
How to Build a RAG Pipeline with LlamaIndex
How to Build a RAG Pipeline with LlamaIndex 관련


Large Language Models are everywhere these days - think ChatGPT - but they have their fair share of challenges.
One of the biggest challenges faced by LLMs is hallucination. This occurs when the model generates text that is factually incorrect or misleading, often based on patterns it has learned from its training data. So how can Retrieval-Augmented Generation, or RAG, help mitigate this issue?
By retrieving relevant information from a more vast, wider knowledge base, RAG ensures that the LLM's responses are grounded in real-world facts. This significantly reduces the likelihood of hallucinations and improves the overall accuracy and reliability of the generated content.
Table of Contents
What is Retrieval Augmented Generation (RAG)?
RAG is a technique that combines information retrieval with language generation. Think of it as a two-step process:
- Retrieval: The model first retrieves relevant information from a large corpus of documents based on the user's query.
- Generation: Using this retrieved information, the model then generates a comprehensive and informative response.
Why use LlamaIndex for RAG?
LlamaIndex is a powerful framework that simplifies the process of building RAG pipelines. It provides a flexible and efficient way to connect retrieval components (like vector databases and embedding models) with generation components (like LLMs).
Some of the key benefits of using Llama-Index include:
- Modularity: It allows you to easily customize and experiment with different components.
- Scalability: It can handle large datasets and complex queries.
- Ease of use: It provides a high-level API that abstracts away much of the underlying complexity.
What You'll Learn Here:
In this article, we will delve deeper into the components of a RAG pipeline and explore how you can use LlamaIndex to build these systems.
We will cover topics such as vector databases, embedding models, language models, and the role of LlamaIndex in connecting these components.
Understanding the Components of a RAG Pipeline
Here's a diagram that'll help familiarize you with the basics of RAG architecture:
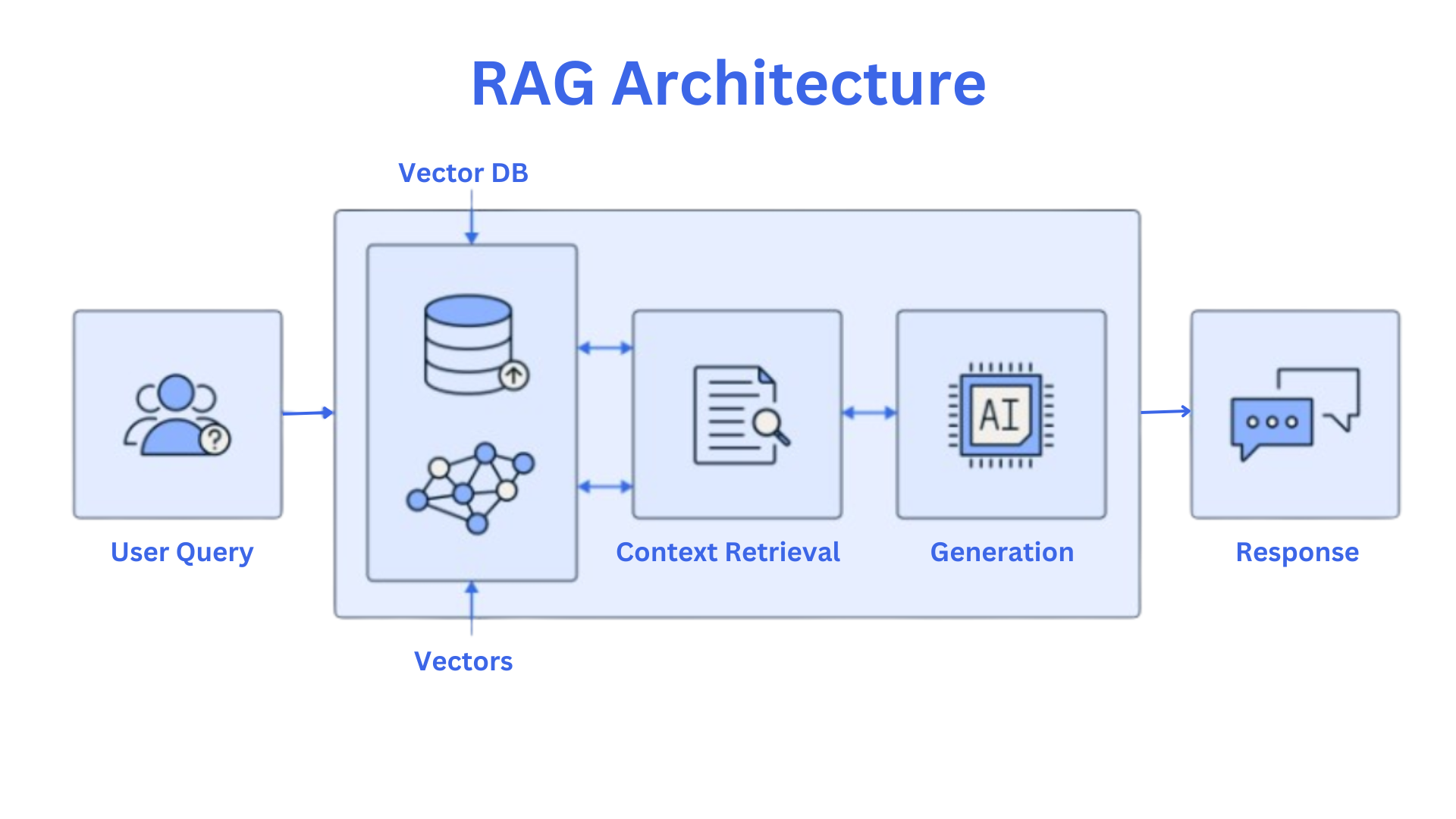
This diagram is inspired by this article Let's go through the key pieces.
Components of RAG
- Vector Databases: These databases are optimized for storing and searching high-dimensional vectors. They are crucial for efficiently finding relevant information from a vast corpus of documents.
- Embedding Models: These models convert text into numerical representations or embeddings. These embeddings capture the semantic meaning of the text, allowing for efficient comparison and retrieval in vector databases.
A vector is a mathematical object that represents a quantity with both magnitude (size) and direction. In the context of RAG, embeddings are high-dimensional vectors that capture the semantic meaning of text. Each dimension of the vector represents a different aspect of the text's meaning, allowing for efficient comparison and retrieval.
- Language Models: These models are trained on massive amounts of text data, enabling them to generate human-quality text. They are capable of understanding and responding to prompts in a coherent and informative manner.
The RAG Flow
- Query Submission: A user submits a query or question.
- Embedding Creation: The query is converted into an embedding using the same embedding model used for the corpus.
- Retrieval: The embedding is searched against the vector database to find the most relevant documents.
- Contextualization: The retrieved documents are combined with the original query to form a context.
- Generation: The language model generates a response based on the provided context.
LamaIndex
LlamaIndex plays a crucial role in connecting the retrieval and generation components. It acts as an index that maps queries to relevant documents. By efficiently managing the index, LlamaIndex ensures that the retrieval process is fast and accurate.
Prerequisites
We will be using Python and IBM watsonx> via LlamaIndex in this article. You should have the following on your system before getting started:
- Python 3.9+
- IBM watsonx project and API key
- Curiosity to learn
Let's Get Started!
In this article, we will be using LlamaIndex to make a simple RAG Pipeline.
Let's create a virtual environment for Python using the following command in your terminal: python -m venv venv . This will create a virtual environment (venv) for your project. If you are a Windows user you can activate it using .\venv\Scripts\activate, and Mac users can activate it with source venv/bin/activate.
Now let's install the packages:
pip install wikipedia llama-index-llms-ibm llama-index-embeddings-huggingface
Once these packages are installed, you will need watsonx.ai's API key as well. This in turn will help you use LLMs via LlamaIndex.
To learn about how to get your watsonx.ai API keys, click here. You need the project ID and API Key to be able to work on the "Generation" aspect of RAG. Having them will help you make LLM calls through watsonx.ai.
import wikipedia
# Search for a specific page
page = wikipedia.page("Artificial Intelligence")
# Access the content
print(page.content)
Now let's save the page content to a text document. We are doing it so that we can access it later. You can do this using the below code:
import os
# Create the 'Document' directory if it doesn't exist
if not os.path.exists('Document'):
os.mkdir('Document')
# Open the file 'AI.txt' in write mode with UTF-8 encoding
with open('Document/AI.txt', 'w', encoding='utf-8') as f:
# Write the content of the 'page' object to the file
f.write(page.content)
Now we'll be using watsonx.ai via LlamaIndex. It will help us generate responses based on the user's query.
Note: Make sure to replace the parameters WATSONX_APIKEY and project_id with your values in the below code:
import os
from llama_index.llms.ibm import WatsonxLLM
from llama_index.core import SimpleDirectoryReader, Document
# Define a function to generate responses using the WatsonxLLM instance
def generate_response(prompt):
"""
Generates a response to the given prompt using the WatsonxLLM instance.
Args:
prompt (str): The prompt to provide to the large language model.
Returns:
str: The generated response from the WatsonxLLM.
"""
response = watsonx_llm.complete(prompt)
return response
# Set the WATSONX_APIKEY environment variable (replace with your actual key)
os.environ["WATSONX_APIKEY"] = 'YOUR_WATSONX_APIKEY' # Replace with your API key
# Define model parameters (adjust as needed)
temperature = 0
max_new_tokens = 1500
additional_params = {
"decoding_method": "sample",
"min_new_tokens": 1,
"top_k": 50,
"top_p": 1,
}
# Create a WatsonxLLM instance with the specified model, URL, project ID, and parameters
watsonx_llm = WatsonxLLM(
model_id="meta-llama/llama-3-1-70b-instruct",
url="https://us-south.ml.cloud.ibm.com",
project_id="YOUR_PROJECT_ID",
temperature=temperature,
max_new_tokens=max_new_tokens,
additional_params=additional_params,
)
# Load documents from the specified directory
documents = SimpleDirectoryReader(
input_files=["Document/AI.txt"]
).load_data()
# Combine the text content of all documents into a single Document object
combined_documents = Document(text="\n\n".join([doc.text for doc in documents]))
# Print the combined document
print(combined_documents)
Here's a breakdown of the parameters:
- temperature = 0: This setting makes the model generate the most likely text sequence, leading to a more deterministic and predictable output. It's like telling the model to stick to the most common words and phrases.
- max_new_tokens = 1500: This limits the generated text to a maximum of 1500 new tokens (words or parts of words).
- additional_params:
- decoding_method = "sample": This means the model will generate text randomly based on the probability distribution of each token.
- min_new_tokens = 1: Ensures that at least one new token is generated, preventing the model from repeating itself.
- top_k = 50: This limits the model's choices to the 50 most likely tokens at each step, making the output more focused and less random.
- top_p = 1: This sets the nucleus sampling probability to 1, meaning all tokens with a probability greater than or equal to the top_p value will be considered.
You can tweak these parameters for experimentation and see how they affect your response. Now we'll be building and loading a vector store index from the given document. But first, let's understand what it is.
Understanding Vector Store Indexes
A vector store index is a specialized data structure designed to efficiently store and retrieve high-dimensional vectors. In the context of the Llama Index, these vectors represent the semantic embeddings of documents.
Key characteristics of vector store indexes:
- High-dimensional vectors: Each document is represented as a high-dimensional vector, capturing its semantic meaning.
- Efficient retrieval: Vector store indexes are optimized for fast similarity search, allowing you to quickly find documents that are semantically similar to a given query.
- Scalability: They can handle large datasets and scale efficiently as the number of documents grows.
How Llama Index uses vector store indexes:
- Document Embedding: Documents are first converted into high-dimensional vectors using a language model like Llama.
- Index Creation: The embeddings are stored in a vector store index.
- Query Processing: When a user submits a query, it is also converted into a vector. The vector store index is then used to find the most similar documents based on their embeddings.
- Response Generation: The retrieved documents are used to generate a relevant response.
In the below code, you'll come across the word "chunk". A chunk is a smaller, manageable unit of text extracted from a larger document. It's typically a paragraph or a few sentences long. They are used to make the retrieval and processing of information more efficient, especially when dealing with large documents.
By breaking down documents into chunks, RAG systems can focus on the most relevant parts and generate more accurate and concise responses.
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import VectorStoreIndex, load_index_from_storage
from llama_index.core import Settings
from llama_index.core import StorageContext
def get_build_index(documents, embed_model="local:BAAI/bge-small-en-v1.5", save_dir="./vector_store/index"):
"""
Builds or loads a vector store index from the given documents.
Args:
documents (list[Document]): A list of Document objects.
embed_model (str, optional): The embedding model to use. Defaults to "local:BAAI/bge-small-en-v1.5".
save_dir (str, optional): The directory to save or load the index from. Defaults to "./vector_store/index".
Returns:
VectorStoreIndex: The built or loaded index.
"""
# Set index settings
Settings.llm = watsonx_llm
Settings.embed_model = embed_model
Settings.node_parser = SentenceSplitter(chunk_size=1000, chunk_overlap=200)
Settings.num_output = 512
Settings.context_window = 3900
# Check if the save directory exists
if not os.path.exists(save_dir):
# Create and load the index
index = VectorStoreIndex.from_documents(
[documents], service_context=Settings
)
index.storage_context.persist(persist_dir=save_dir)
else:
# Load the existing index
index = load_index_from_storage(
StorageContext.from_defaults(persist_dir=save_dir),
service_context=Settings,
)
return index
# Get the Vector Index
vector_index = get_build_index(documents=documents, embed_model="local:BAAI/bge-small-en-v1.5", save_dir="./vector_store/index")
This is the last part of RAG: we create a query engine with metadata replacement and sentence transformer reranking. Bruh! What is a re-ranker now?
A re-ranker is a component that reorders the retrieved documents based on their relevance to the query. It uses additional information, such as semantic similarity or context-specific factors, to refine the initial ranking provided by the retrieval system. This helps ensure that the most relevant documents are presented to the user, leading to more accurate and informative responses.
from llama_index.core.postprocessor import MetadataReplacementPostProcessor, SentenceTransformerRerank
def get_query_engine(sentence_index, similarity_top_k=6, rerank_top_n=2):
"""
Creates a query engine with metadata replacement and sentence transformer reranking.
Args:
sentence_index (VectorStoreIndex): The sentence index to use.
similarity_top_k (int, optional): The number of similar nodes to consider. Defaults to 6.
rerank_top_n (int, optional): The number of nodes to rerank. Defaults to 2.
Returns:
QueryEngine: The query engine.
"""
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
rerank = SentenceTransformerRerank(
top_n=rerank_top_n, model="BAAI/bge-reranker-base"
)
engine = sentence_index.as_query_engine(
similarity_top_k=similarity_top_k, node_postprocessors=[postproc, rerank]
)
return engine
# Create a query engine with the specified parameters
query_engine = get_query_engine(sentence_index=vector_index, similarity_top_k=8, rerank_top_n=5)
# Query the engine with a question
query = 'What is Deep learning?'
response = query_engine.query(query)
prompt = f'''Generate a detailed response for the query asked based only on the context fetched:
Query: {query}
Context: {response}
Instructions:
1. Show query and your generated response based on context.
2. Your response should be detailed and should cover every aspect of the context.
3. Be crisp and concise.
4. Don't include anything else in your response - no header/footer/code etc
'''
response = generate_response(prompt)
print(response.text)
'''
OUTPUT -
Query: What is Deep learning?
Deep learning is a subset of artificial intelligence that utilizes multiple layers of neurons between the network's inputs and outputs to progressively extract higher-level features from raw input data.
This technique allows for improved performance in various subfields of AI, such as computer vision, speech recognition, natural language processing, and image classification.
The multiple layers in deep learning networks are able to identify complex concepts and patterns, including edges, faces, digits, and letters.
The reason behind deep learning's success is not attributed to a recent theoretical breakthrough, but rather the significant increase in computer power, particularly the shift to using graphics processing units (GPUs), which provided a hundred-fold increase in speed.
Additionally, the availability of vast amounts of training data, including large curated datasets, has also contributed to the success of deep learning.
Overall, deep learning's ability to analyze and extract insights from raw data has led to its widespread application in various fields, and its performance continues to improve with advancements in technology and data availability. '''
How to Fine-Tune the Pipeline
Once you've built a basic RAG pipeline, the next step is to fine-tune it for optimal performance. This involves iteratively adjusting various components and parameters to improve the quality of the generated responses.
How to Evaluate the Pipeline's Performance
To assess the pipeline's effectiveness, you can use metrics like:
- Accuracy: How often does the pipeline generate correct and relevant responses?
- Relevance: How well do the retrieved documents match the query?
- Coherence: Is the generated text well-structured and easy to understand?
- Factuality: Are the generated responses accurate and consistent with known facts?
Iterate on the Index Structure, Embedding Model, and Language Model
You can experiment with different index structures (for example flat index, hierarchical index) to find the one that best suits your data and query patterns. Consider using different embedding models to capture different semantic nuances. Fine-tuning the language model can also improve its ability to generate high-quality responses.
Experiment with Different Hyperparameters
Hyperparameters are settings that control the behaviour of the pipeline components. By experimenting with different values, you can optimize the pipeline's performance. Some examples of hyperparameters include:
- Embedding dimension: The size of the embedding vectors
- Index size: The maximum number of documents to store in the index
- Retrieval threshold: The minimum similarity score for a document to be considered relevant
Real-World Applications of RAG
RAG pipelines have a wide range of applications, including:
- Customer support chatbots: Providing informative and helpful responses to customer inquiries
- Knowledge base search: Efficiently retrieving relevant information from large document collections
- Summarization of large documents: Condensing lengthy documents into concise summaries
- Question answering systems: Answering complex questions based on a given corpus of knowledge
RAG Best Practices and Considerations
To build effective RAG pipelines, consider these best practices:
- Data quality and preprocessing: Ensure your data is clean, consistent, and relevant to your use case. Preprocess the data to remove noise and improve its quality.
- Embedding model selection: Choose an embedding model that is appropriate for your specific domain and task. Consider factors like accuracy, computational efficiency, and interpretability.
- Index optimization: Optimize the index structure and parameters to improve retrieval efficiency and accuracy.
- Ethical considerations and biases: Be aware of potential biases in your data and models. Take steps to mitigate bias and ensure fairness in your RAG pipeline.
Conclusion
RAG pipelines offer a powerful approach to leveraging large language models for a variety of tasks. By carefully selecting and fine-tuning the components of an RAG pipeline, you can build systems that provide informative, accurate, and relevant responses.
Key points to remember:
- RAG combines information retrieval and language generation.
- Llama-Index simplifies the process of building RAG pipelines.
- Fine-tuning is essential for optimizing pipeline performance.
- RAG has a wide range of real-world applications.
- Ethical considerations are crucial in building responsible RAG systems.
As RAG technology continues to evolve, we can expect to see even more innovative and powerful applications in the future. Till then, let's wait for the future to unfold!