
Public Key Cryptography Standards (PKCS#1 v1.5)
Public Key Cryptography Standards (PKCS#1 v1.5) 관련

In 1998, Kaliski and RSA Laboratories introduced PKCS#1 v1.5 to the world in a public publication[1]. In PKCS#1 v1.5, every RSA‐encrypted message is wrapped inside a special “encryption block” . This block ensures that the raw message is both the right size for RSA and padded in a way that’s hard to tamper with.
In this scheme, the plaintext is padded to the size of the modulus (in bytes) as:
Here, (Leading Zero Byte) is always at the front. It ensures that, when the concatenated string is converted to a big‐endian integer, the value is less than the RSA modulus (that is, we don’t end up with a number too large for RSA to handle). You will better appreciate this fact when we dive into the mathematics behind this.
The next octet is the Block Type, , which tells us the “type” of padding being used. The standard defines three possible values: , , and - to support different operations. For example, and is used for private-key operations (such as digital signatures) and is used for public-key operations. For encryption under PKCS#1 v1.5, this is always 0x02. It’s basically a label that says, “This is an encryption block, not something else”.
The next block is the Padding String . This is a string of nonzero random bytes. This is crucial for security because it introduces randomness into each encryption. If the same message is encrypted multiple times, these random bytes ensure that each ciphertext looks different, foiling many simple attacks that rely on seeing repeated patterns.
The next octet, , is a Delimiter. This single zero byte marks the end of the padding. During decryption, this helps the recipient quickly identify where the padding stops and the real message begins.
Finally, we have the actual data you want to protect - . Once the recipient has verified the padding, they know exactly where to find this message.
This mechanism helped solve the deterministic issue of naive RSA. In the next sections, let’s understand the mathematics involved in PKCS#1 v1.5 padding and its security implications.
The Mathematics Behind PKCS#1 v1.5
Before we begin, let’s get our symbols and abbreviations correct. We will use upper-case symbols (such as ) to denote octet strings and bit strings. We will use lower-case symbols (such as ) to denote integers.
In PKCS#1 v1.5, we will use k to represents the length of the RSA modulus in bytes. For example, if you have a 1024-bit RSA key, then the RSA modulus n is a 1024-bit number. Since there are 8 bits in a byte, if your RSA modulus is L bits long, then:
The total length of the encryption block will be equal to this RSA key length (in bytes). Now here the length of the data M shall not be more than k−11 octets, since the bytes are consumed by the blocks - . This limitation guarantees that the length of the padding string is at least eight octets, which is a security condition in PKCS#1v1.5:
For example, with a 1024-bit RSA modulus, the value of comes out to be . Here Alice could encrypt up to bytes of data. The bytes are used for the structure. The random ensures that each encryption of the same message produces a different ciphertext, preventing the deterministic encryption problem.
RSA doesn’t directly operate on the bytes. Once the padded string is ready, it needs to be converted into an integer guided by the Octet String to Integer Primitive (OS2IP) formula:
where are the octets of from first to last. In other words, (the first byte) is the most significant byte, and (the last byte) is the least significant. Now Alice can simply encrypt this block using .
To solidify our learnings so far, let’s apply this to a sample plaintext and find the padded blocks.
Let’s assume the RSA modulus is 8 bytes long . Suppose we want to encrypt a message that is bytes long. Then the padding string must fill the remaining space:
Since and there are fixed bytes, can find the required length of the padding string:
Let’s pick 3 arbitrary nonzero bytes for , say - , , . And let’s say the message is the ASCII text “Hi”. In hexadecimal, that’s: for '' and for ''.
Thus, the complete encryption block becomes:
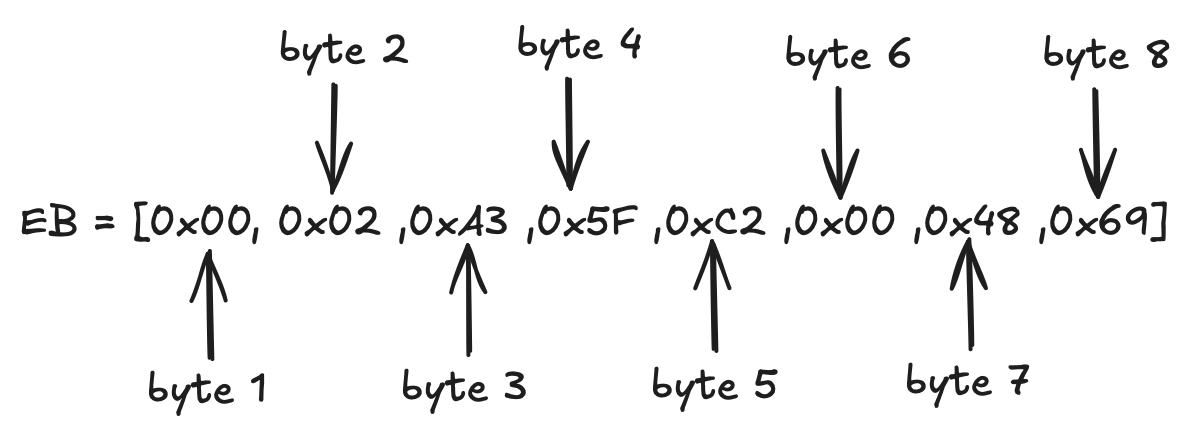
Now we will convert this octet string to an integer using the OS2IP formula we discussed above:
For our example, with the conversion is:
Note that the hexadecimal values can be converted to decimal as needed. For instance, , , , , and . There is an interesting observation in the application of this formula. Because the first two bytes are fixed ( and ), the integer x has a known lower bound. The contribution of the first two bytes is:
The rest of the bytes (, the delimiter, and ) add some value that is at least and at most just less than (since the second byte is fixed as and cannot be ). Thus, is in the range:
This property which makes the range predictable, paved the way for the Bleichenbacher attack (also known as the “padding oracle” attack). If a system reveals whether a decrypted block is “correctly padded,” an attacker can systematically probe different ciphertexts and narrow down the plaintext - because the attacker knows it must lie in that narrow range. Let’s take a detailed look at the Bleichenbacher attack in the next sections and understand how the exploit works.
RFC 2313: PKCS #1: RSA Encryption ↩︎