
Which Tools to Use for LLM-Powered Applications: LangChain vs LlamaIndex vs NIM
Which Tools to Use for LLM-Powered Applications: LangChain vs LlamaIndex vs NIM 관련


Well, two well-established frameworks—LangChain and LlamaIndex—have gained significant attention for their unique features and capabilities. But recently, NVIDIA NIM has emerged as a new player in the field, adding its tools and functionalities to the mix.
In this article, we'll compare LangChain, LlamaIndex, and NVIDIA NIM to help you determine which framework best fits your specific use case.
Introduction to LangChain
According to LangChain’s official docs, “LangChain is a framework for developing applications powered by language models”.
We can elaborate a bit on that and say that LangChain is a versatile framework designed for building data-aware and agent-driven applications. It offers a collection of components and pre-built chains that simplify working with large language models (LLMs) like GPT.
Whether you're just starting or you’re an experienced developer, LangChain supports both quick prototyping and full-scale production applications.
You can use LangChain to simplify the entire development cycle of an LLM application:
- Development: LangChain offers open-source building blocks, components and third-party integrations for building applications.
- Production: LangSmith, a tool from LangChain, helps monitor and evaluate chains for continuous optimization and deployment.
- Deployment: You can use LangGraph Cloud to turn your LLM applications into production-ready APIs.
LangChain offers several open-source libraries for development and production purposes. Let’s take a look at some of them.
LangChain Components
LangChain Components are high-level APIs that simplify working with LLMs. You can compare them with Hooks in React and functions in Python.
These components are designed to be intuitive and easy to use. A key component is the LLM interface, which seamlessly connects to providers like OpenAI, Cohere, and Hugging Face, allowing you to effortlessly query models.
In this example, we utilize the langchain_google_vertexai library to interact with Google’s Vertex AI, specifically leveraging the Gemini 1.5 Flash model. Let’s break down what the code does:
from langchain_google_vertexai import ChatVertexAI
llm = ChatVertexAI(model="gemini-1.5-flash")
llm.invoke(
"Who was Napoleon?"
)
Importing the ChatVertexAI Class:
The first step is to import the ChatVertexAI class, which allows us to communicate with the Google Vertex AI platform. This library is part of the LangChain ecosystem, designed to integrate large language models (LLMs) seamlessly into applications.
Instantiating the LLM (Large Language Model):
llm = ChatVertexAI(model="gemini-1.5-flash")
Here, we create an instance of the ChatVertexAI class. We specify the model we want to use, which in this case is Gemini 1.5 Flash. This version of Gemini is optimized for fast responses while still maintaining high-quality language generation.
Sending a Query to the Model:
llm.invoke("Who was Napoleon?")
Finally, we use the invoke method to send a question to the Gemini model. In this example, we ask the question, “Who was Napoleon?”. The model processes the query and provides a response, which would typically include information about Napoleon’s identity, historical significance, and key accomplishments.
Chains
LangChain defines Chains as “sequences of calls”. To understand how chains work, we need to know what LCEL is.
LCEL stands for LangChain Expression Language, which is a declarative way to easily compose chains together - that’s it. LCEL just helps us multiple combine chains in long chains.
LangChain supports two types of chains
- LCEL Chains: In this case, LangChain offers a higher-level constructor method. But all that is being done under the hood is constructing a chain with LCEL.
For example, create_stuff_documents_chain is an LCEL Chain that takes a list of documents and formats them all into a prompt, then passes that prompt to an LLM. It passes ALL documents, so you should make sure it fits within the context window of the LLM you are using. - Legacy Chains: Legacy Chains are constructed by subclassing from a legacy Chain class. These chains do not use LCEL under the hood but are the standalone classes.
For example, APIChain: this chain uses an LLM to convert a query into an API request, then executes that request, gets back a response, and then passes that request to an LLM to respond.
Legacy Chains were standard practices before LCEL. Once all the legacy chains get an LCEL alternative, they will become obsolete and unsupported.
LangChain Quickstart
Using LangChain with Google's Gemini Pro Model
This code demonstrates how to integrate Google’s Gemini Pro model with LangChain for natural language processing tasks.
pip install -U langchain-google-genai
First, install the langchain-google-genai package, which allows you to interact with Google’s Generative AI models via LangChain. The -U flag ensures you get the latest version.
Setting Up Your API Key
env GOOGLE_API_KEY="your-api-key"
You need to authenticate your API requests. Use your Google API key by setting it as an environment variable. This ensures secure communication with Google’s services.
Accessing the Gemini Pro Model
from langchain_google_genai import ChatGoogleGenerativeAI
The ChatGoogleGenerativeAI class is imported from the langchain-google-genai package. We instantiate it, specifying Gemini Pro—a powerful version of Google’s generative models known for producing high-quality language outputs.
Querying the Model
llm = ChatGoogleGenerativeAI(model="gemini-pro")
llm.invoke("Who was Alexander the Great?")
Finally, you invoke the model by passing a query. In this example, the query is asking for information about Alexander the Great. The model will return a detailed response, such as his historical background and significance.
Introduction to LlamaIndex
LlamaIndex, previously known as GPT Index, is a data framework tailored for large language model (LLM) applications. Its core purpose is to ingest, organize, and access private or domain-specific data, offering a suite of tools that simplify the integration of such data into LLMs.
Simply put, LLMs are very strong models but they don't work as well when used with smaller data bundles. LlamaIndex helps us in integrating our data into LLMS to serve specific needs.
LlamaIndex works using several components together. Let's take a look at them one by one.
Data Connectors
LlamaIndex supports ingesting data from multiple sources, such as APIs, PDFs, and SQL databases. These connectors streamline the process of integrating external data into LLM-based applications.
from llama_index.core import VectorStoreIndex, download_loader
from llama_index.readers.google import GoogleDocsReader
gdoc_ids = ["your-google_doc-id"]
loader = GoogleDocsReader()
documents = loader.load_data(document_ids=gdoc_ids)
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
query_engine.query("Where did the author go to school?")
This code uses LlamaIndex to load and query Google Docs. It imports necessary classes, specifies Google Doc IDs, and loads the document content using GoogleDocsReader. The content is then indexed as vectors with VectorStoreIndex, allowing for efficient querying. Finally, it creates a query engine to retrieve answers from the indexed documents based on natural language questions, such as "Where did the author go to school?"
Data Indexing
The framework organizes ingested data into intermediate formats designed to optimize how LLMs access and process information, ensuring both efficiency and performance.
Indexes are built from documents. They are used to build Query Engines and Chat Engines which enable question & answer and chat over the data. In LlamaIndex indexes store data in Node objects. According to the docs:
“A Node corresponds to a chunk of text from a Document. LlamaIndex takes in Document objects and internally parses/chunks them into Node objects.”
(Source)
Engines
LlamaIndex includes various engines for interacting with the data via natural language. These include engines for querying knowledge, facilitating conversational interactions, and data agents that enhance LLM-powered workflows.
Advantages of LlamaIndex
- Makes it easy to bring in data from different sources, such as APIs, PDFs, and databases like SQL/NoSQL, to be used in applications powered by large language models (LLMs).
- Lets you store and organize private data, making it ready for different uses, while smoothly working with vector stores and databases.
- Comes with a built-in query feature that allows you to get smart, data-driven answers based on your input.
LlamaIndex Quickstart
In this section, you’ll learn how to use LlamaIndex to create a queryable index from a collection of documents and interact with OpenAI’s API for querying purposes.
Now let’s break it down step by step:
@tab 1.
Install the LlamaIndex Package
pip install llama-index
You start by installing the llama-index package, which provides tools for building vector-based document indices that allow for natural language queries.
@tab 2.
Set the OpenAI API Key
env OPENAI_API_KEY = "your-api-key"
Here, the OpenAI API key is set as an environment variable to authenticate and allow communication with OpenAI’s API. Replace "your-api-key" with your actual API key.
@tab 3.
Importing Necessary Components
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
The VectorStoreIndex class is used to create an index that will store vectors representing the document contents, while the SimpleDirectoryReader class is used to read documents from a specified directory.
@tab 4.
Loading Documents
documents = SimpleDirectoryReader("data").load_data()
The SimpleDirectoryReader loads documents from the directory named "data". The load_data() method reads the contents and processes them so they can be used to create the index.
@tab 5.
Creating the Vector Store Index
index = VectorStoreIndex.from_documents(documents)
A VectorStoreIndex is created from the documents. This index converts the text into vector embeddings that capture the semantic meaning of the text, making it easier for AI models to interpret and query.
@tab 6.
Building the Query Engine
query_engine = index.as_query_engine()
The query engine is created by converting the vector store index into a format that can be queried. This engine is the component that allows you to run natural language queries against the document index.
@tab 7.
Querying the Engine
response = query_engine.query("Who is the protagonist in the story?")
Here, a query is made to the index asking for the protagonist of the story. The query engine processes the request and uses the document embeddings to retrieve the most relevant information from the indexed documents.
@tab 8.
Displaying the Response
Finally, the response from the query engine, which contains the answer to the query, is printed.
Make sure your directory structure looks like this:
main.py
data
Matilda.txt
NVIDIA NIM
Nvidia has recently launched their own set of tools for developing LLM applications called NIM. NIM stands for “Nvidia Inference Microservice”.
NVIDIA NIM is a collection of simple tools (microservices) that help quickly set up and run AI models on the cloud, in data centres, or on workstations.
NIMs are organized by model type. For instance, NVIDIA NIM for large language models (LLMs) makes it easy for businesses to use advanced language models for tasks like understanding and processing natural language.
How NIMs Work
When you first set up a NIM, it checks your hardware and finds the best version of the model from its library to match your system.
If you have certain NVIDIA GPUs (listed in the Support Matrix), NIM will download and use an optimized version of the model with the TRT-LLM library for fast performance. For other NVIDIA GPUs, it will download a non-optimized model and run it using the vLLM library.
So the main idea is to provide optimized AI models for faster local development and a cloud environment to host it for production.
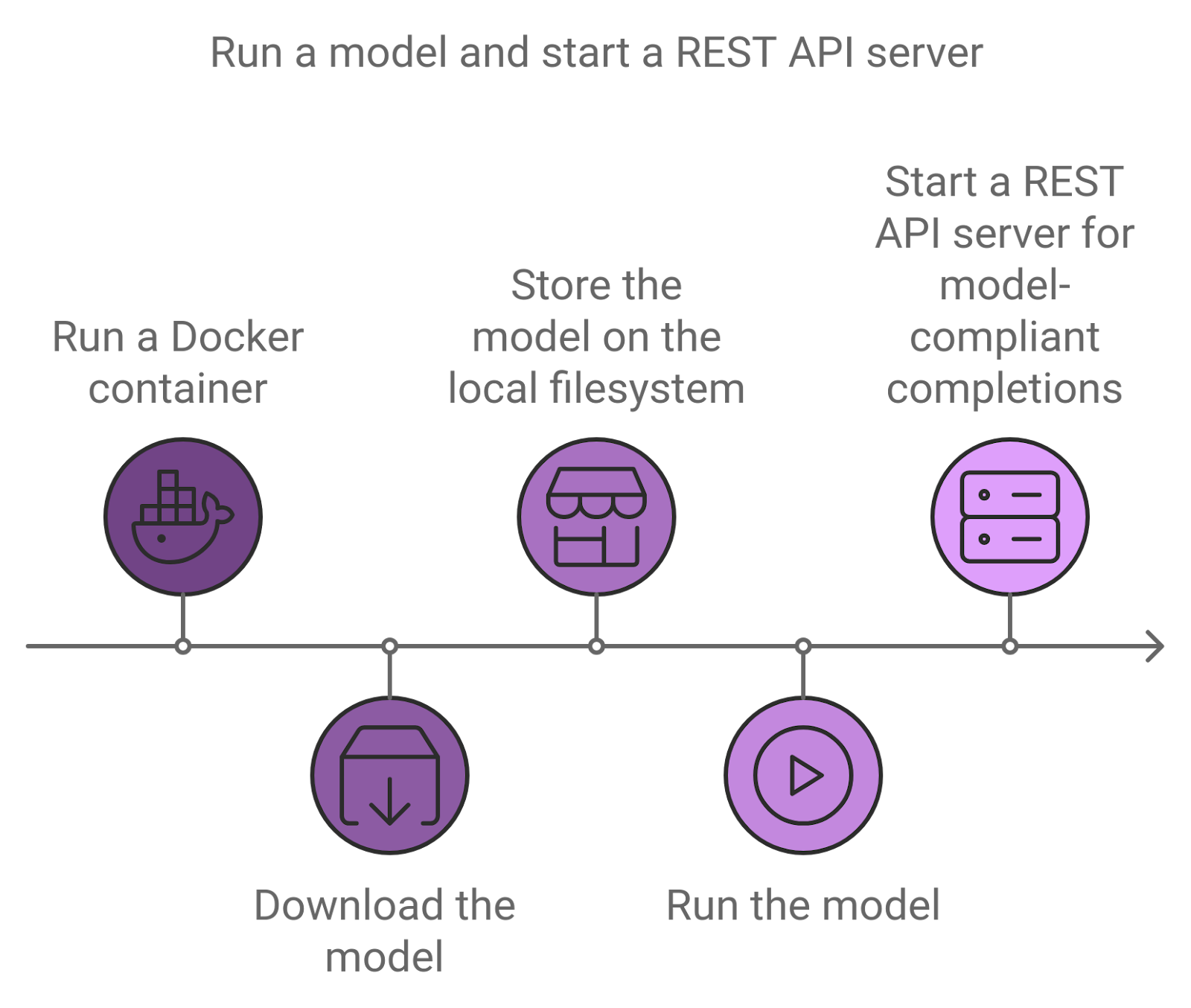
Features of NIM
NIM simplifies the process of running AI models by handling technical details like execution engines and runtime operations for you. It’s also the fastest option, whether using TRT-LLM, vLLM, or other methods.
NIM offers the following high-performance features:
- Scalable Deployment: It performs well and can easily grow from handling a few users to millions without issues.
- Advanced Language Model Support: NIM comes with pre-optimized engines for various of the latest language model designs.
- Flexible Integration: Adding NIM to your existing apps and workflows is easy. Developers can use an OpenAI API-compatible system with extra NVIDIA features for more capabilities.
- Enterprise-Grade Security: NIM prioritizes security by using safetensors, continuously monitoring for vulnerabilities (CVEs), and regularly applying security updates.
NIM Quickstart
Generate an NGC API key
An NGC API key is required to access NGC resources and a key can be generated here:
Export the API key
export NGC_API_KEY=<value>
Docker login to NGC
To pull the NIM container image from NGC, first authenticate with the NVIDIA Container Registry with the following command:
echo "$NGC_API_KEY" | docker login nvcr.io --username '$oauthtoken' --password-stdin
List available NIMs
ngc registry image list --format_type csv nvcr.io/nim/*
Launch NIM
The following command launches a Docker container for the llama3-8b-instruct model. To launch a container for a different NIM, replace the values of Repository and Latest_Tag with values from the previous image list command and change the value of CONTAINER_NAME to something appropriate.
# Choose a container name for bookkeeping
export CONTAINER_NAME=Llama3-8B-Instruct
# The container name from the previous ngc registgry image list command
Repository=nim/meta/llama3-8b-instruct
Latest_Tag=1.1.2
# Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/${Repository}:${Latest_Tag}"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
# Start the LLM NIM
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY=$NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME
Usecase: OpenAI Completion Request
from openai import OpenAI
client = OpenAI(base_url="http://0.0.0.0:8000/v1", api_key="not-used")
prompt = "Once upon a time"
response = client.completions.create(
model="meta/llama3-8b-instruct",
prompt=prompt,
max_tokens=16,
stream=False
)
completion = response.choices[0].text
print(completion)
Which Tool to Use?
So you may be wondering: which of these should you use for your specific use case? Well, the answer to this depends on what you’re working on.
LangChain is an excellent choice if you're looking for a versatile framework to integrate multiple tools or build intelligent agents that can handle several tasks simultaneously.
But if your main focus is smart search and data retrieval, LlamaIndex is the better option, as it specializes in indexing and retrieving information for LLMs, making it ideal for deep data exploration. While LangChain can manage indexing and retrieval, LlamaIndex is optimized for these tasks and offers easier data ingestion with its plugins and connectors.
On the other hand, if you're aiming for high-performance model deployment, NVIDIA NIM is a great solution. NIM abstracts the technical details, offers fast inference with tools like TRT-LLM and vLLM, and provides scalable deployment with enterprise-grade security.
So, for apps needing indexing and retrieval, LlamaIndex is recommended. For deploying LLMs at scale, NIM is a powerful choice. Otherwise, LangChain alone is sufficient for working with LLMs.
Conclusion
In this article, we compared three powerful tools for working with large language models: LangChain, LlamaIndex, and NVIDIA NIM. We explored each tool’s unique strengths, such as LangChain's versatility for integrating multiple components, LlamaIndex's focus on efficient data indexing and retrieval, and NVIDIA NIM's high-performance model deployment capabilities.
We discussed key features like scalability, ease of integration, and optimized performance, showing how these tools address different needs within the AI ecosystem.
While each tool has its challenges, such as handling complex infrastructures or optimizing for specific tasks, LangChain, LlamaIndex, and NVIDIA NIM offer valuable solutions for building and scaling AI-powered applications.