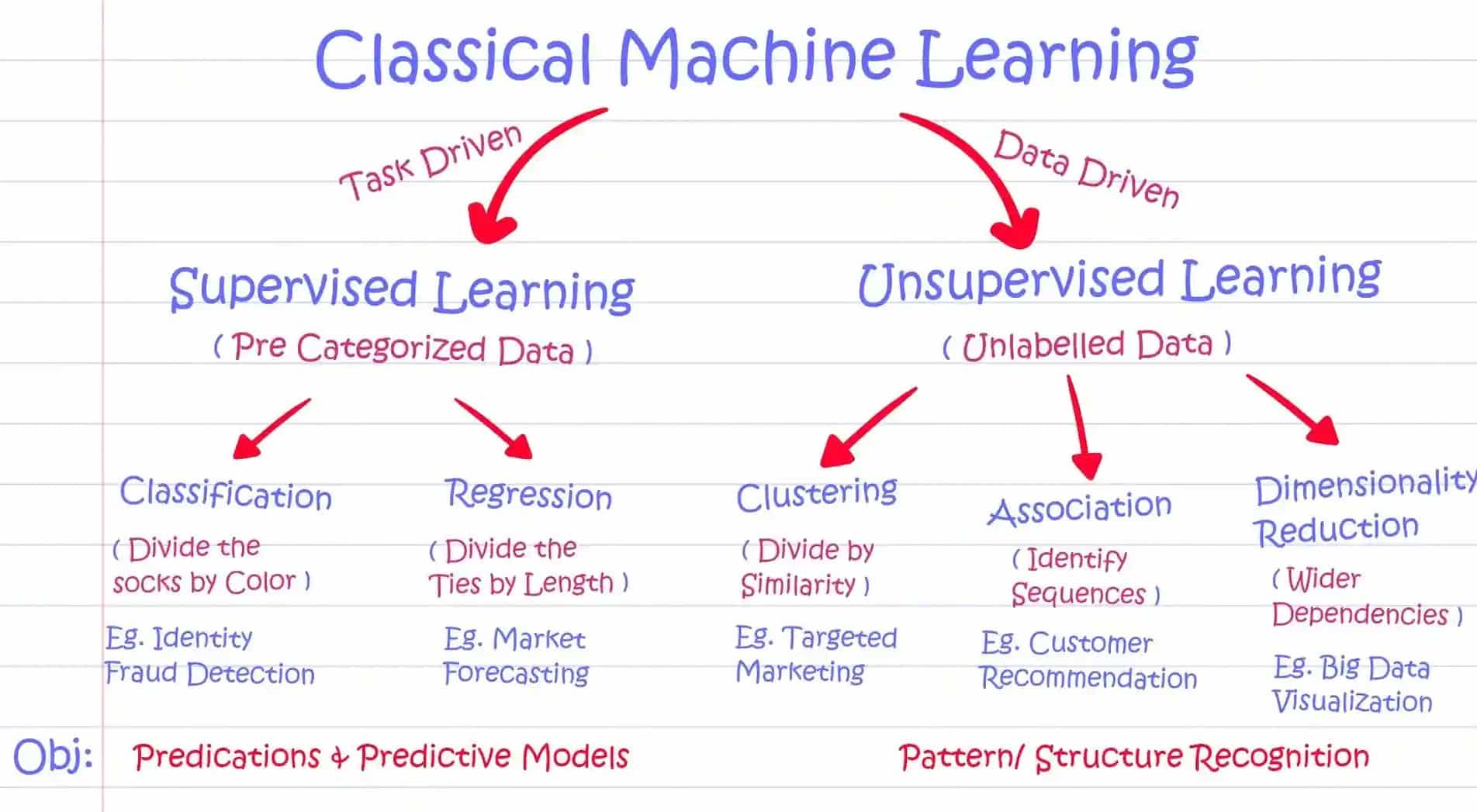
Unsupervised learning is a powerful technique in machine learning. It allows us to uncover hidden patterns and structures within data without any predefined labels or target variables. Unlike supervised learning, which relies on labeled data for training, unsupervised learning lets us explore and understand the inherent structure within unlabeled datasets.
One key application of unsupervised learning is clustering. Clustering is the process of grouping similar data points together based on their intrinsic characteristics and similarities. By identifying patterns and relationships within datasets, clustering helps us gain valuable insights and make sense of complex data.
Clustering finds its significance in various domains, including customer segmentation, anomaly detection, image recognition, and recommendation systems. It enables us to identify distinct groups within data, classify data into meaningful categories, and understand the underlying trends driving datasets.
In the next sections, we will delve deeper into different clustering algorithms, such as K-Means, hierarchical clustering, and DBSCAN, exploring their theories, implementations, and visualizations. By the end of this handbook, you will have a comprehensive understanding of unsupervised learning and be equipped with the knowledge and skills to apply various clustering techniques to your own data analysis tasks.
Remember, clustering is just one aspect of unsupervised learning, which offers a range of other techniques and applications. So, let’s dive in and discover the exciting world of unsupervised learning and the power it holds for extracting insights from unlabeled data.